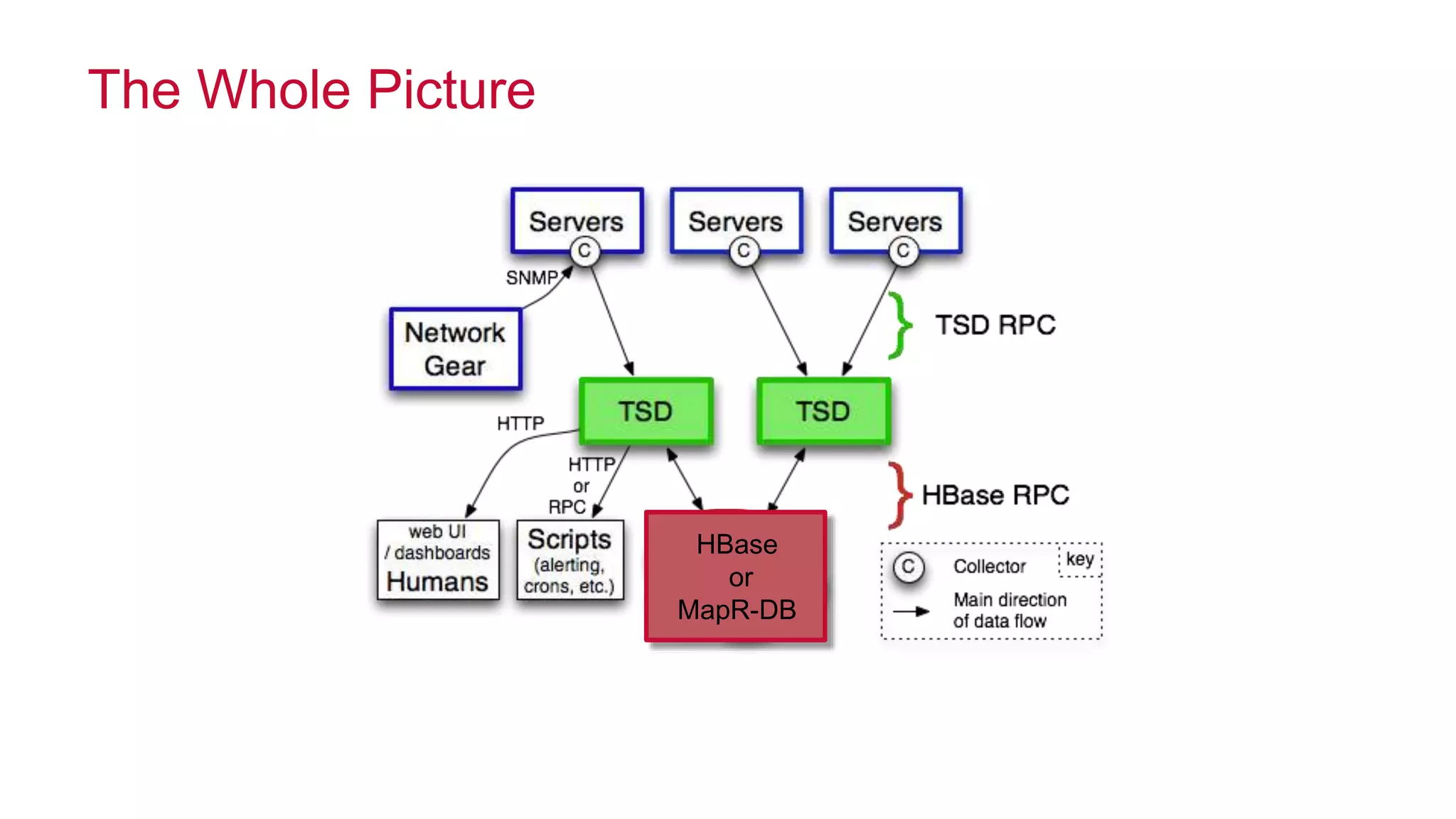
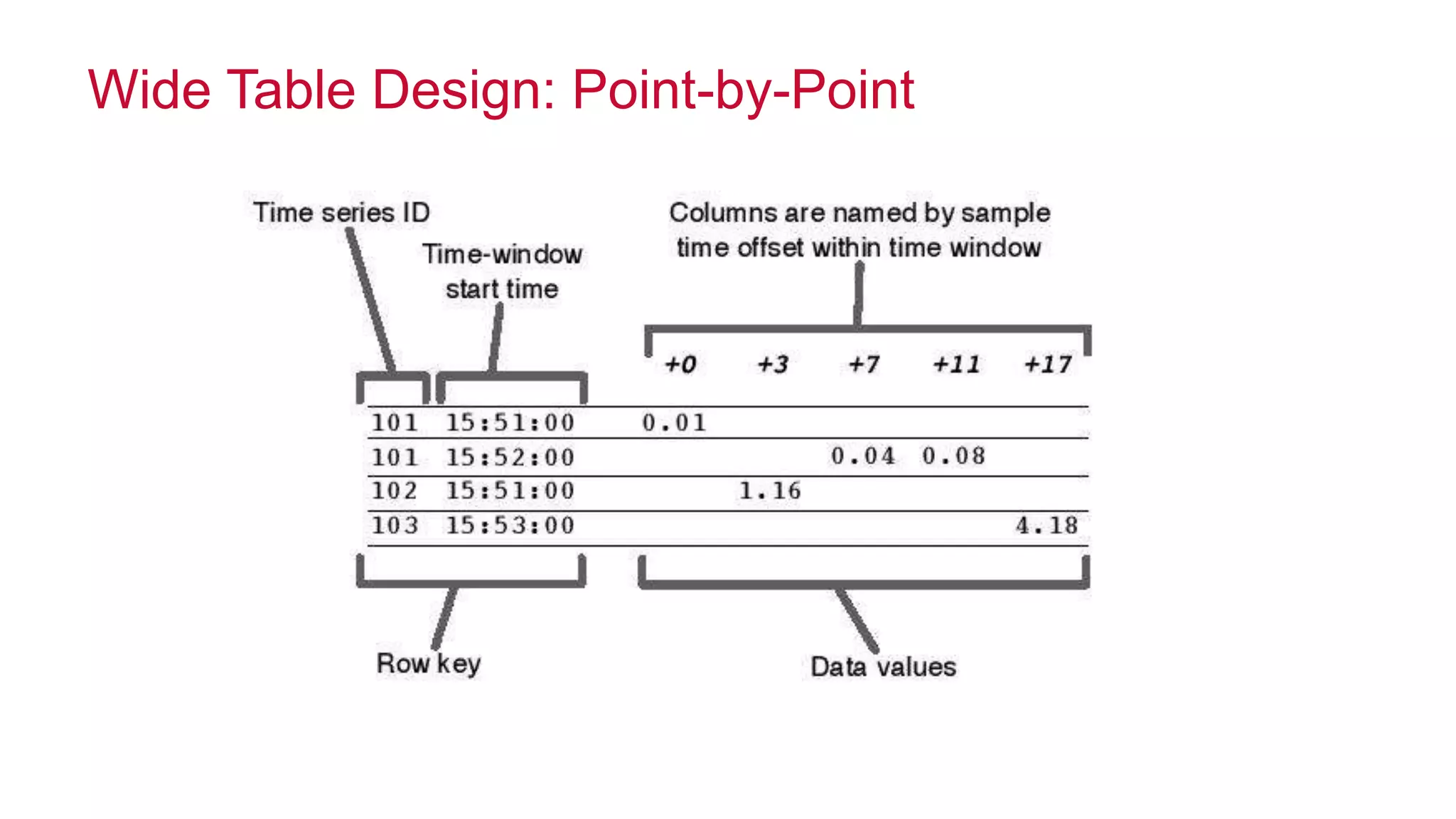
