Downloaded 797 times







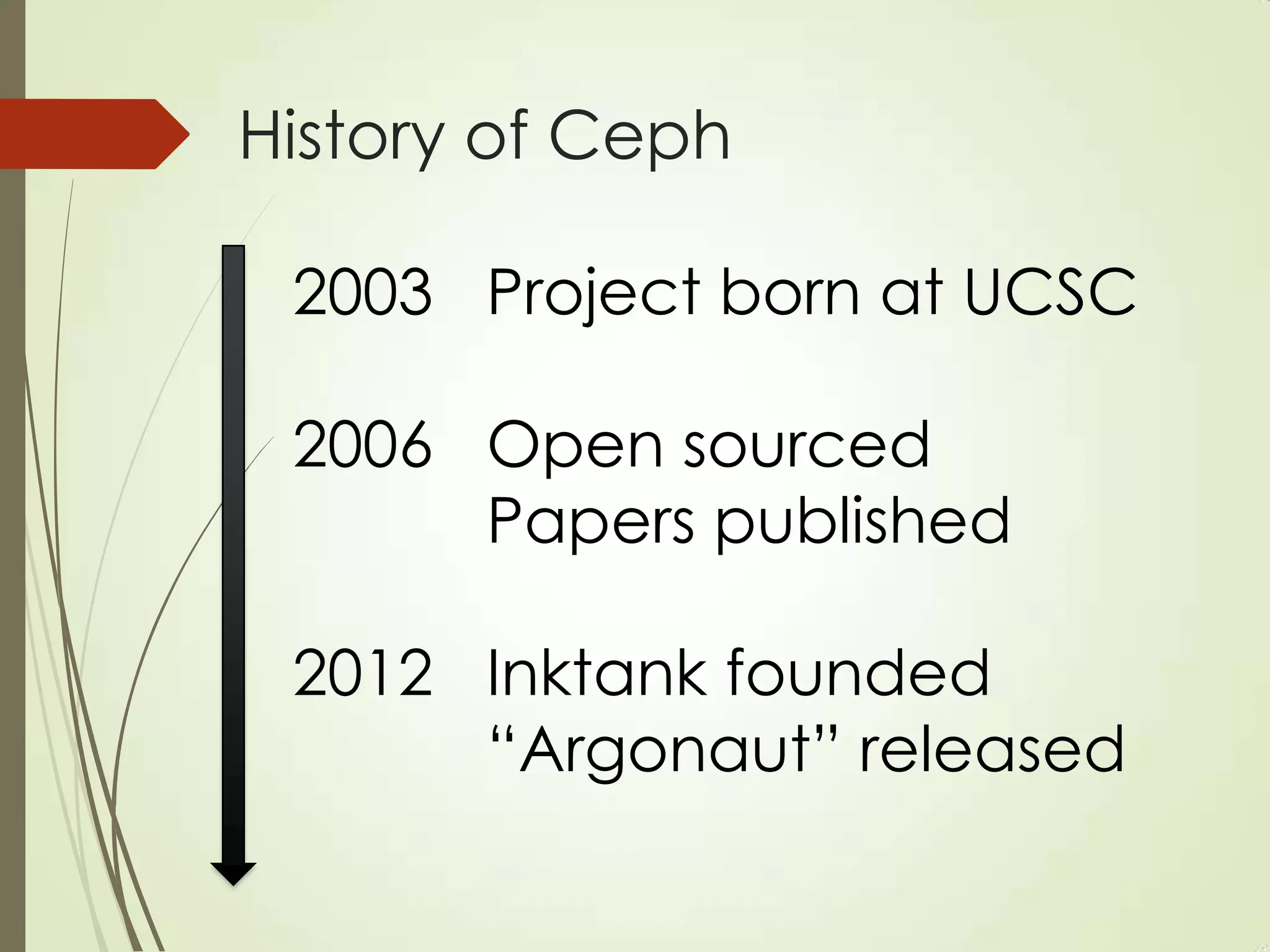




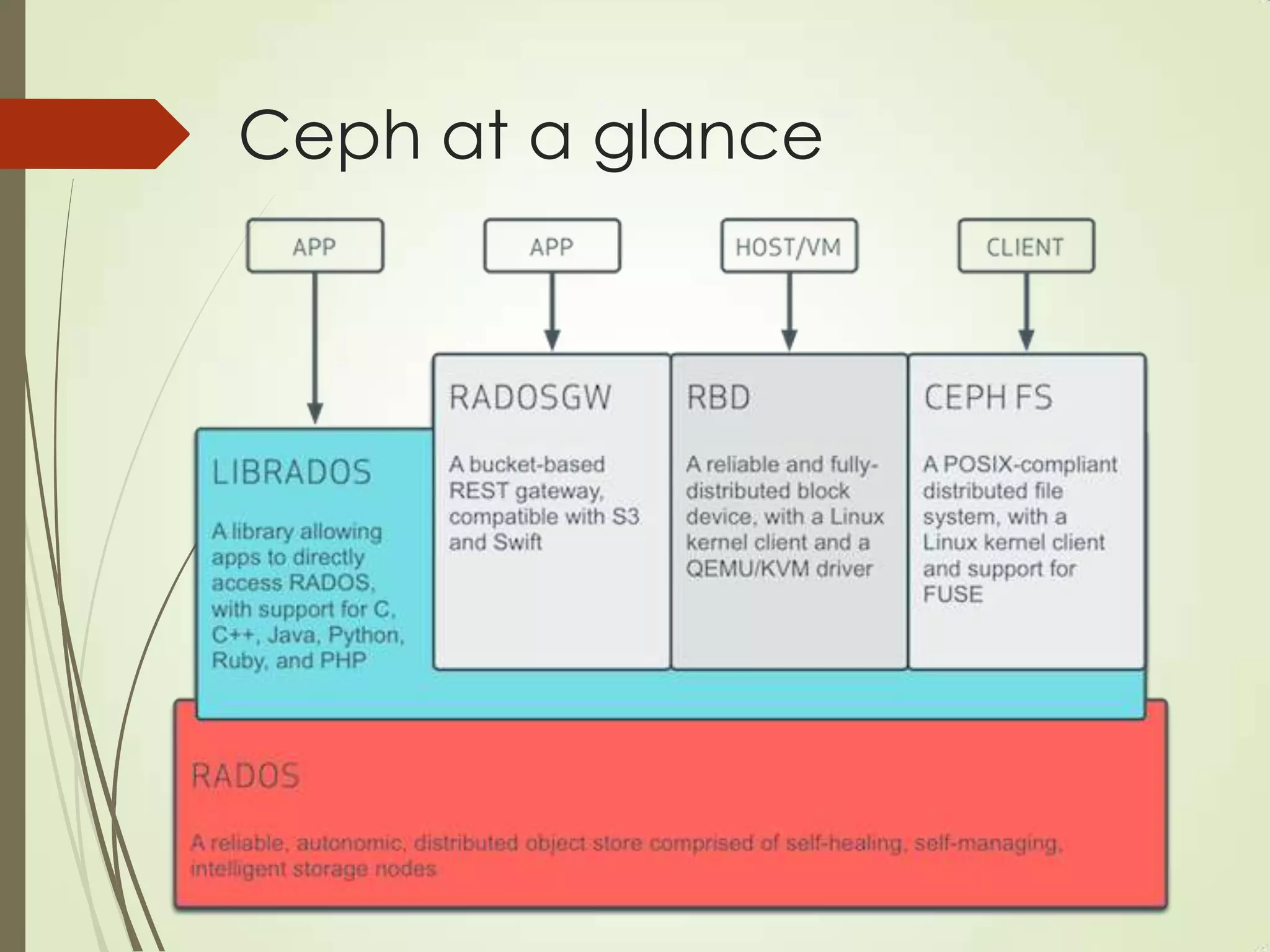
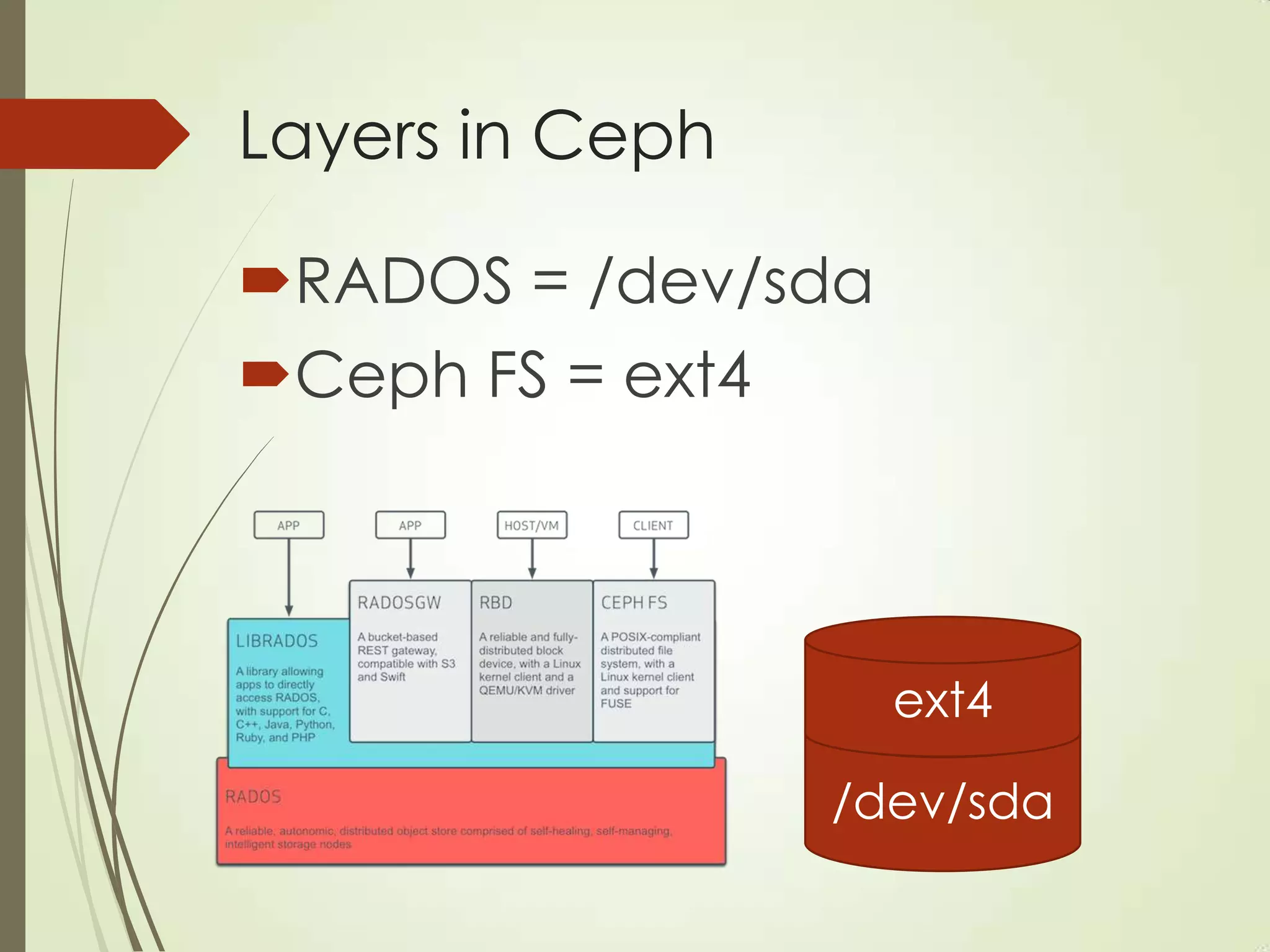



