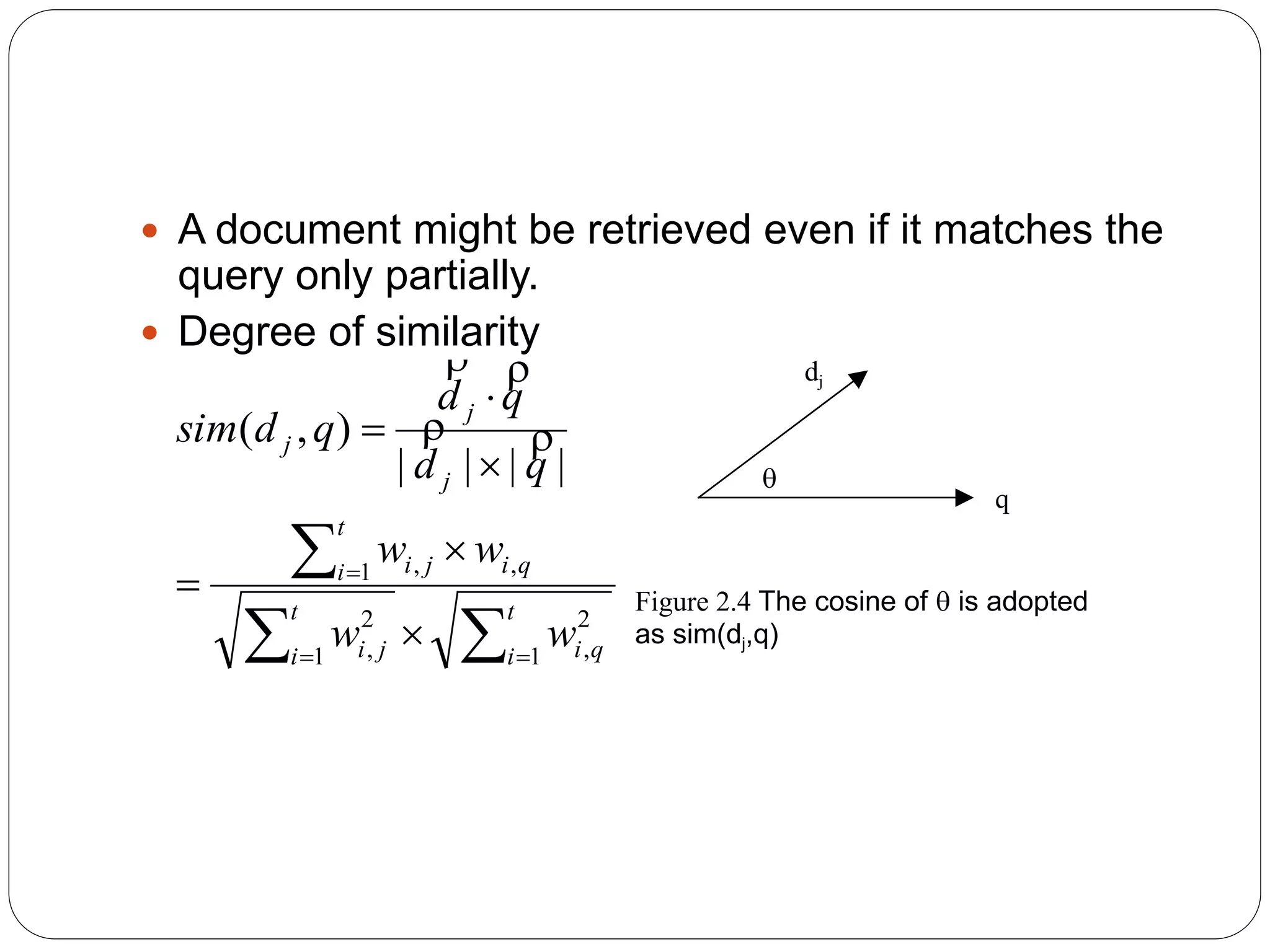
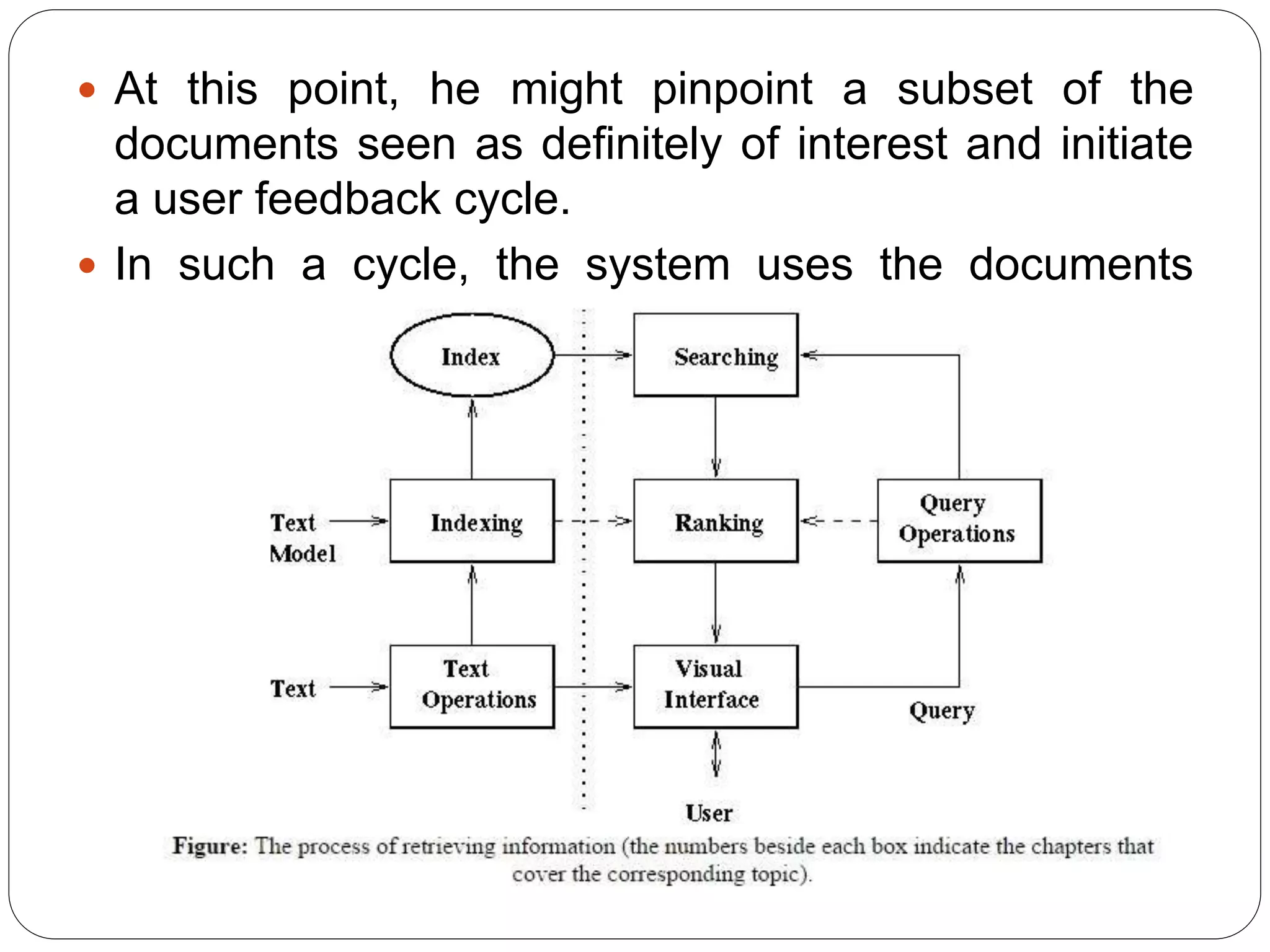
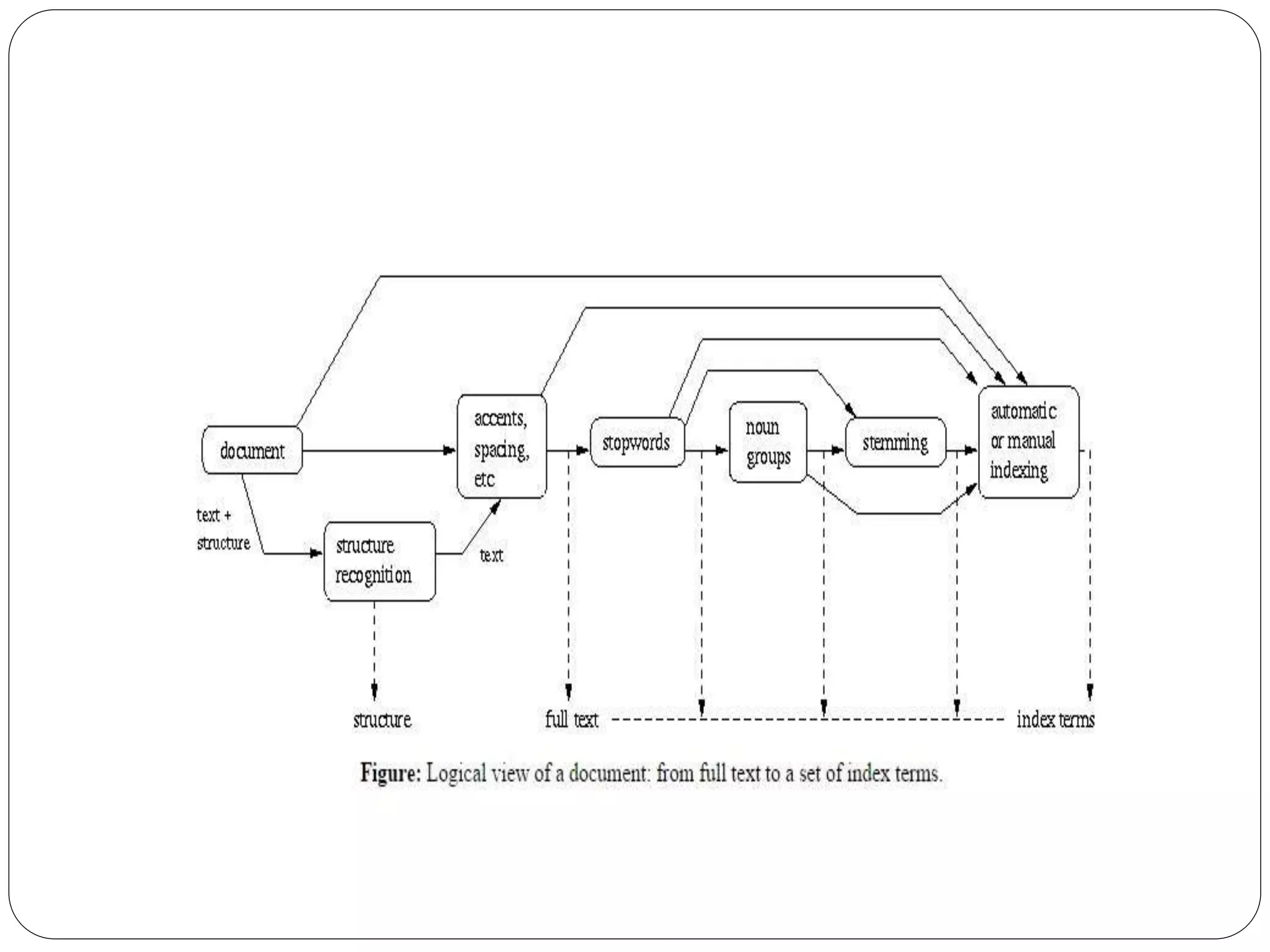
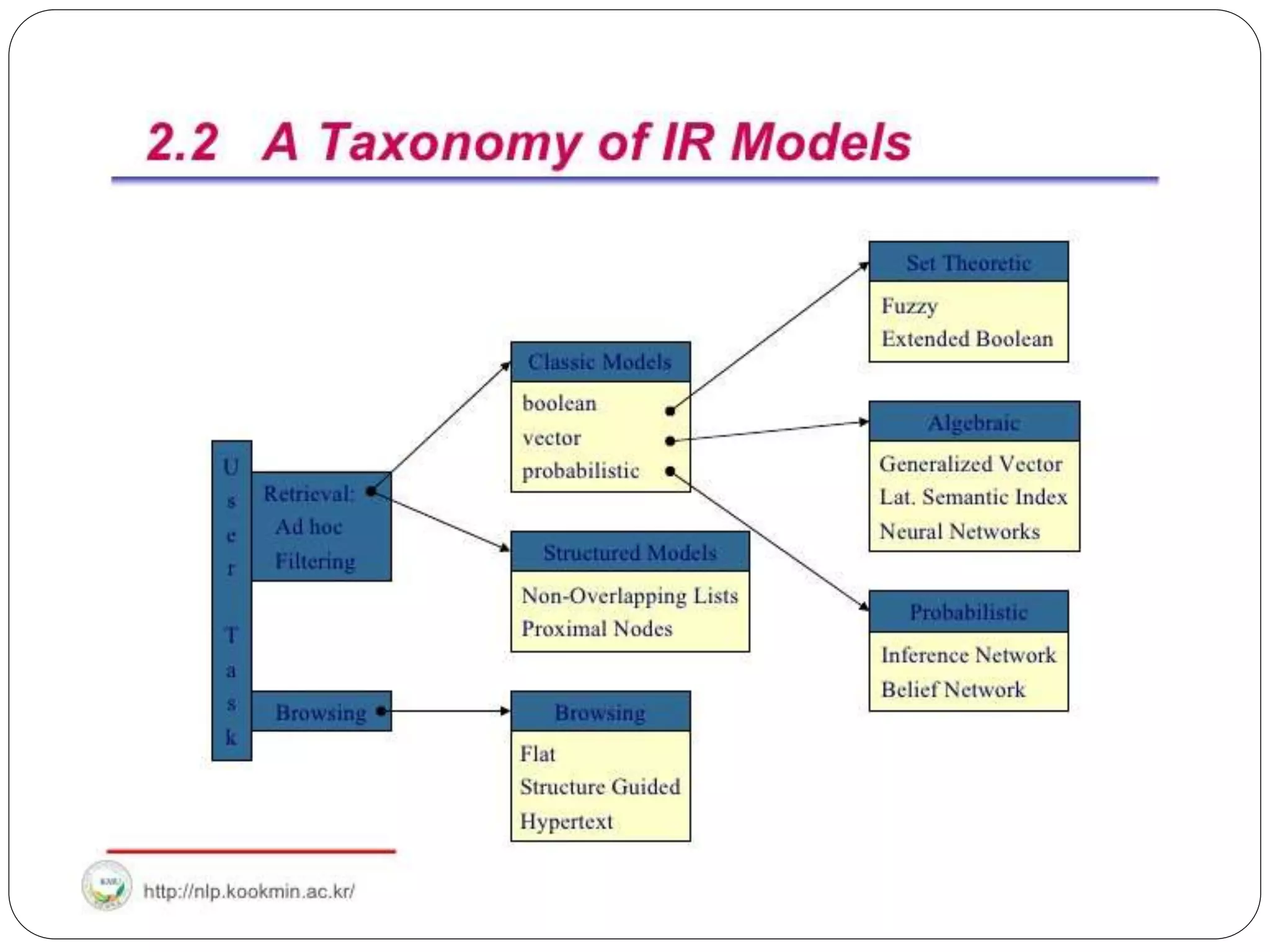
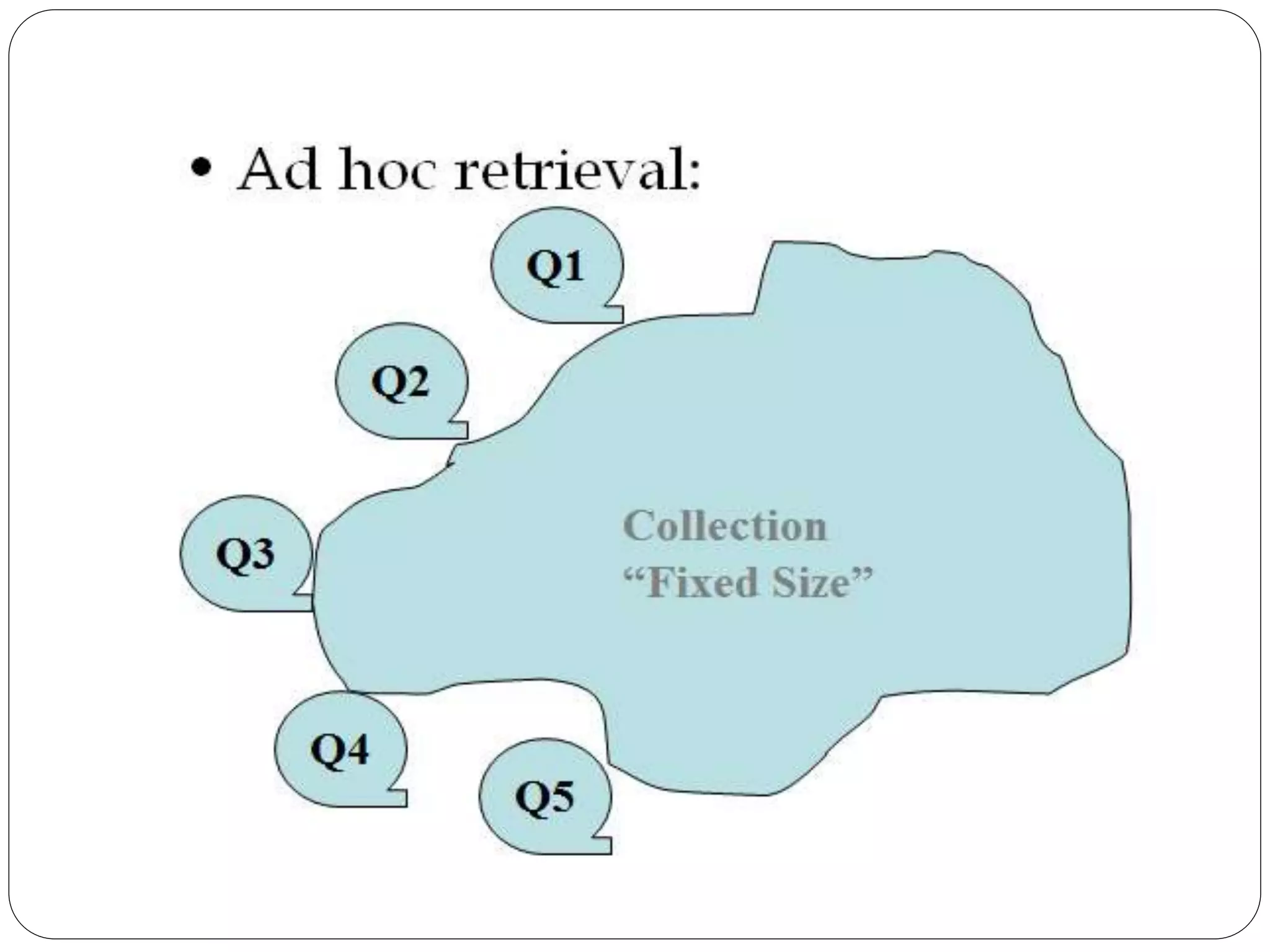