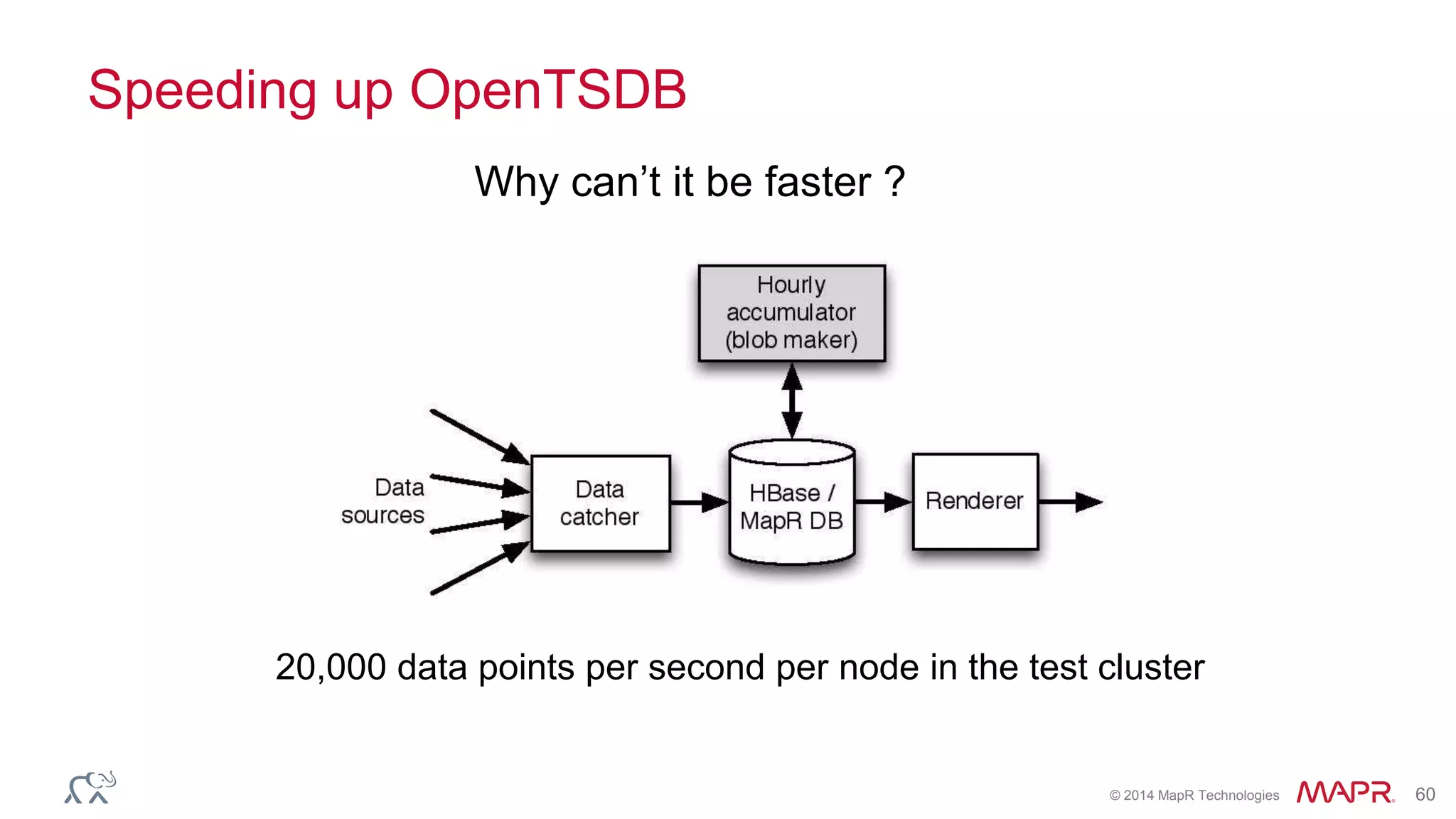
