Downloaded 451 times



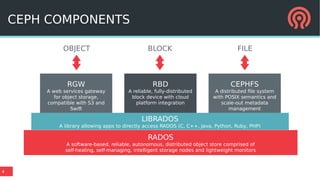
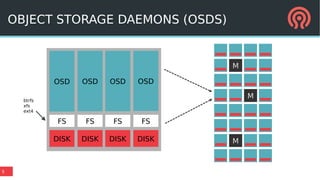
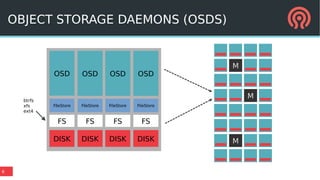




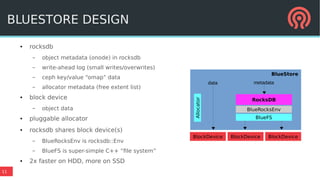









The document discusses the Ceph storage system, highlighting its capabilities for object, block, and file storage, while addressing the shortcomings of traditional POSIX storage. It introduces the new Bluestore backend utilizing RocksDB for efficient metadata management, journal recycling, and better performance. Additionally, it emphasizes the importance of avoiding POSIX interfaces due to their limitations in handling distributed data effectively.








![[OpenStack Days Korea 2016] Track1 - All flash CEPH 구성 및 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/12skt-160226171513-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)





































