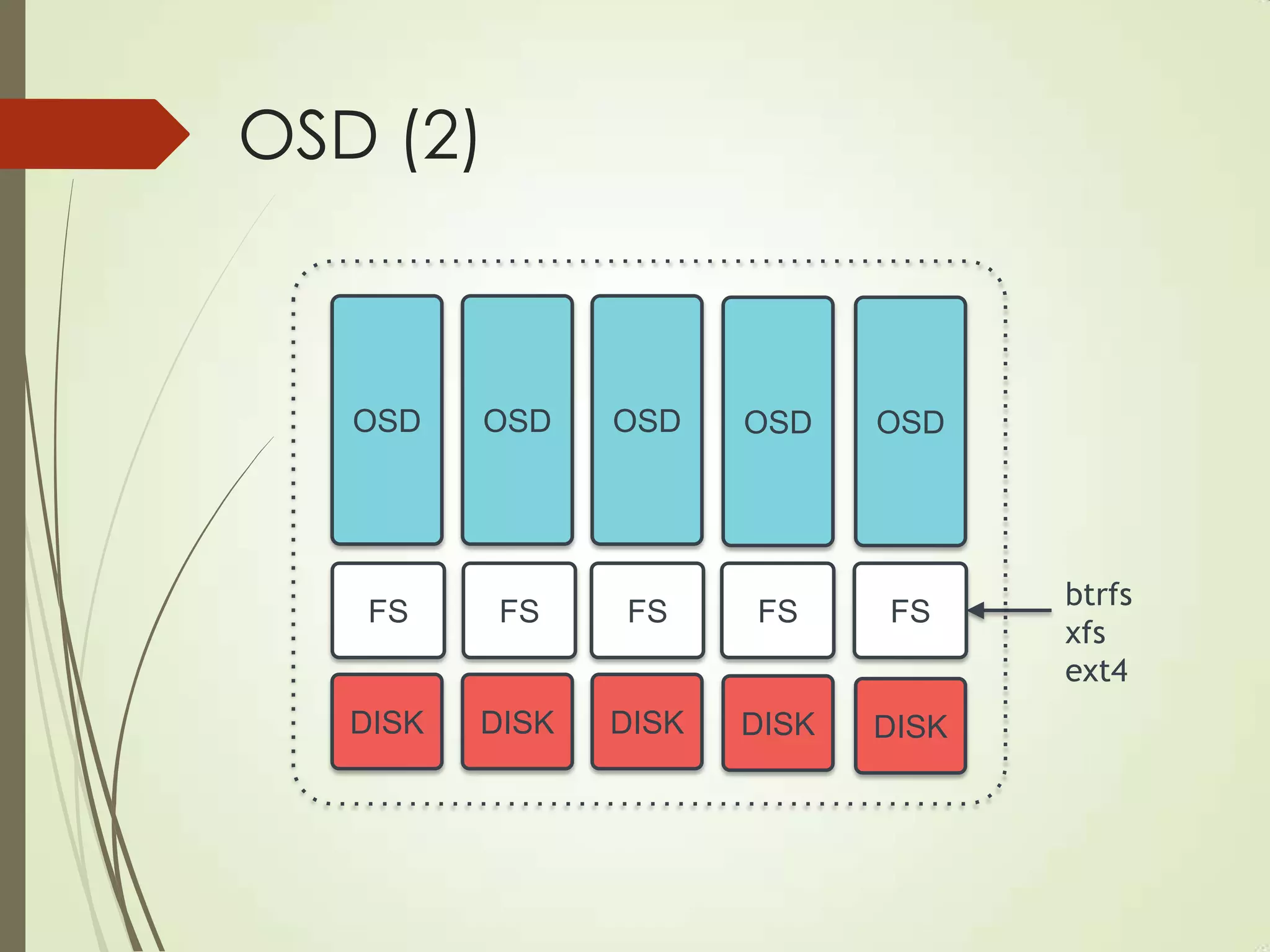


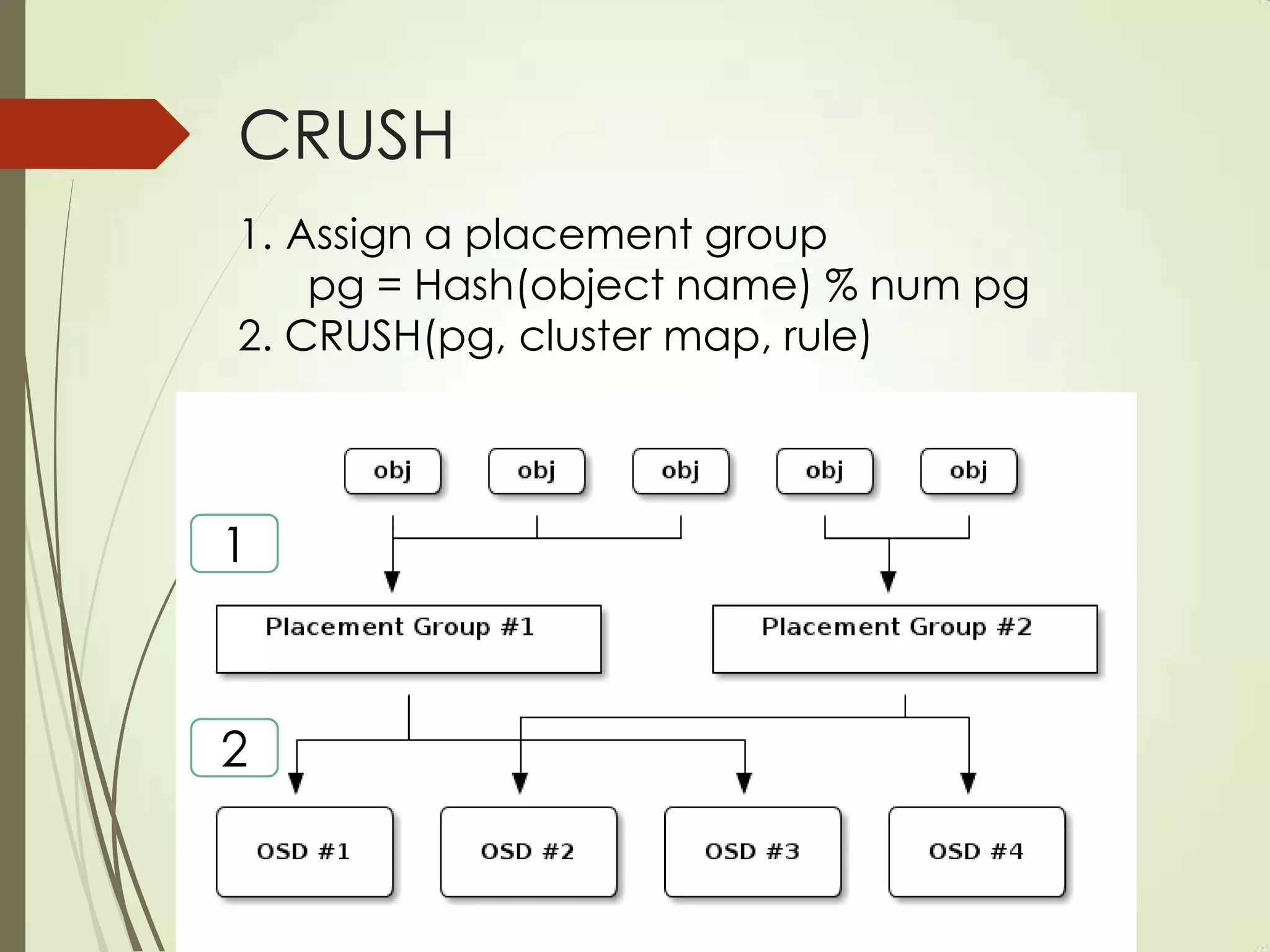
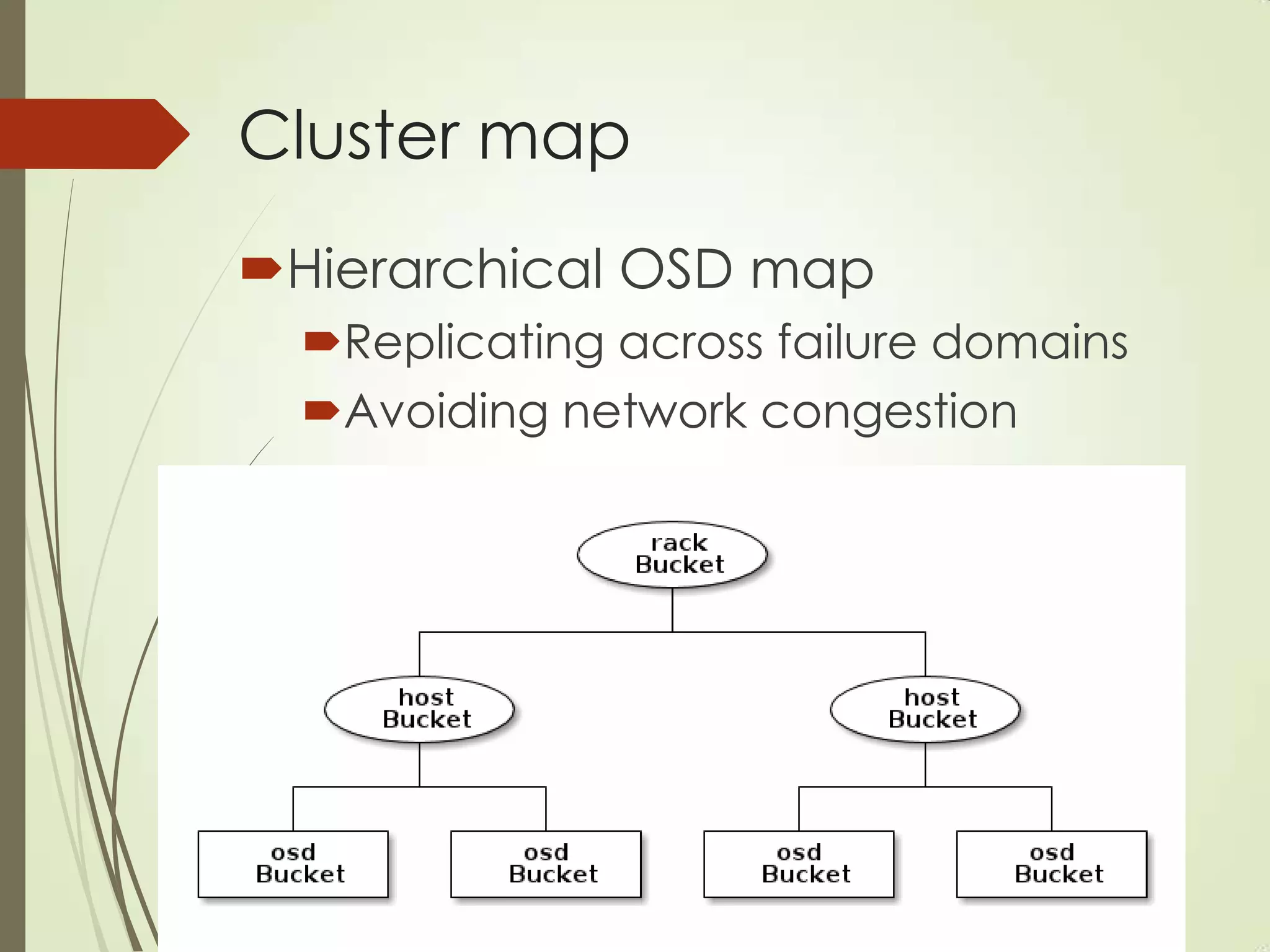