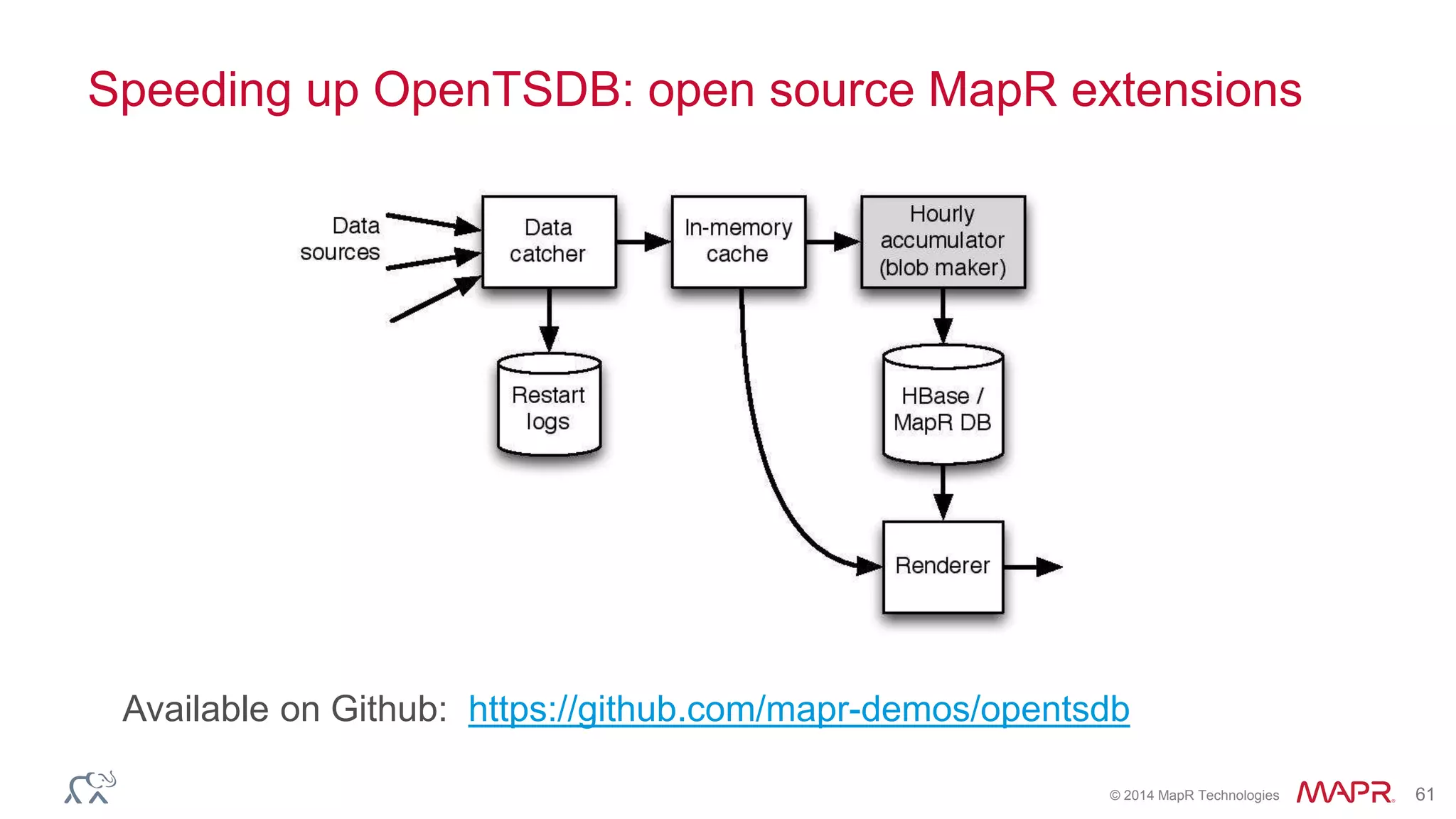
