Downloaded 27 times




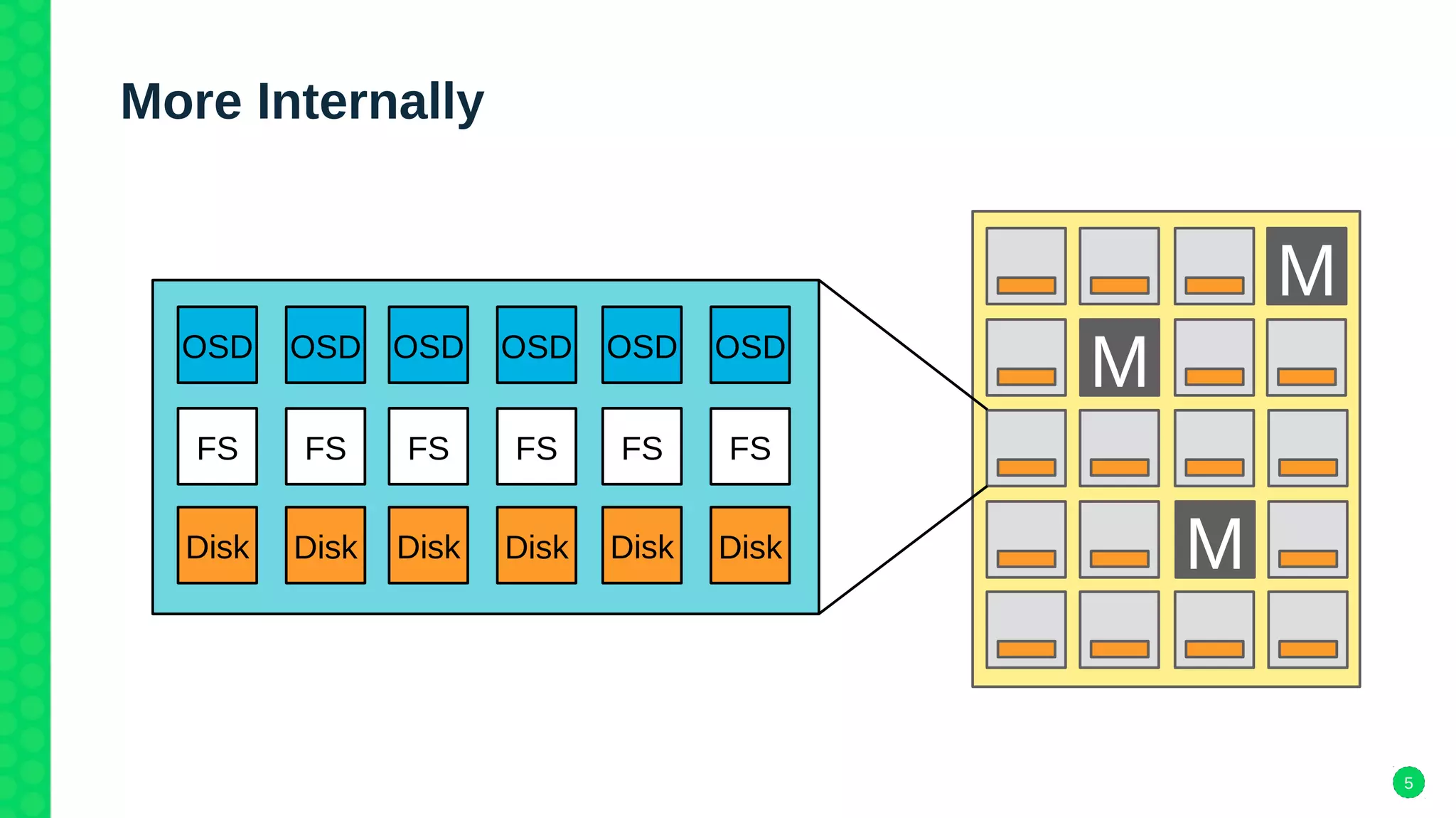







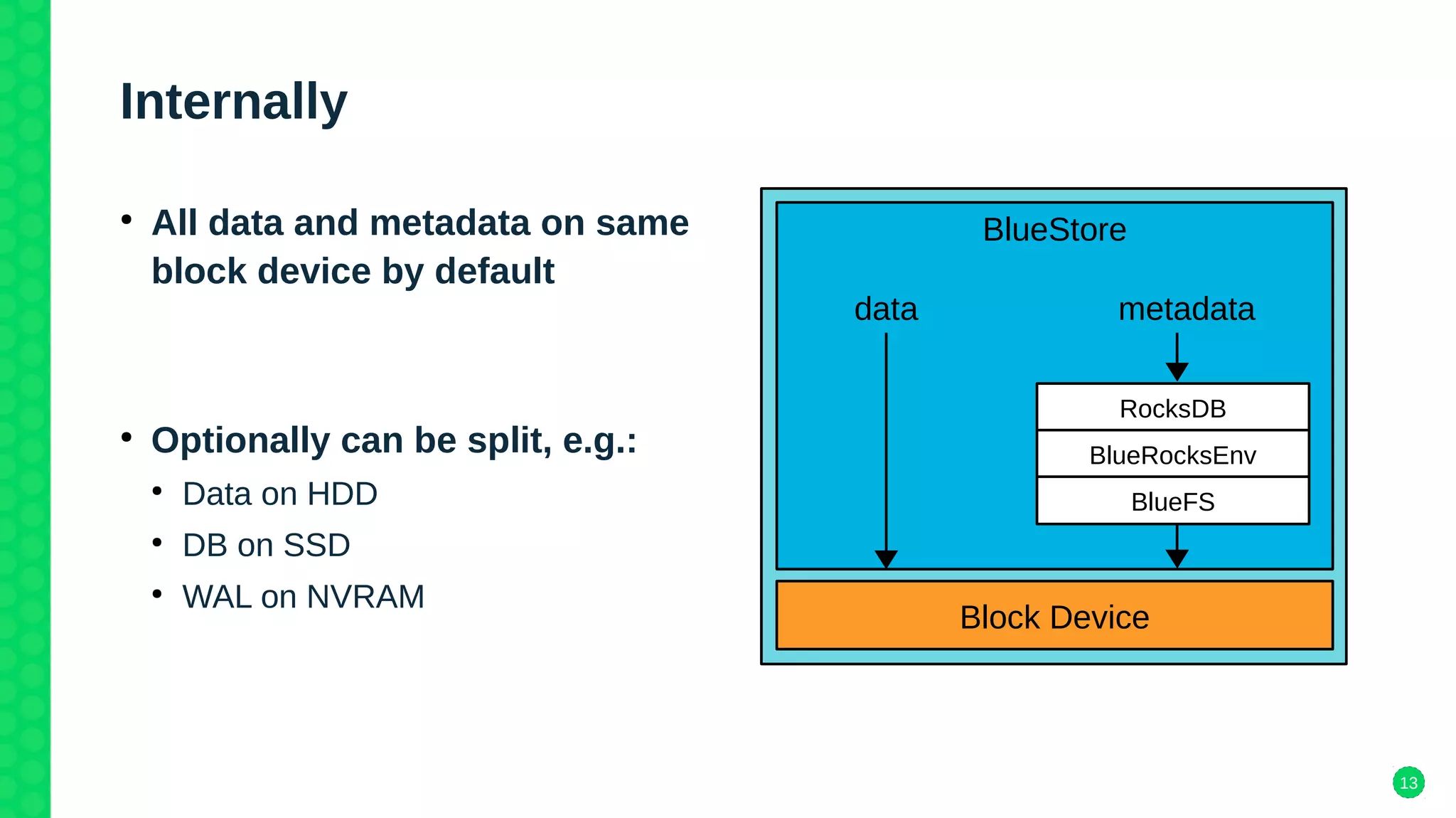









The document discusses Ceph's new storage backend, Bluestore, which addresses performance issues with the older Filestore by utilizing raw block devices and a RocksDB key/value store, resulting in a 2-3x performance boost. It details the architecture of both storage backends, their respective advantages, and migration strategies from Filestore to Bluestore. The document also highlights compatibility with existing Ceph features and plans for deployment in future versions.























































