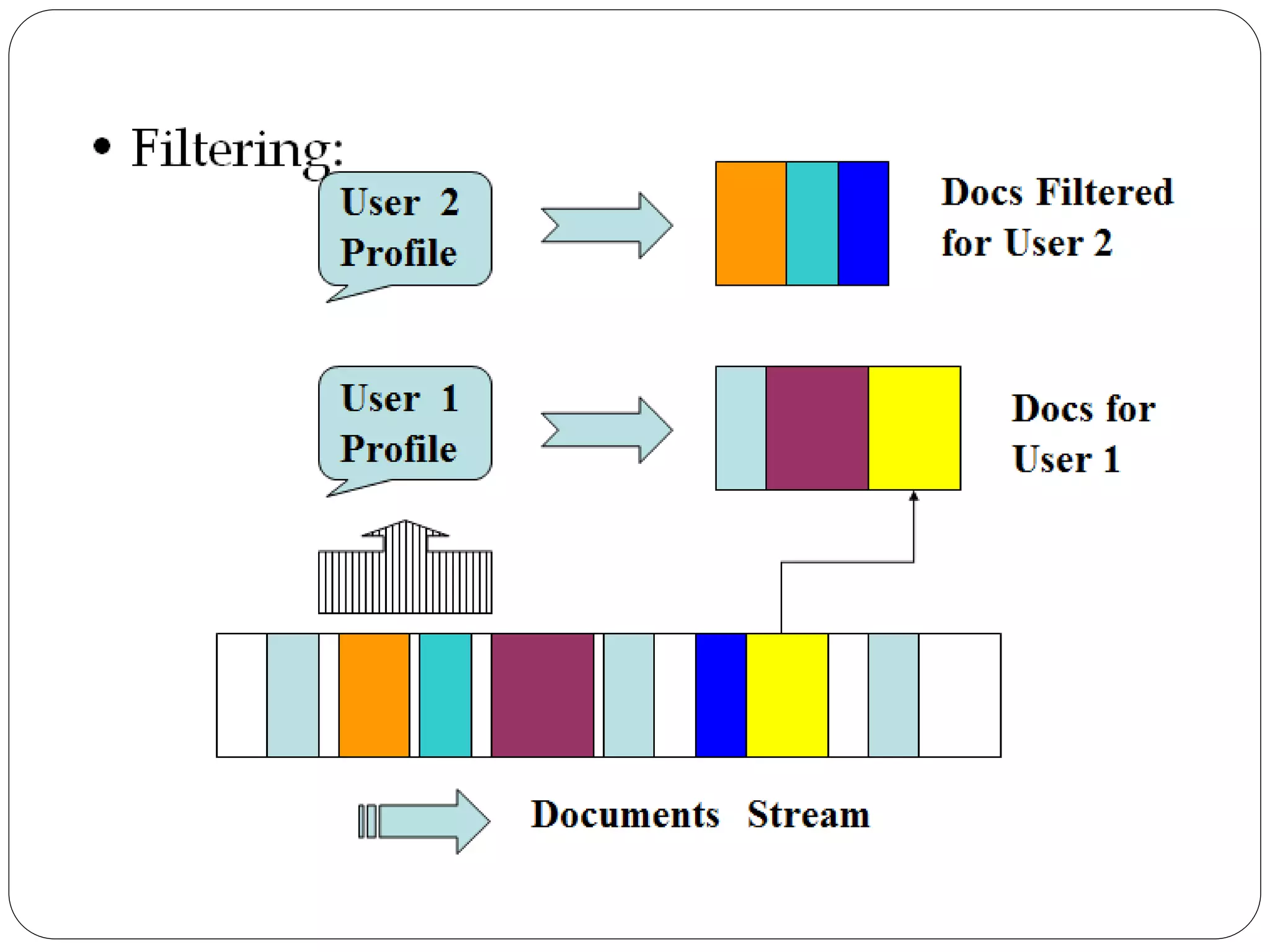
This document provides an overview of information retrieval models. It begins with definitions of information retrieval and how it differs from data retrieval. It then discusses the retrieval process and logical representations of documents. A taxonomy of IR models is presented including classic, structured, and browsing models. Boolean, vector, and probabilistic models are explained as examples of classic models. The document concludes with descriptions of ad-hoc retrieval and filtering tasks and formal characteristics of IR models.



















![Formal characterization of IR models
An IR model is a quadruple [D, Q, F, R(qi, dj)] where
1. D is a set of logical views for the documents in the
collection
2. Q is a set of logical views for the user queries
3. F is a framework for modeling documents and
queries
4. R(qi, dj) is a ranking function](https://image.slidesharecdn.com/informationretrievalintro-170614051327/75/Information-retrieval-introduction-25-2048.jpg)