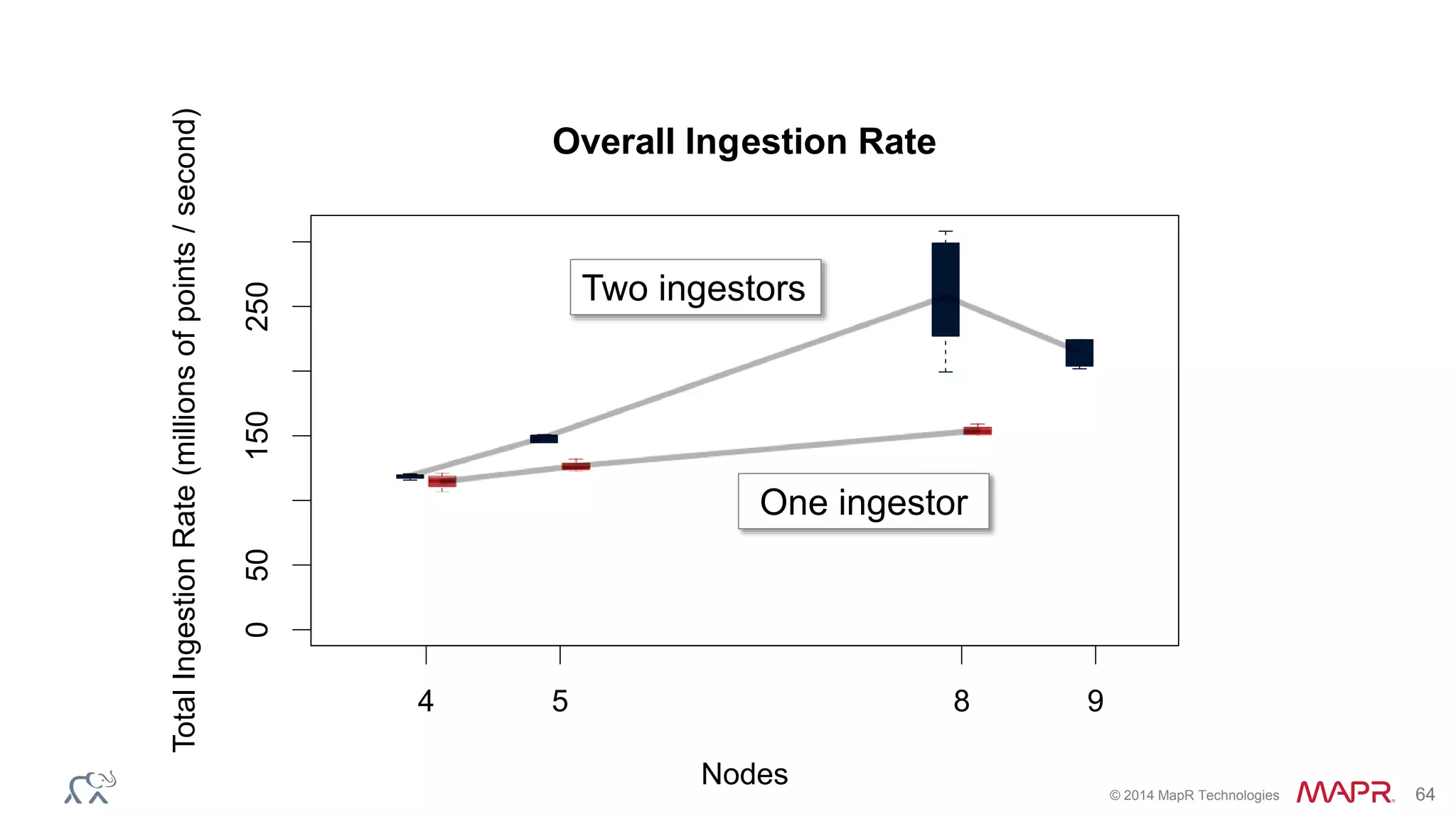
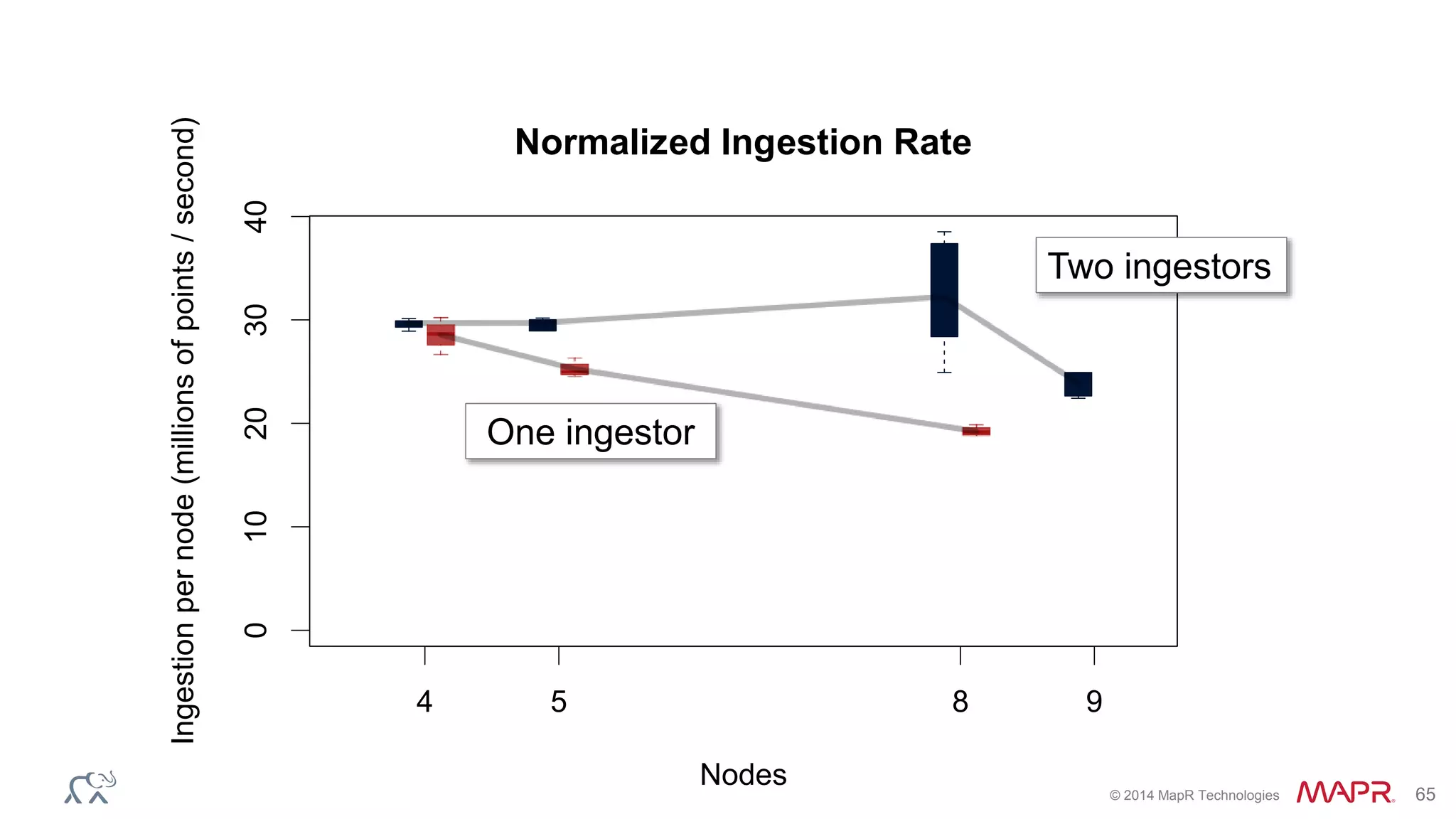