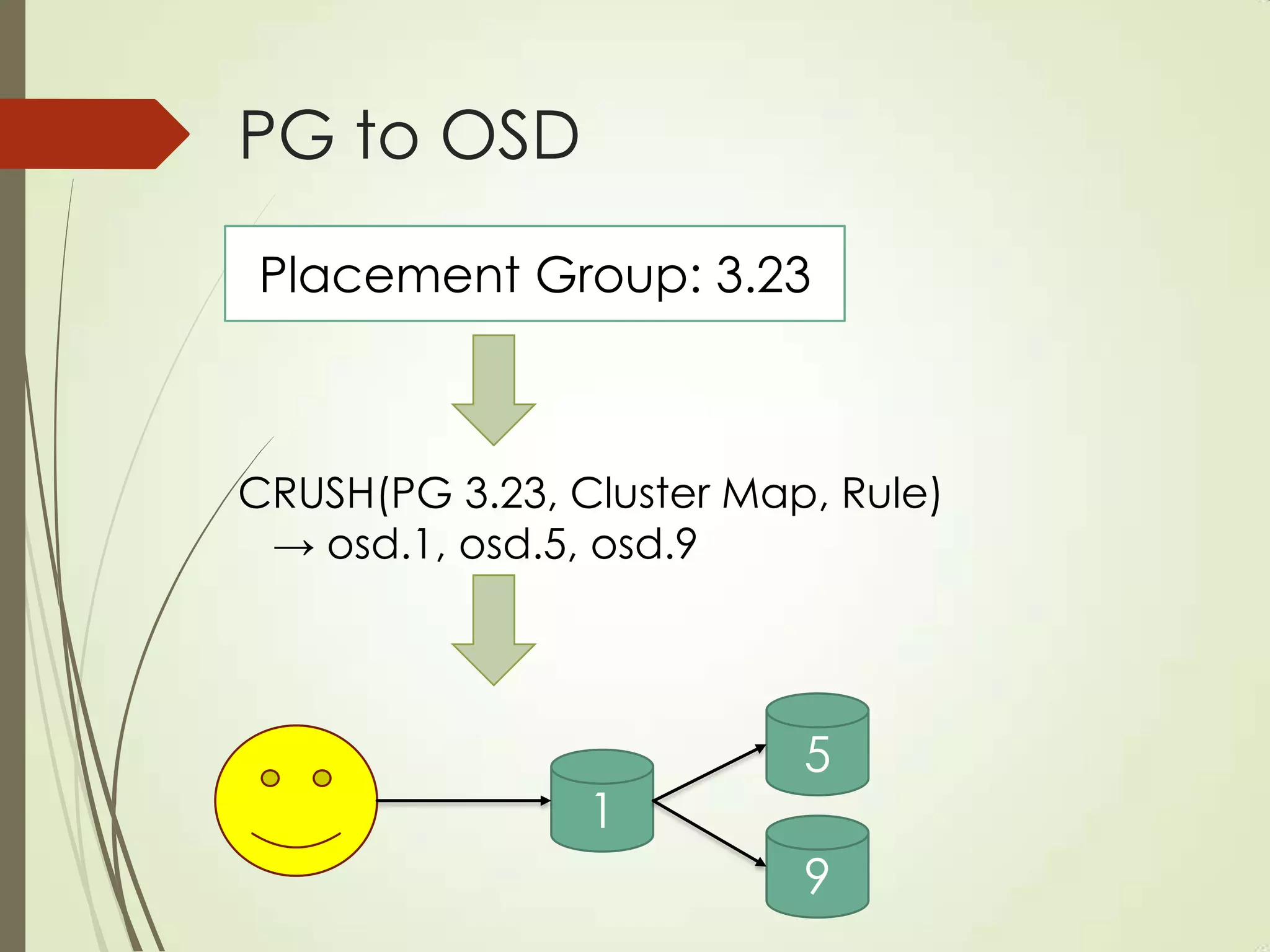



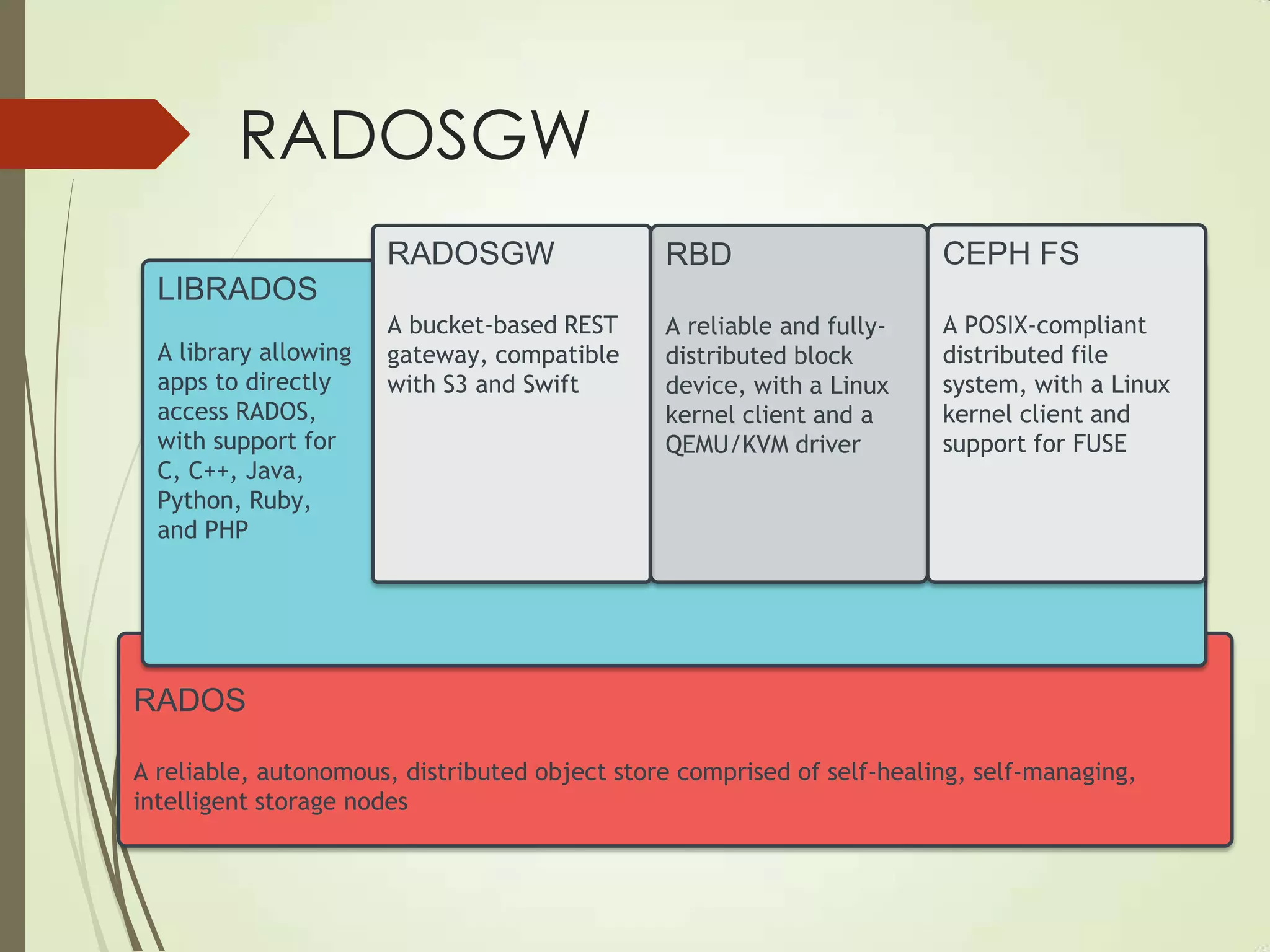
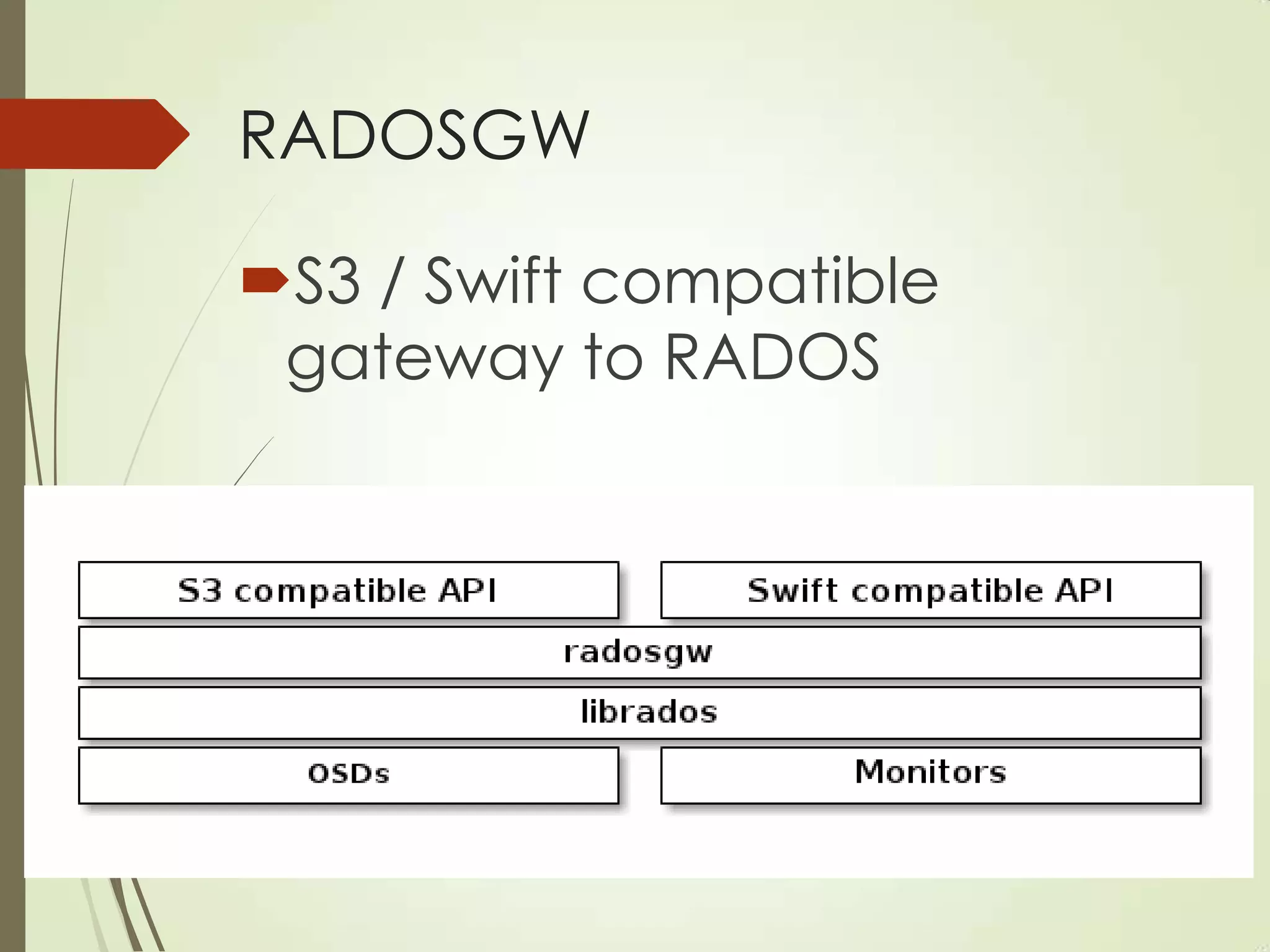



