Downloaded 19 times
































![Issues
43
root@SSCloud-01:/# cephfs /mnt/dev set_layout -p 5
Segmentation fault
cephfs is not a super-friendly tool right now — sorry! :(
I believe you will find it works correctly if you specify all the layout parameters,
not just one of them.
root@SSCloud-01:/# cephfs -h
not enough parameters!
usage: cephfs path command [options]*
Commands:
show_layout -- view the layout information on a file or dir
set_layout -- set the layout on an empty file, or the default layout on a directory
show_location -- view the location information on a file
map -- display file objects, pgs, osds
Options:
Useful for setting layouts:
--stripe_unit, -u: set the size of each stripe
--stripe_count, -c: set the number of objects to stripe across
--object_size, -s: set the size of the objects to stripe across
--pool, -p: set the pool to use
Useful for getting location data:
--offset, -l: the offset to retrieve location data for
root@SSCloud-01:/# cephfs /mnt/dev set_layout -u 4194304 -c 1 -s 4194304 -p 5
root@SSCloud-01:/# cephfs /mnt/dev show_layout
layout.data_pool: 5
layout.object_size: 4194304
layout.stripe_unit: 4194304
layout.stripe_count: 1](https://image.slidesharecdn.com/dfsiniaas-130905090952-/85/Dfs-in-iaa_s-43-320.jpg)



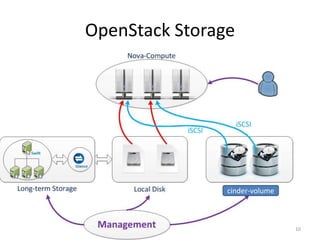
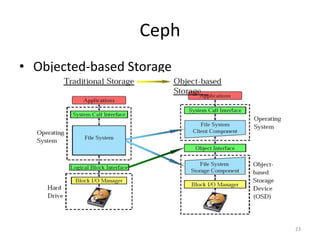
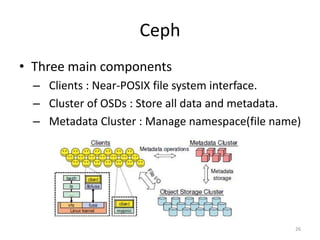
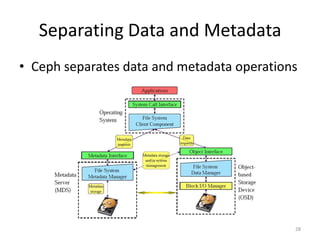
Ceph is a distributed file system that provides excellent performance, reliability and scalability for IaaS platforms like OpenStack. It uses an object-based storage model with dynamic distributed metadata management and reliable replication to store data across multiple servers. While CephFS for POSIX file access is still maturing, Ceph block storage via RBD is stable and commonly used in IaaS to provide block-level volumes to VMs from images stored in Ceph.





























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