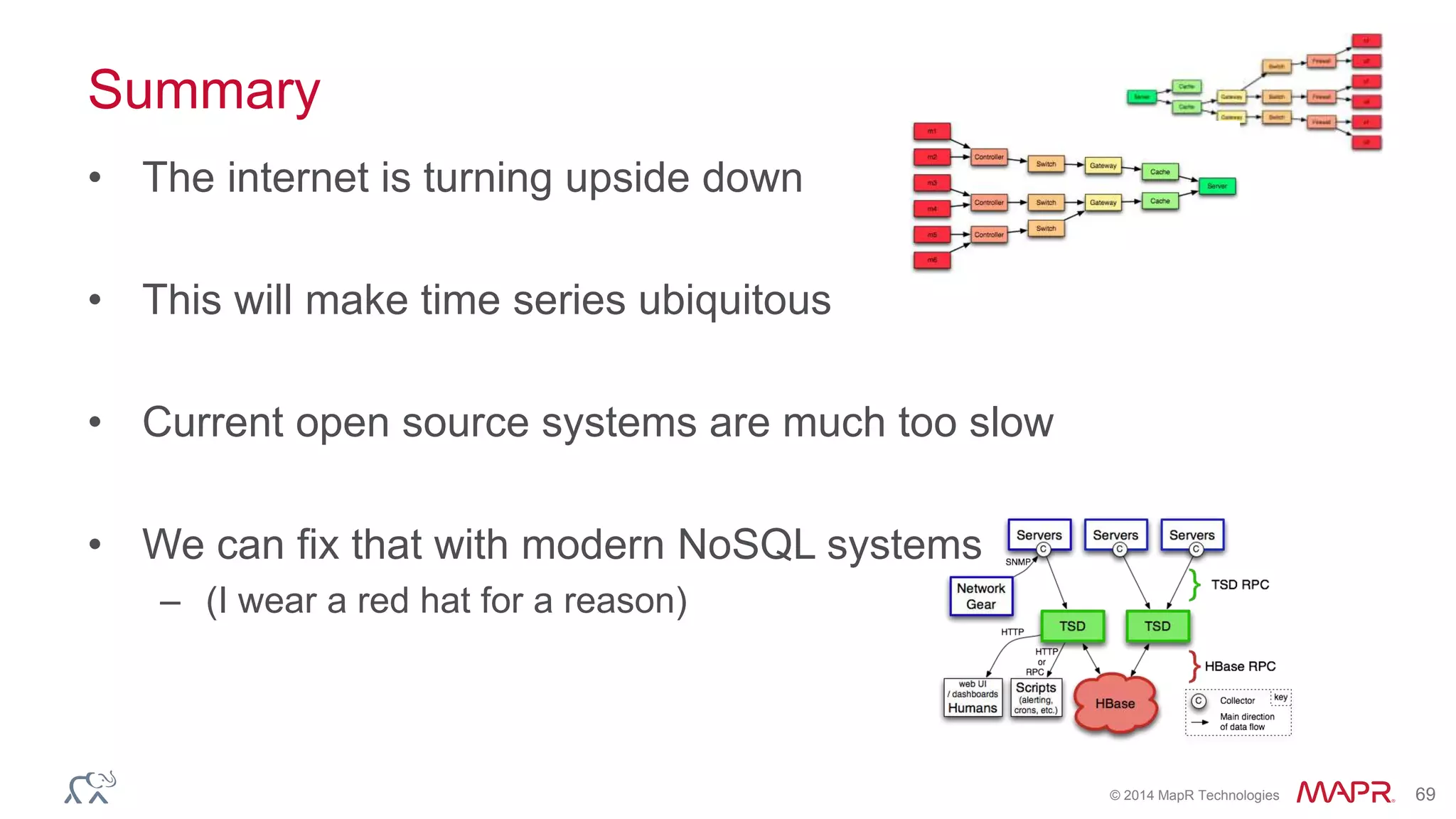
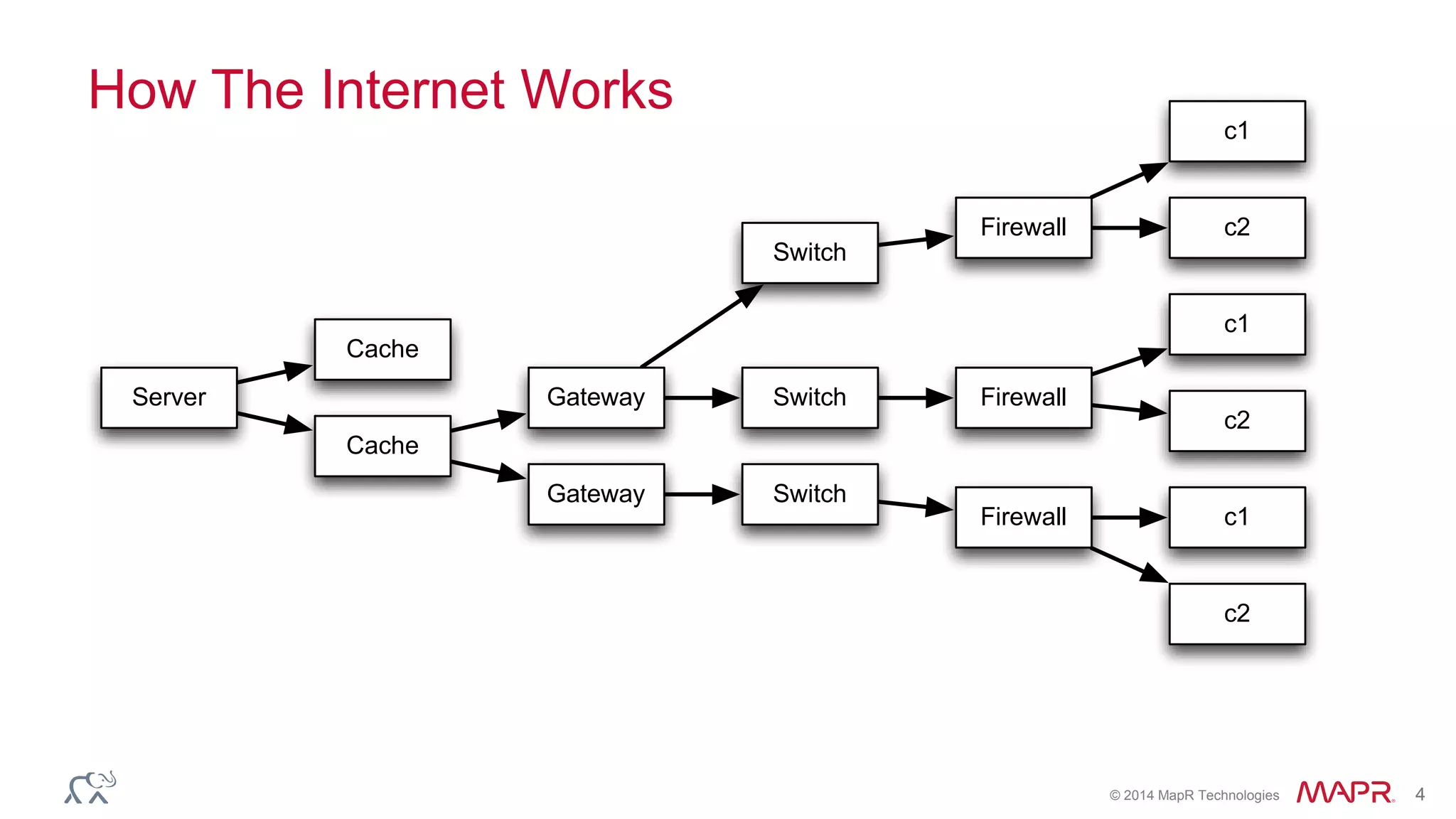