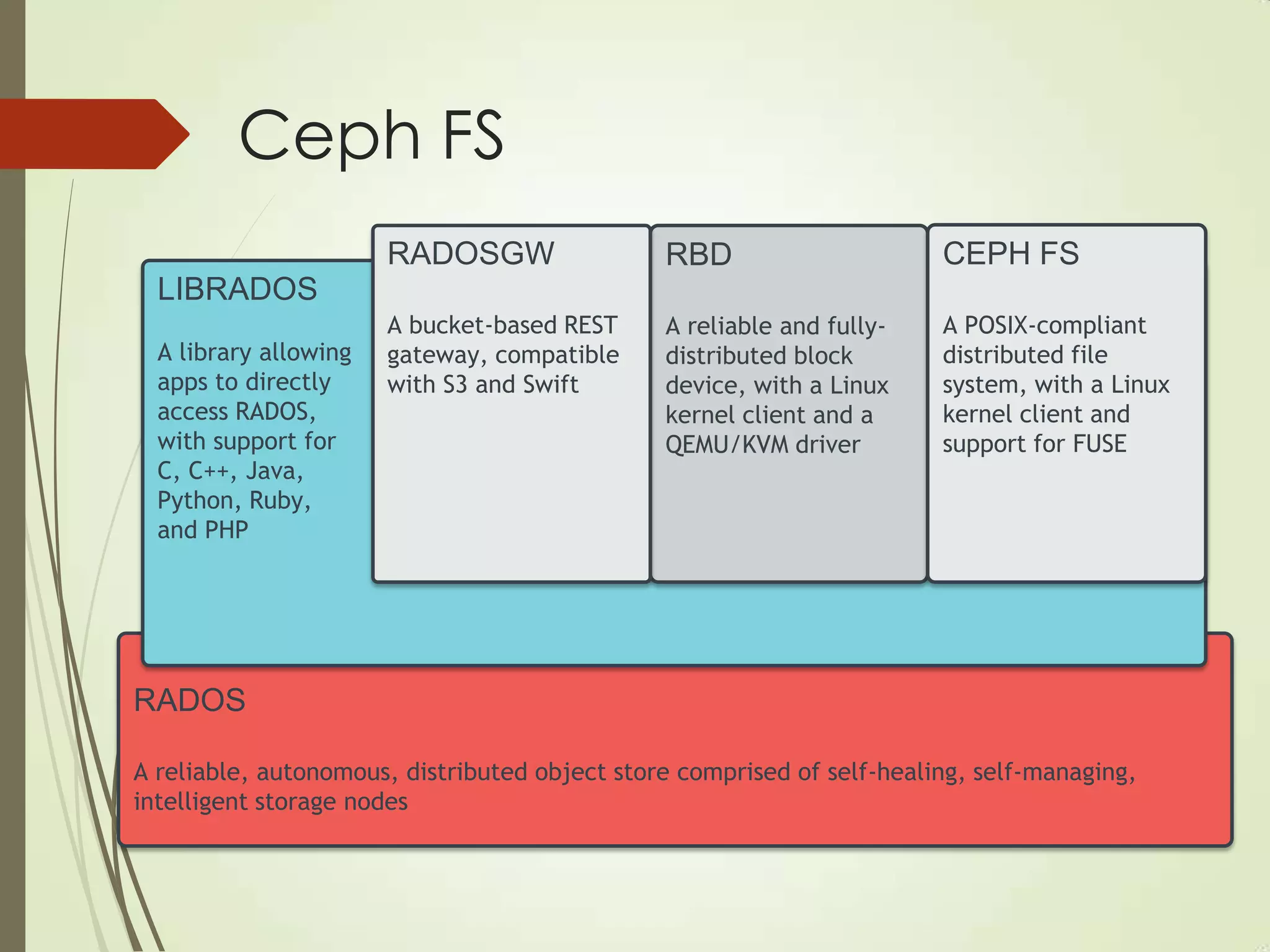


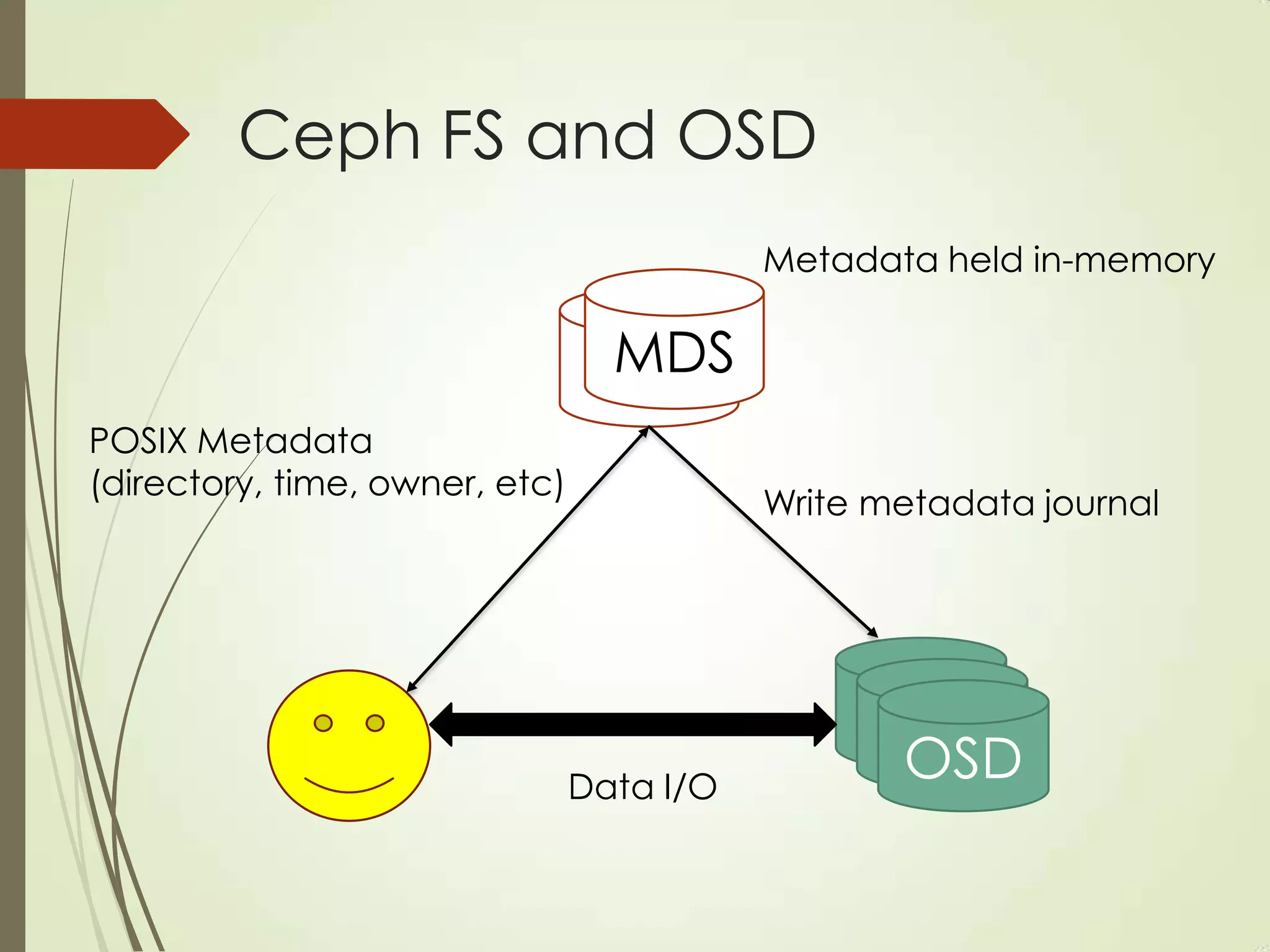
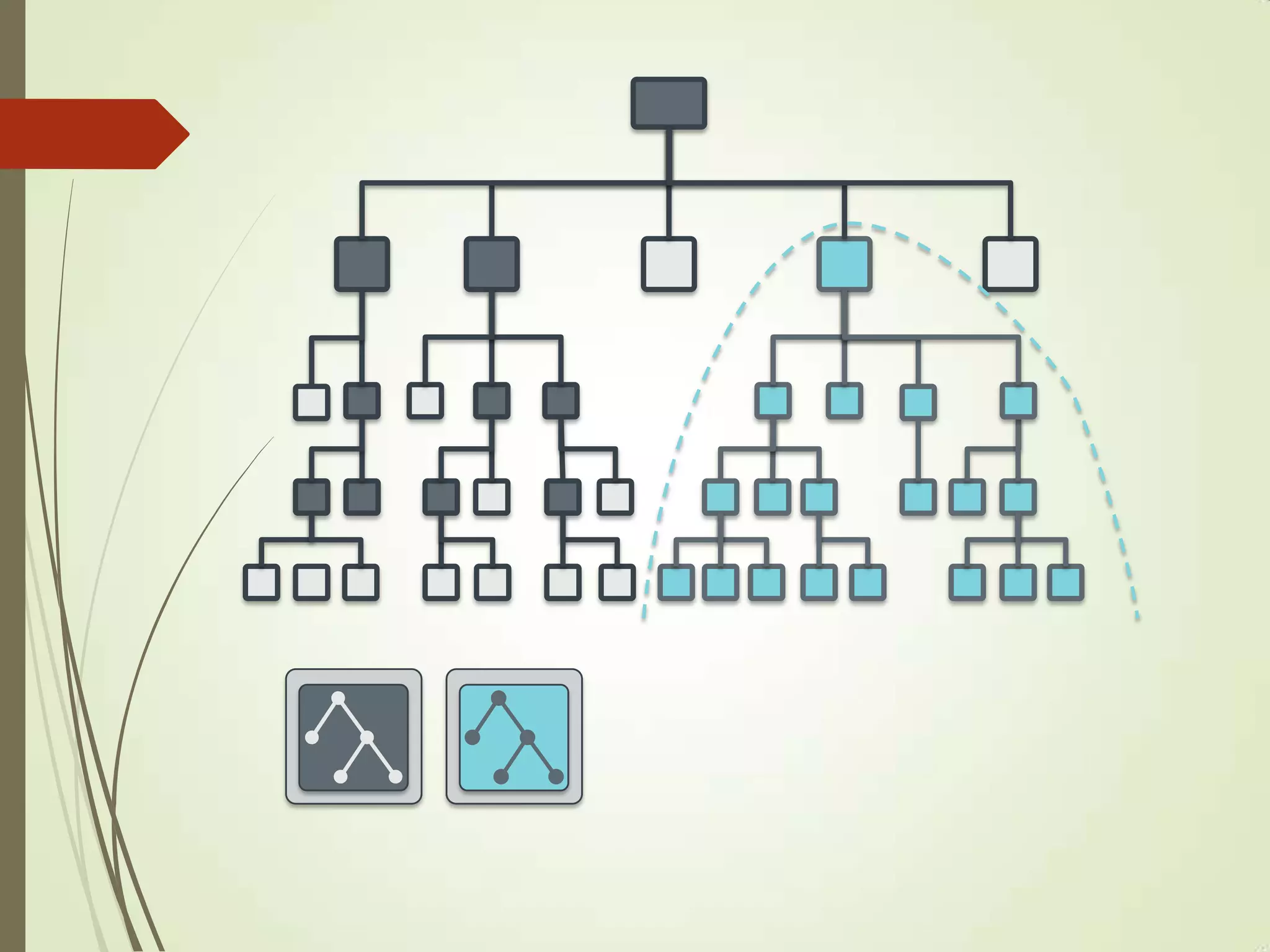
