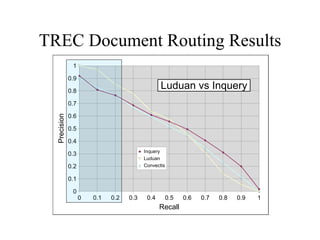
The document discusses using log-likelihood ratio (LLR) tests to analyze transactional data. It defines transactional data as sequences of transactions that may include symbols, times, and amounts. The document proposes applying LLR tests to transactional data by decomposing the LLR test into terms for symbols/timing and amounts. Examples of applying this methodology to problems in insurance risk prediction, fraud detection, and system monitoring are provided.















![Transaction Sequence Distributions
● Mixed Poisson distributions give desired
symbol/timing behavior
● Amount distribution depends on symbol
k − T
T e
pZ = ∏ ∏ p x i∣
∈ k ! i=1. .. N
i
[ ][ ]∏
k − T
N
T e
pZ = N ! ∏
p x i∣
∈ k ! N! i
i=1. .. N
= , ∑ =1
∈](https://image.slidesharecdn.com/trans-091102010835-phpapp02/85/Transactional-Data-Mining-17-320.jpg)
![LLR for Multinomial
● Easily expressed as entropy of contingency table
[ ]
k 11 k 12 ... k1 n k 1*
k 21 k 22 ... k2n k 2*
⋮ ⋮ ⋱ ⋮ ⋮
k m1 k m2 ... k mn k m*
k * 1 k * 2 ... k * n k **
−2 log =2 N
∑ ij log ij −∑ i * log i *−∑ * j log * j
ij i j
k ij k ** ij
log =∑ k ij log =∑ k ij log d.o.f.=m−1n−1
ij k i * k * j ij * j](https://image.slidesharecdn.com/trans-091102010835-phpapp02/85/Transactional-Data-Mining-18-320.jpg)
![LLR for Poisson Mixture
● Easily expressed using timed contingency table
[ ∣]
k 11 k 12 ... k1n t1
k 21 k 22 ... k 2n t2
⋮ ⋮ ⋱ ⋮ ⋮
k m1 k m2 ... k mn tm
k * 1 k * 2 ... k * n ∣ t *
k ij t * ij
log =∑ k ij log =∑ k ij log
ij t i k * j ij * j
d.o.f.=m−1 n](https://image.slidesharecdn.com/trans-091102010835-phpapp02/85/Transactional-Data-Mining-19-320.jpg)

![Calculations
● Assume X1 and X2 are normally distributed
● Null hypothesis of identical mean and variance
p x∣ ,=
1
2
e
− x−2
2 2
= i
N
∑ xi
= i
N
∑ x−2
log p X 1∣ , log p X 1∣ , −log p X 1∣1, 1 −log p X 2∣2, 2 =
− ∑ [
i=1. . N 1
log 2 log
x 1i −2
2 2 ] [
− ∑ log 2 log
i=1. . N
2
x 2 i −2
2 2 ]
∑ [ ] ∑[ ]
2 2
x − x −
log 2 log 1 1i 2 1 log 2 log 2 2i 2 2
i=1. . N 1 2 1 i=1. . N 2
2 2
−2 log =2 N 1 log
1
N 2 log
2
d.o.f.=2](https://image.slidesharecdn.com/trans-091102010835-phpapp02/85/Transactional-Data-Mining-21-320.jpg)

























![The relational data model part[1]](https://cdn.slidesharecdn.com/ss_thumbnails/therelationaldatamodelpart1-150714113659-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






























































