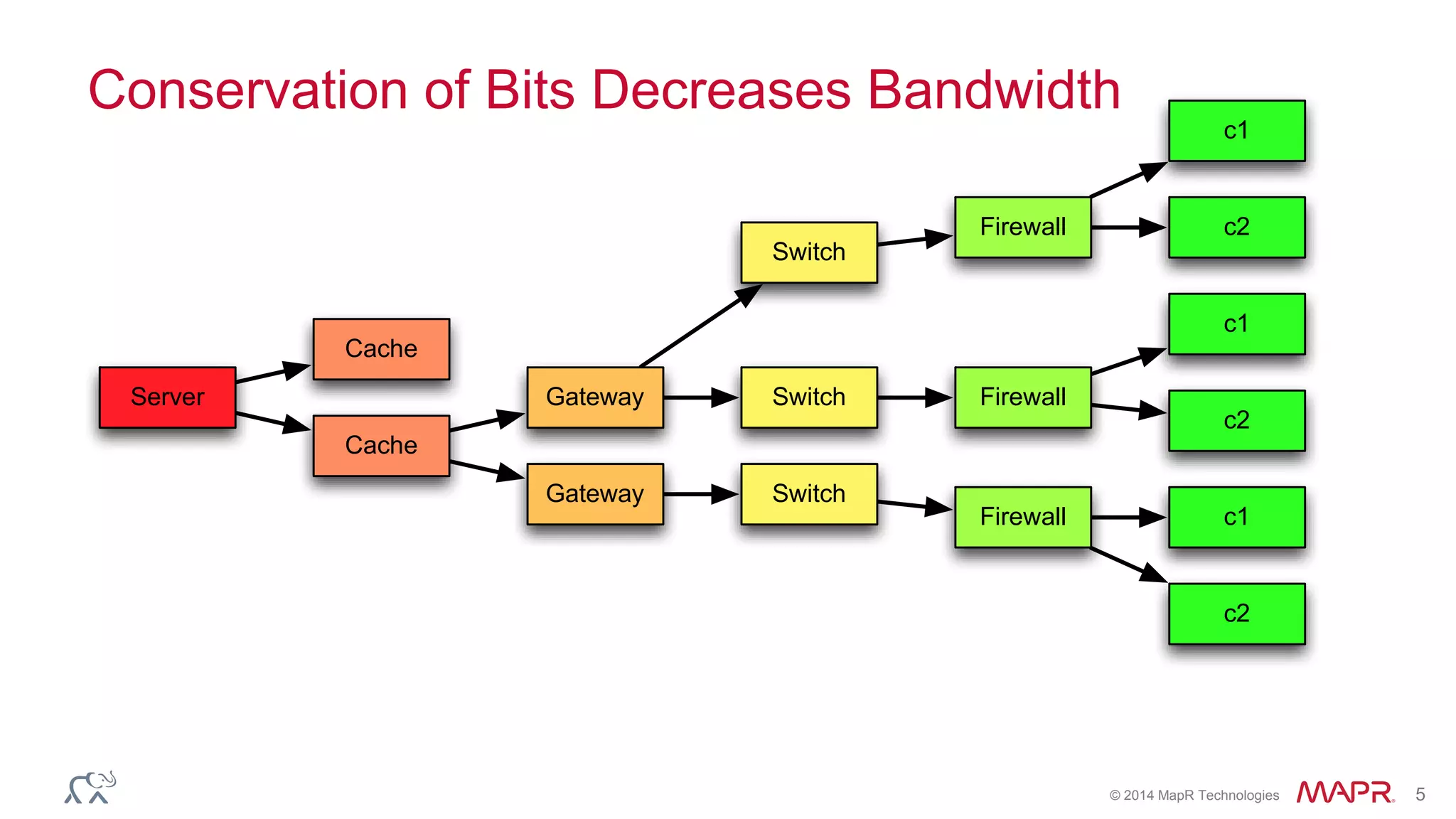