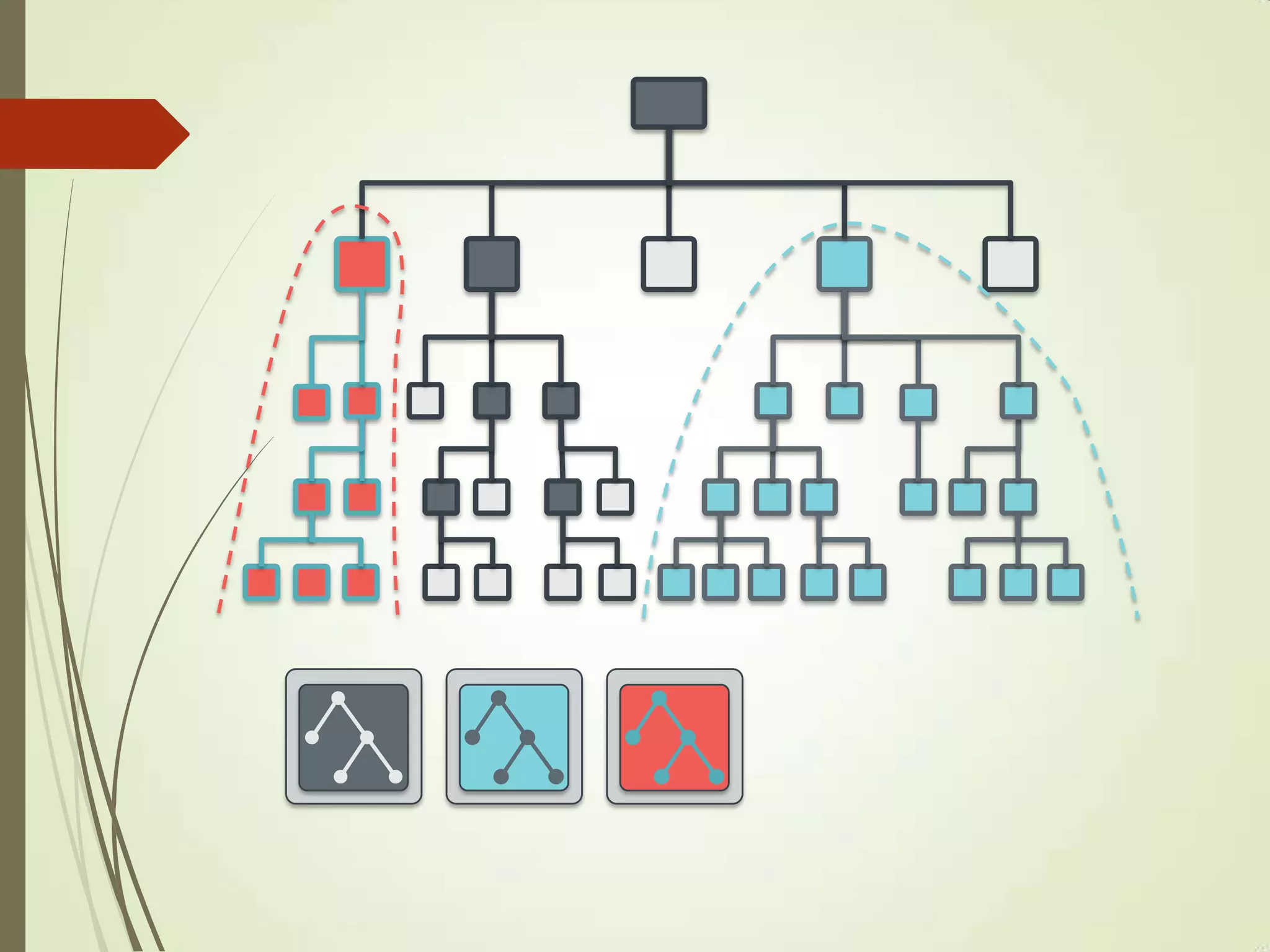
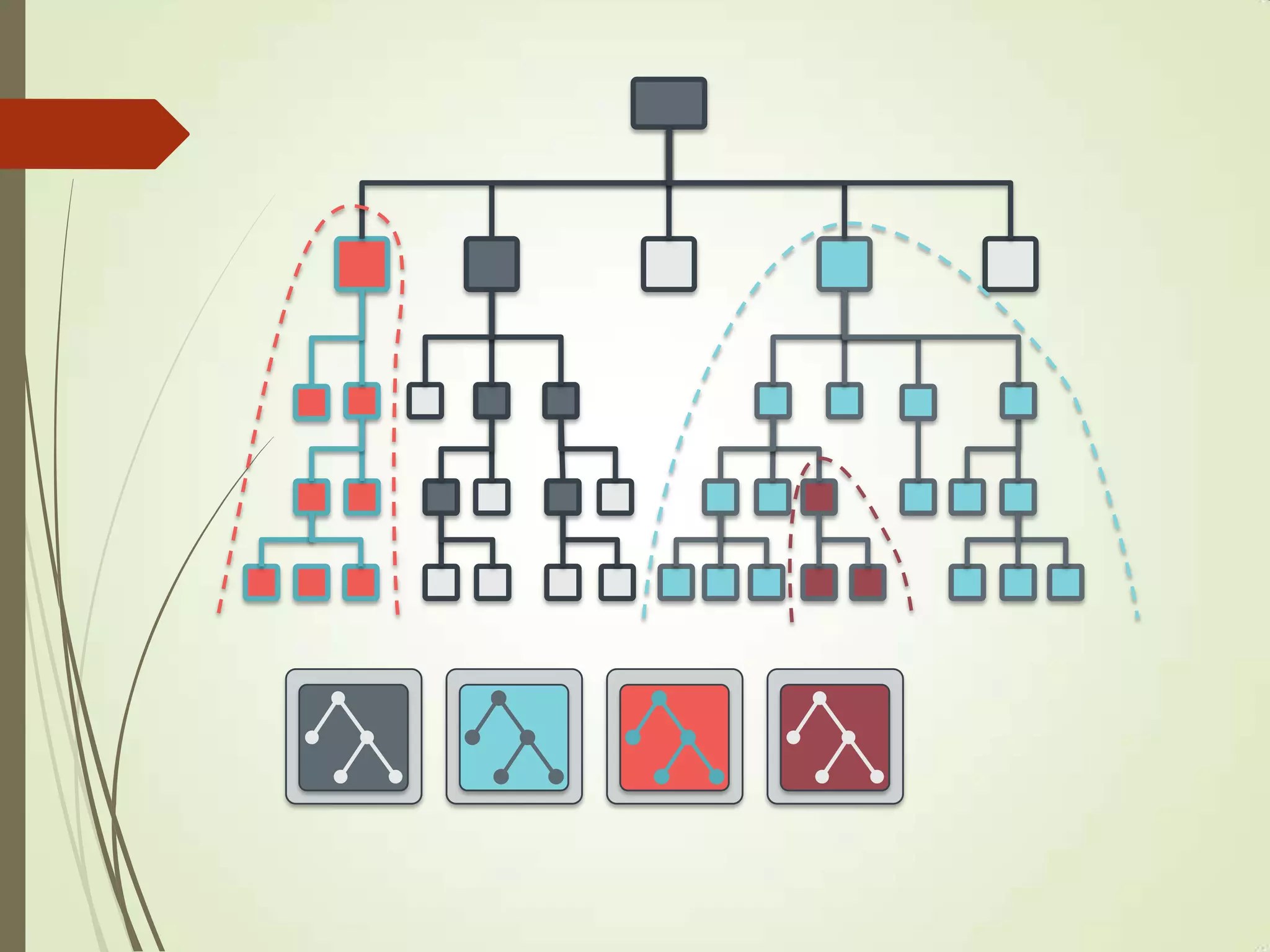
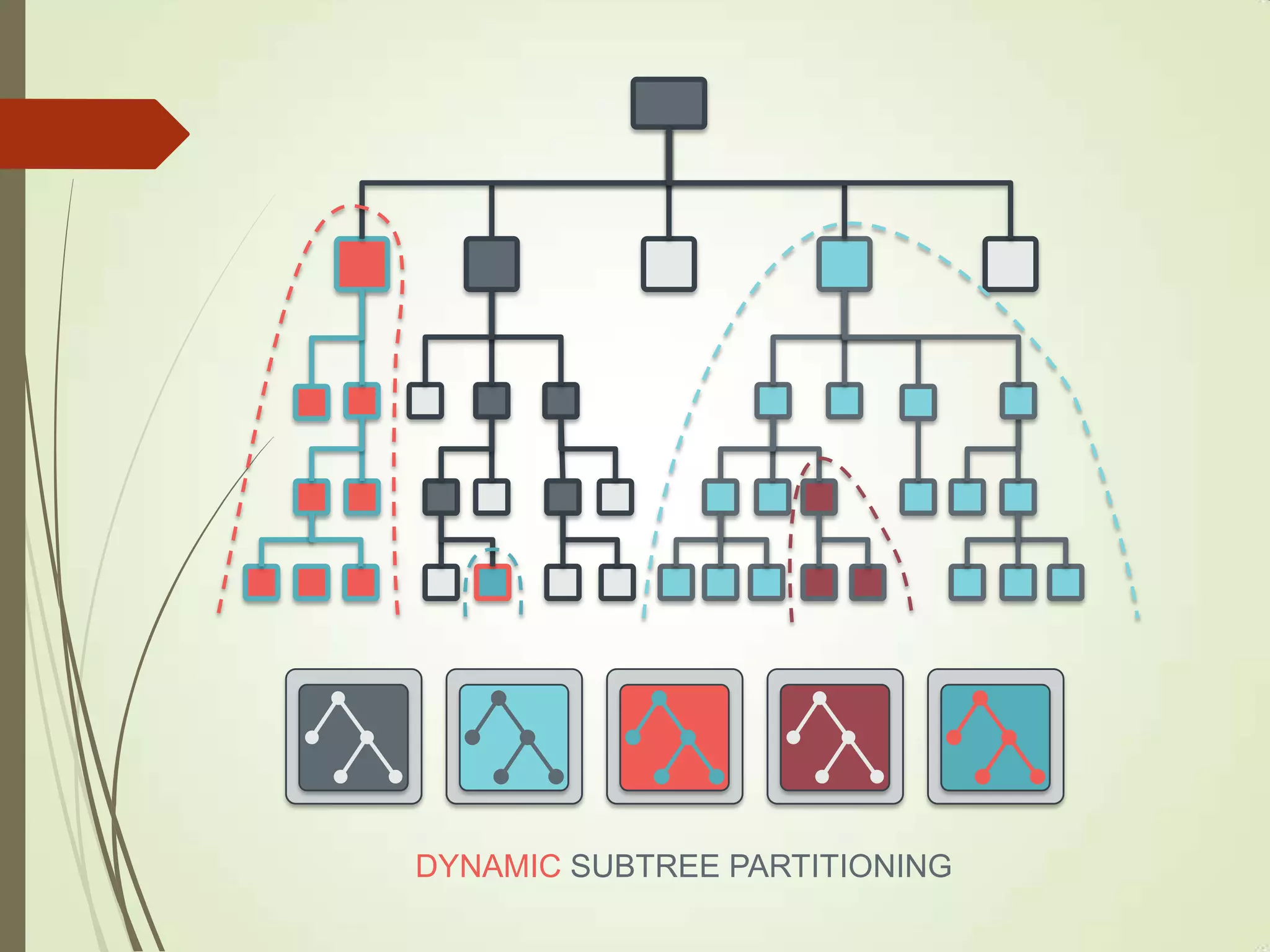




