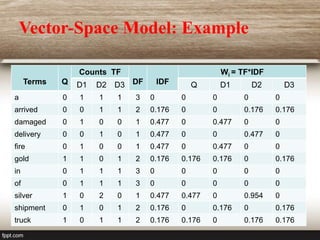
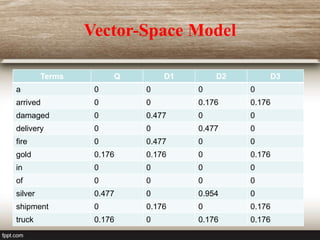
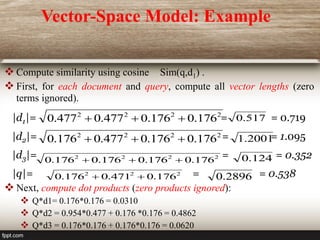
The document discusses the vector space model used in information retrieval. It explains that documents and queries are represented as weighted vectors in a multidimensional space. Similar vectors are close to each other. The weights used are usually tf-idf, which considers both the frequency of a term within a document and its rarity across documents. Documents are ranked based on the similarity between their vector representation and the query vector.





















![Query:
Users query is typically treated as a document and also tf-idf weighted.
For the query term weights, a suggestion is:
wiq = (0.5 + [0.5 * freq(i,q) / max(freq(k,q)]) * log(N/ni)
The vector space model with tf*idf weights is a good ranking strategy
with general collections,
The vector space model is usually as good as the known ranking
alternatives.
It is also simple and fast to compute.
Computing Weights](https://image.slidesharecdn.com/4-irmodelsnew-231020063356-630054da/85/4-IR-Models_new-ppt-22-320.jpg)




![Vector Space with Term Weights
and Cosine Matching
1.0
0.8
0.6
0.4
0.2
0.8
0.6
0.4
0.2
0 1.0
D2
D1
Q
1
2
Term B
Term A
Di=(di1,wdi1;di2, wdi2;…;dit, wdit)
Q =(qi1,wqi1;qi2, wqi2;…;qit, wqit)
t
j
t
j d
q
t
j d
q
i
ij
j
ij
j
w
w
w
w
D
Q
sim
1 1
2
2
1
)
(
)
(
)
,
(
Q = (0.4,0.8)
D1=(0.8,0.3)
D2=(0.2,0.7)
98
.
0
42
.
0
64
.
0
]
)
7
.
0
(
)
2
.
0
[(
]
)
8
.
0
(
)
4
.
0
[(
)
7
.
0
8
.
0
(
)
2
.
0
4
.
0
(
)
2
,
(
2
2
2
2
D
Q
sim
74
.
0
58
.
0
56
.
)
,
( 1
D
Q
sim](https://image.slidesharecdn.com/4-irmodelsnew-231020063356-630054da/85/4-IR-Models_new-ppt-27-320.jpg)