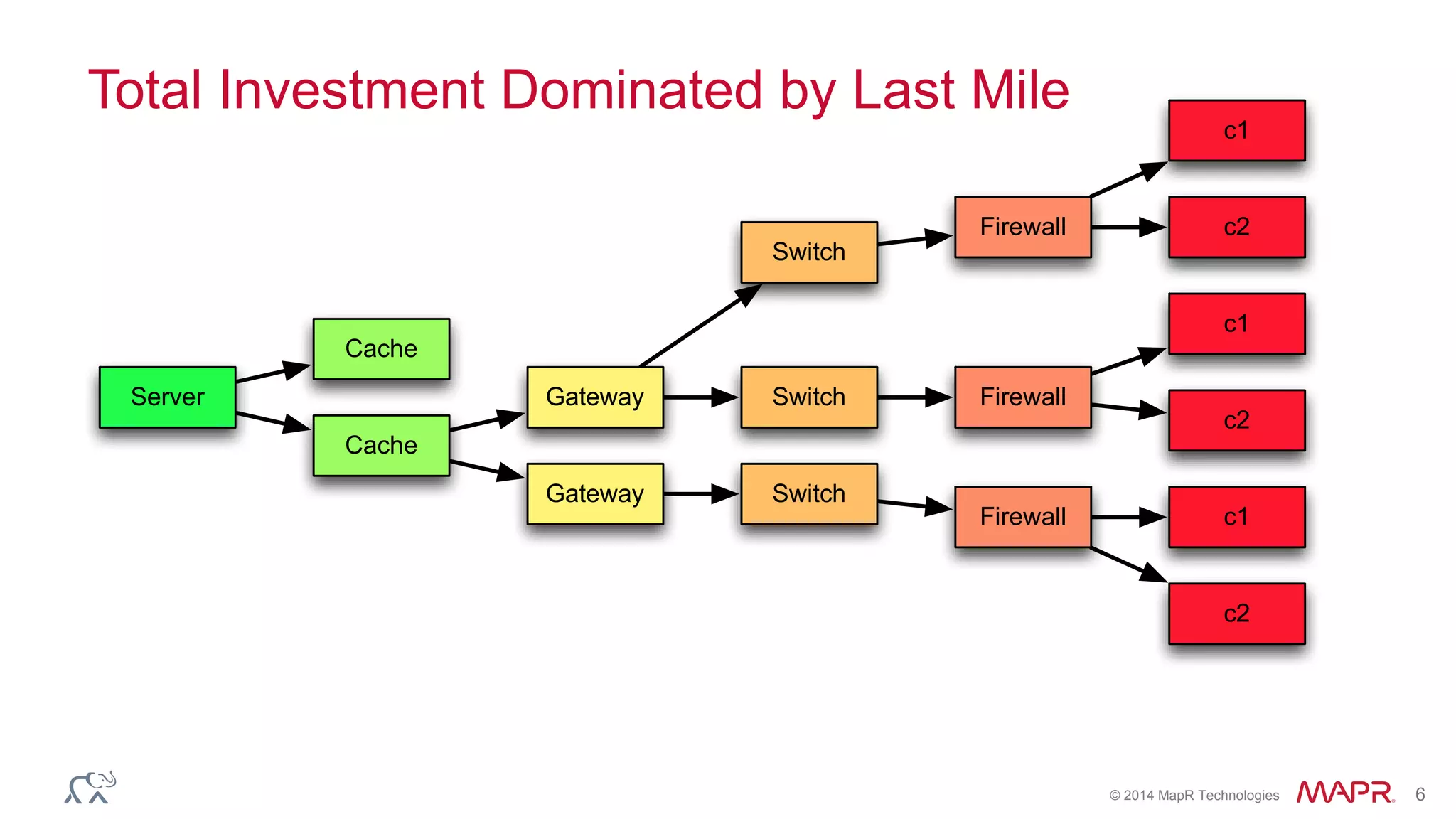