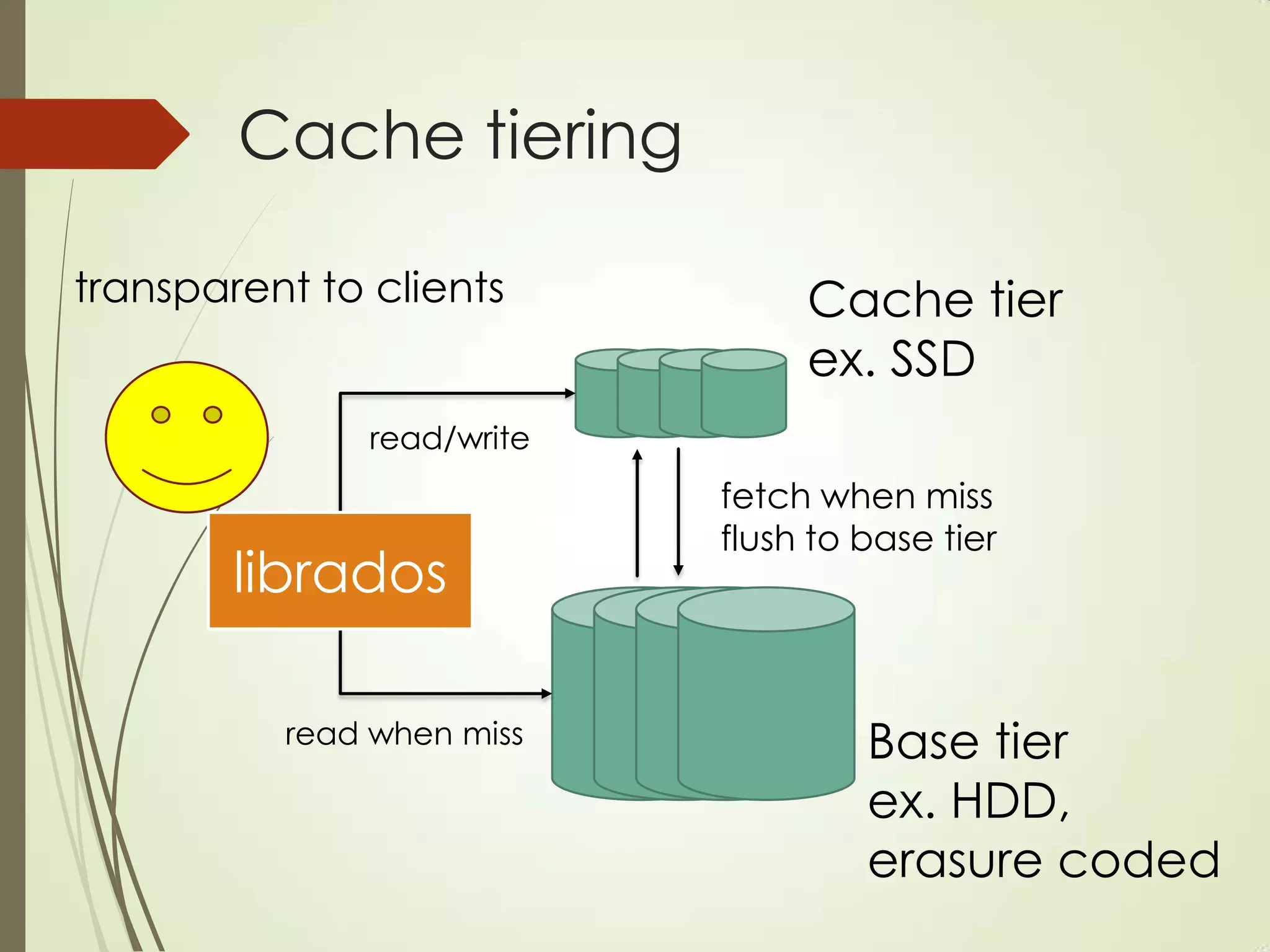

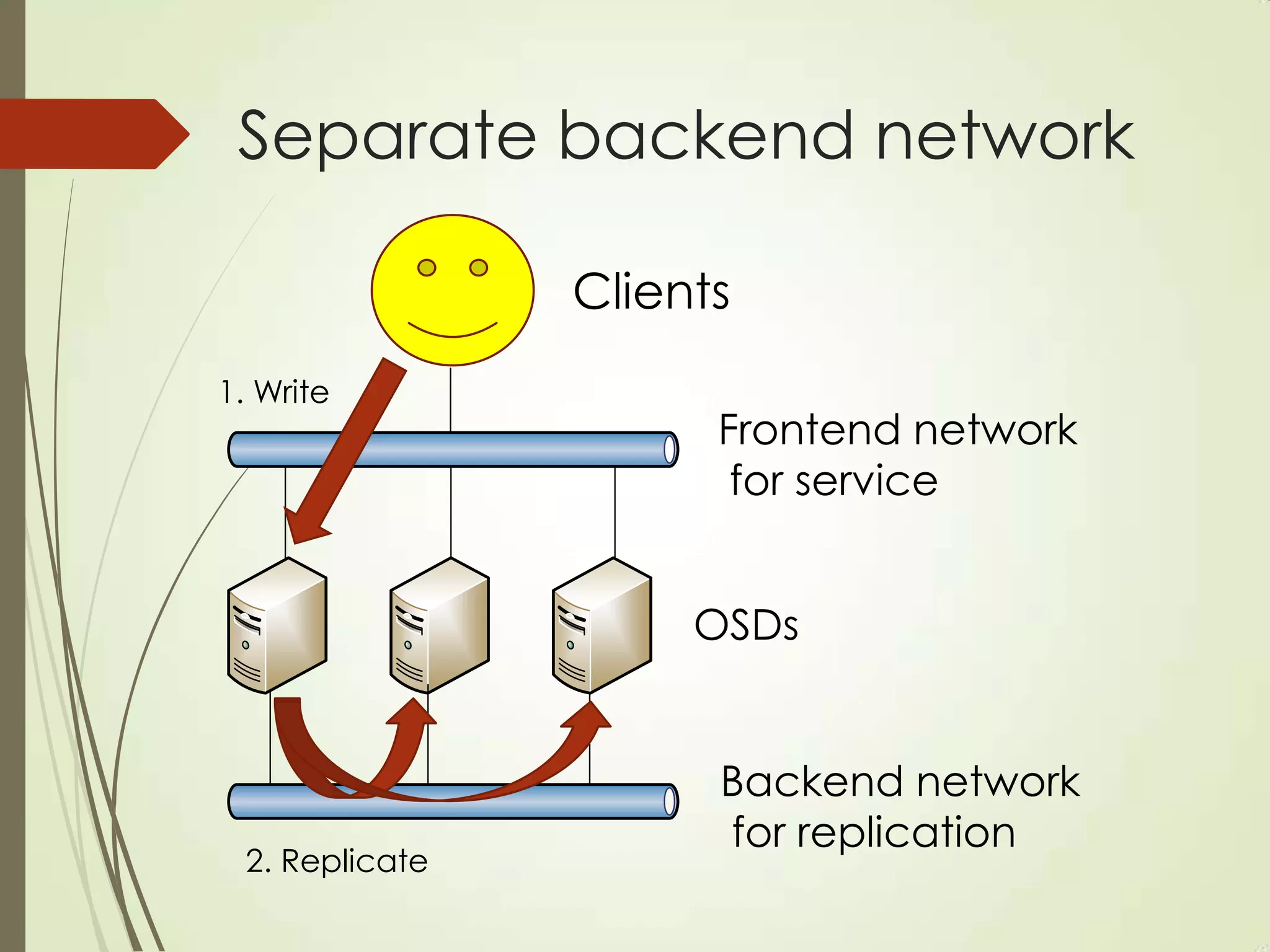

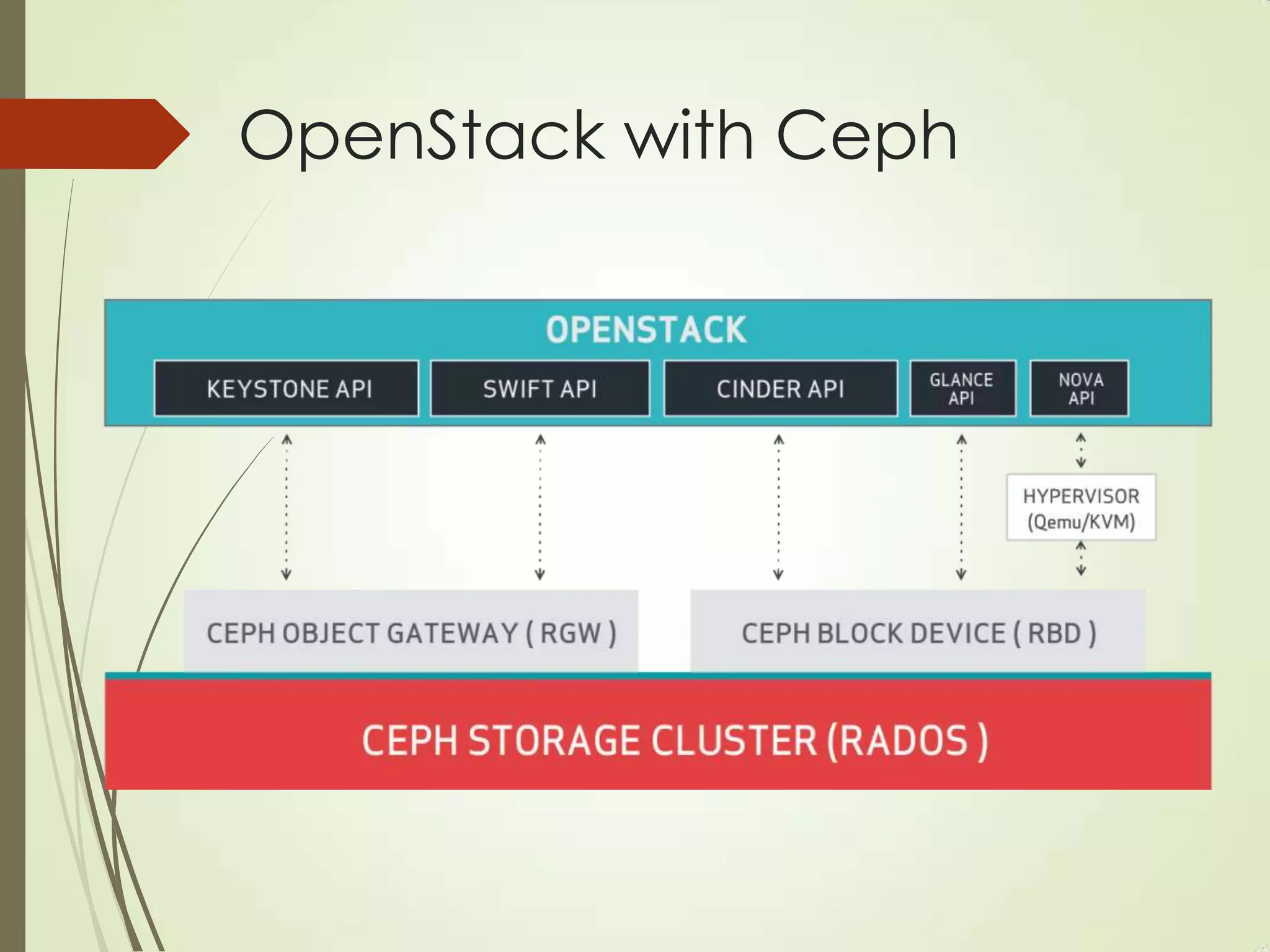
