Downloaded 27 times











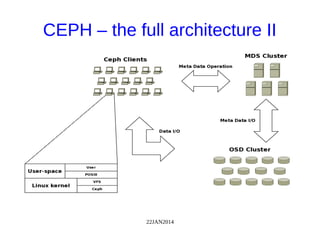






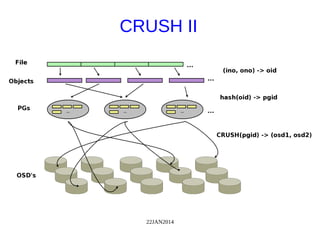






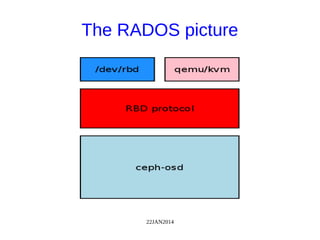



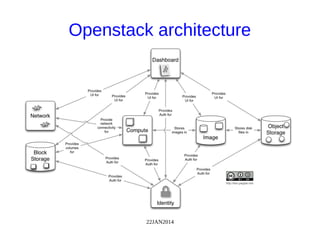











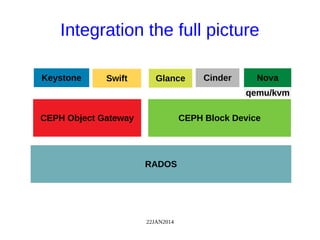








The document discusses Ceph, a distributed storage system, highlighting its architecture, the role of object-based storage devices, and integration with OpenStack. Ceph provides a scalable storage solution without single points of failure, utilizing a unique algorithm for data distribution and replication. The presentation emphasizes the benefits of using Ceph with OpenStack for various cloud storage needs.




























































