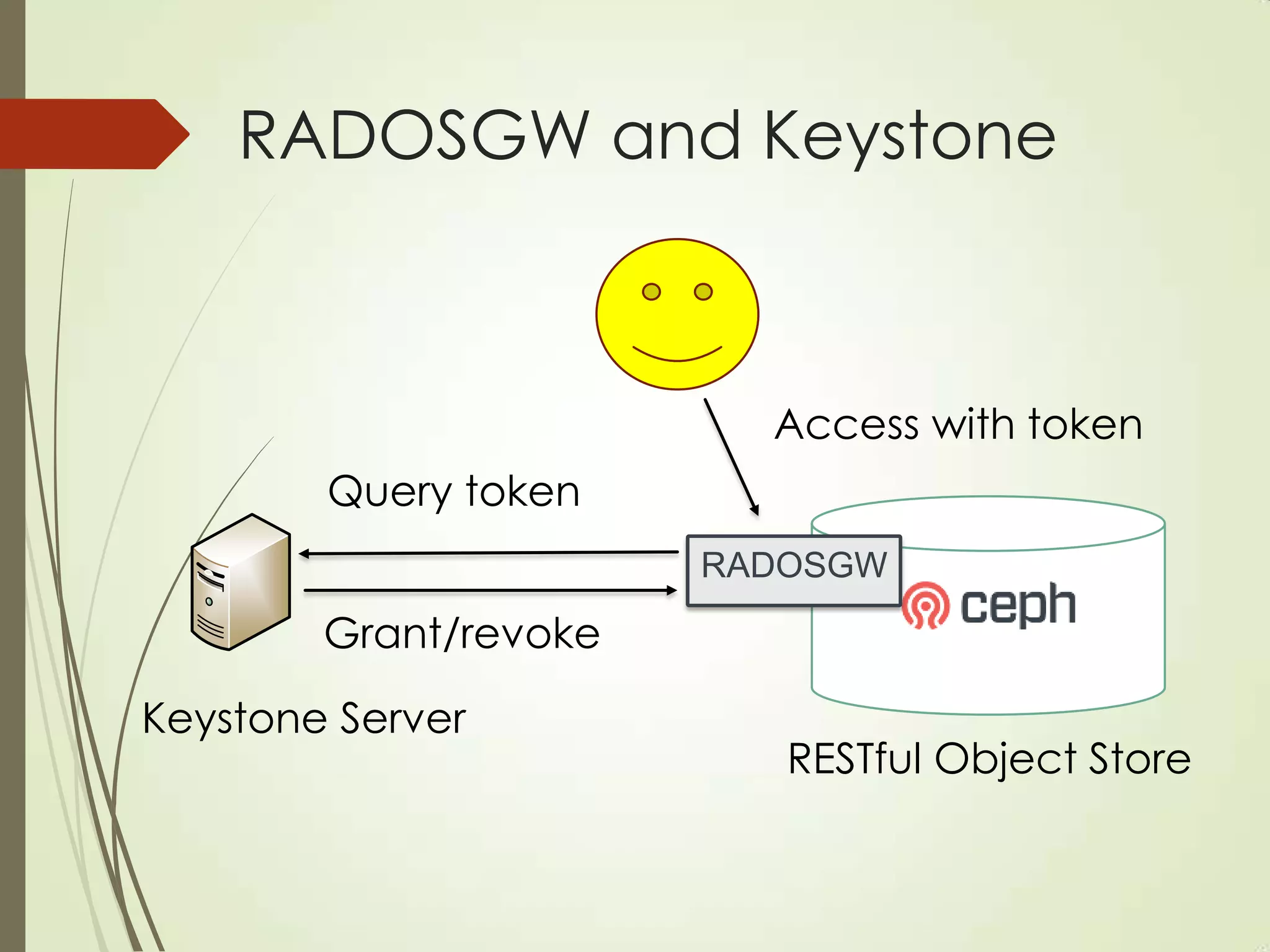
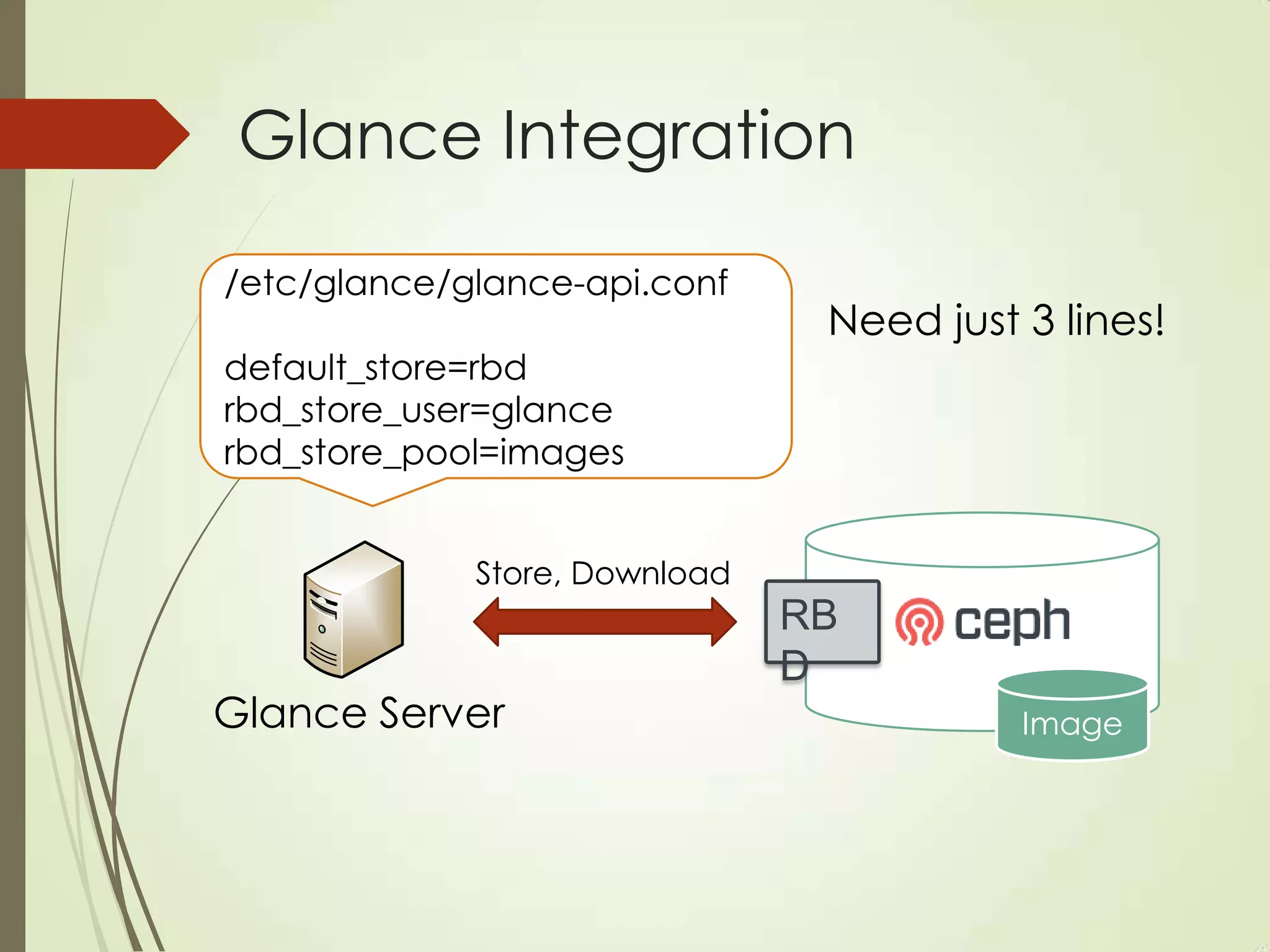
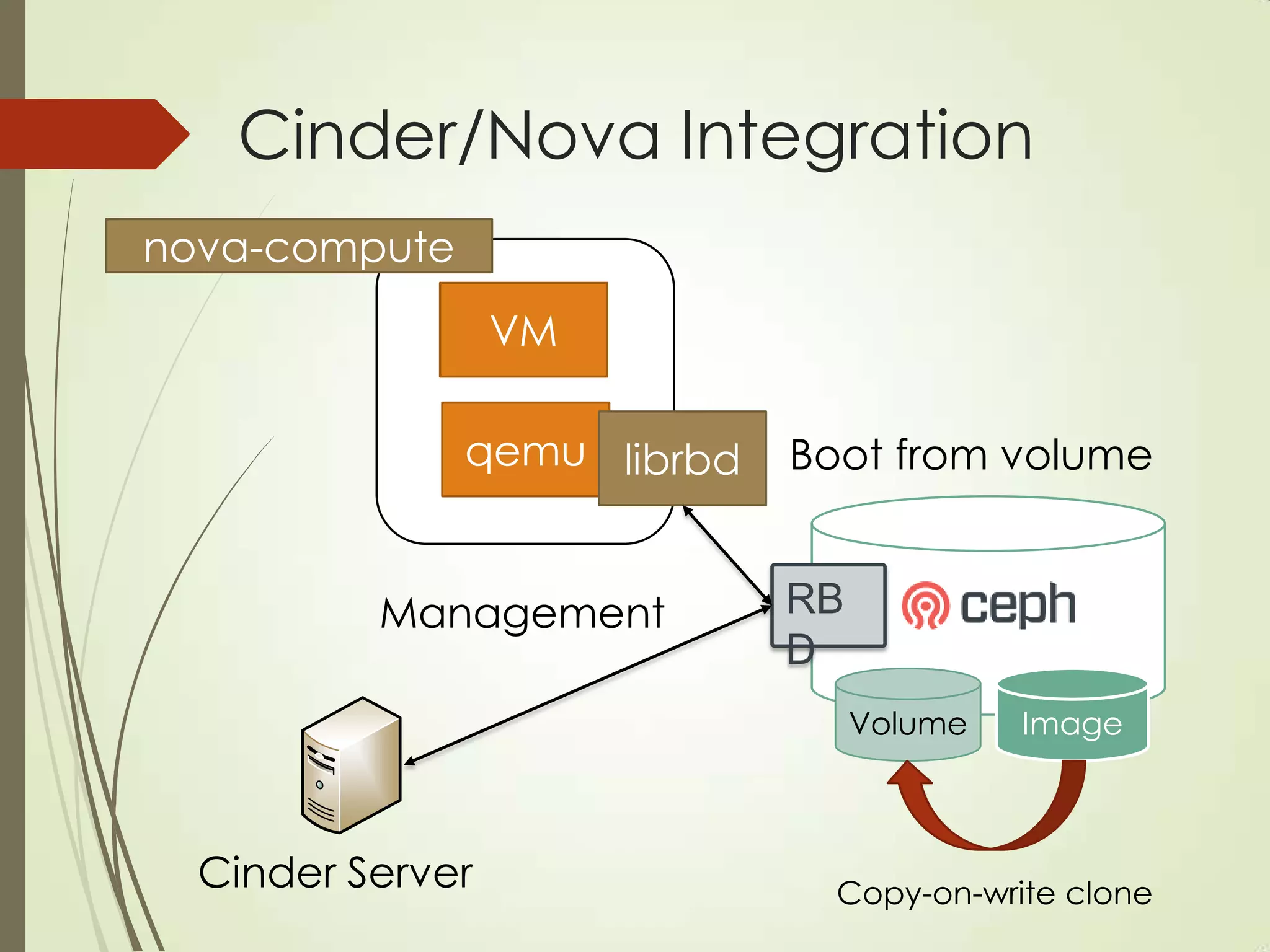








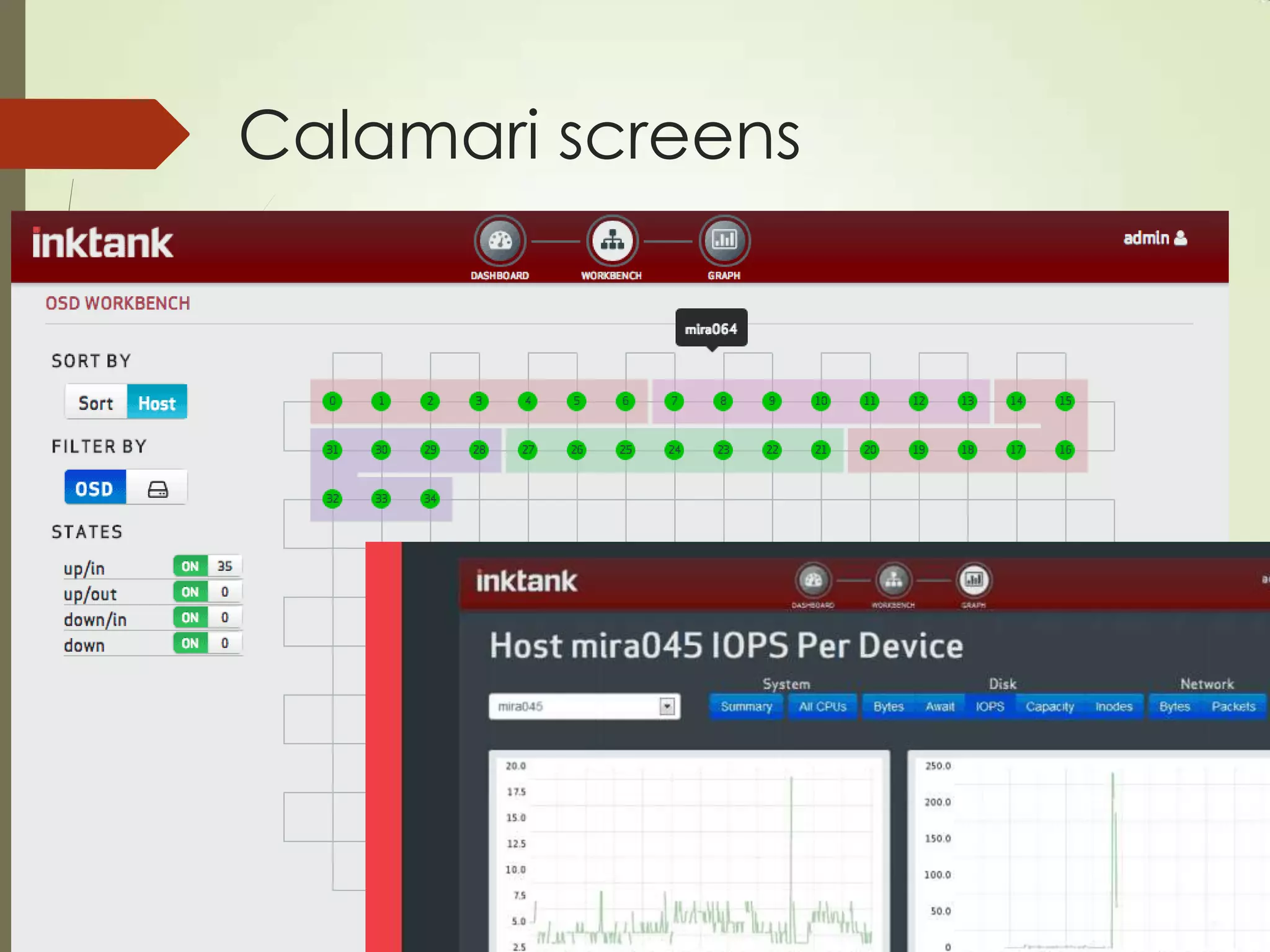


The document provides an overview of Ceph, an open-source storage platform known for its massively scalable architecture and integration with OpenStack. It details the underlying components of Ceph, including RADOS, CephFS, and the CRUSH algorithm that enables distributed storage without centralized metadata. Additionally, it highlights Ceph’s capabilities in unified storage for object, block, and POSIX file systems, and mentions recent developments such as the acquisition of Inktank by Red Hat.
















![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)














































![Docker向けOSとか[LT] @ #techgirl 2015/01](https://cdn.slidesharecdn.com/ss_thumbnails/techgirllt201501dockeros-150131223346-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)