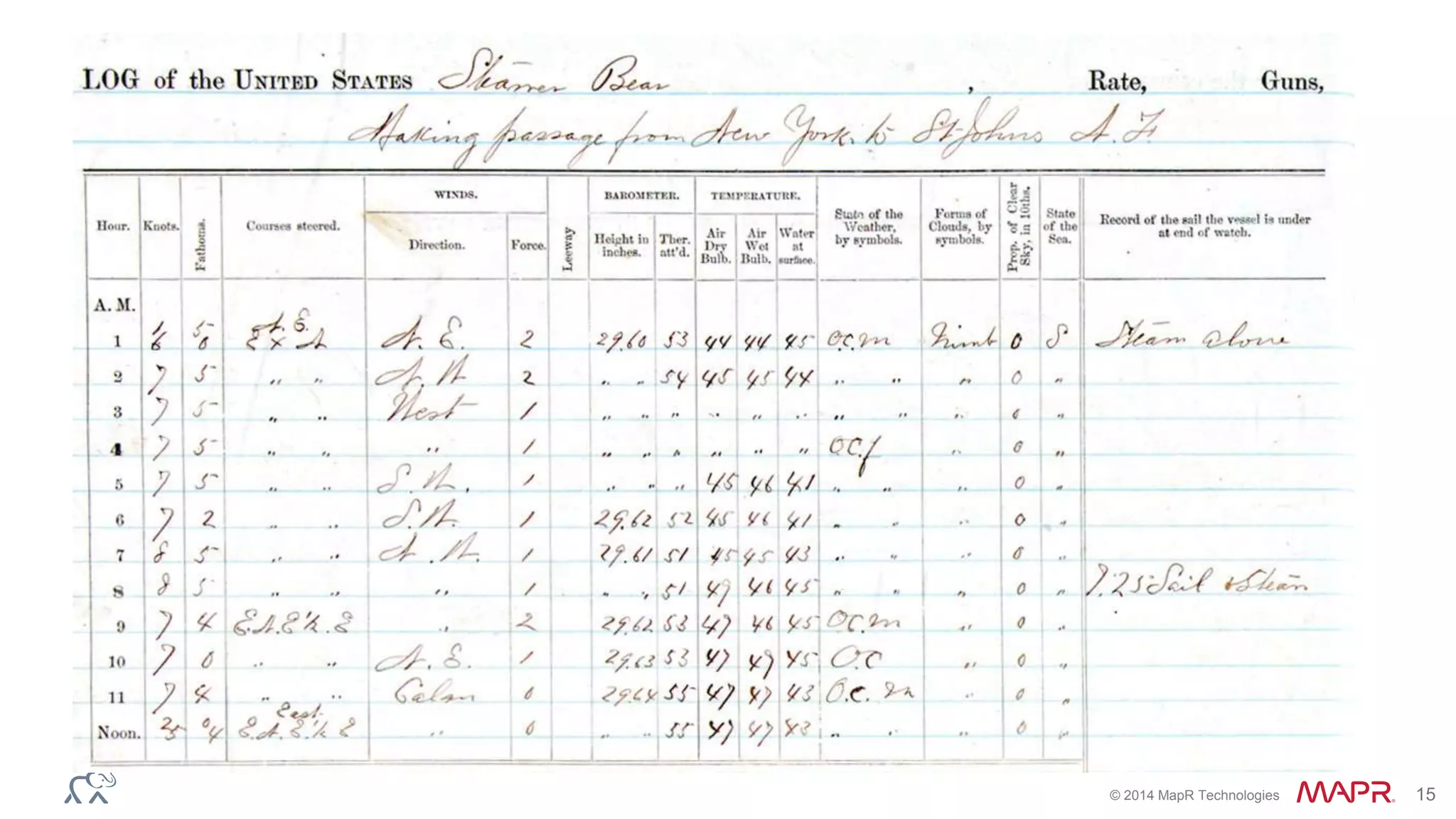
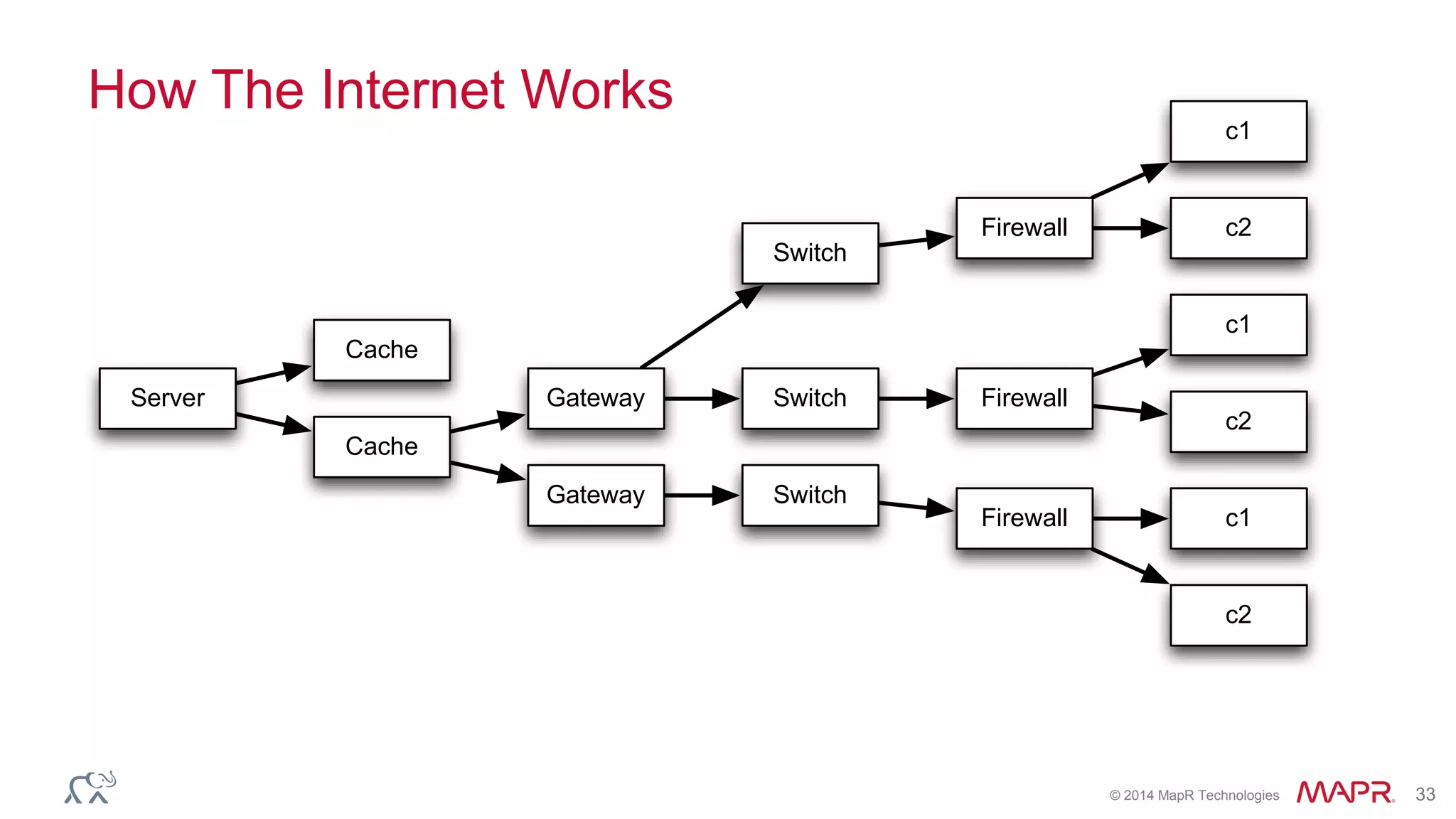
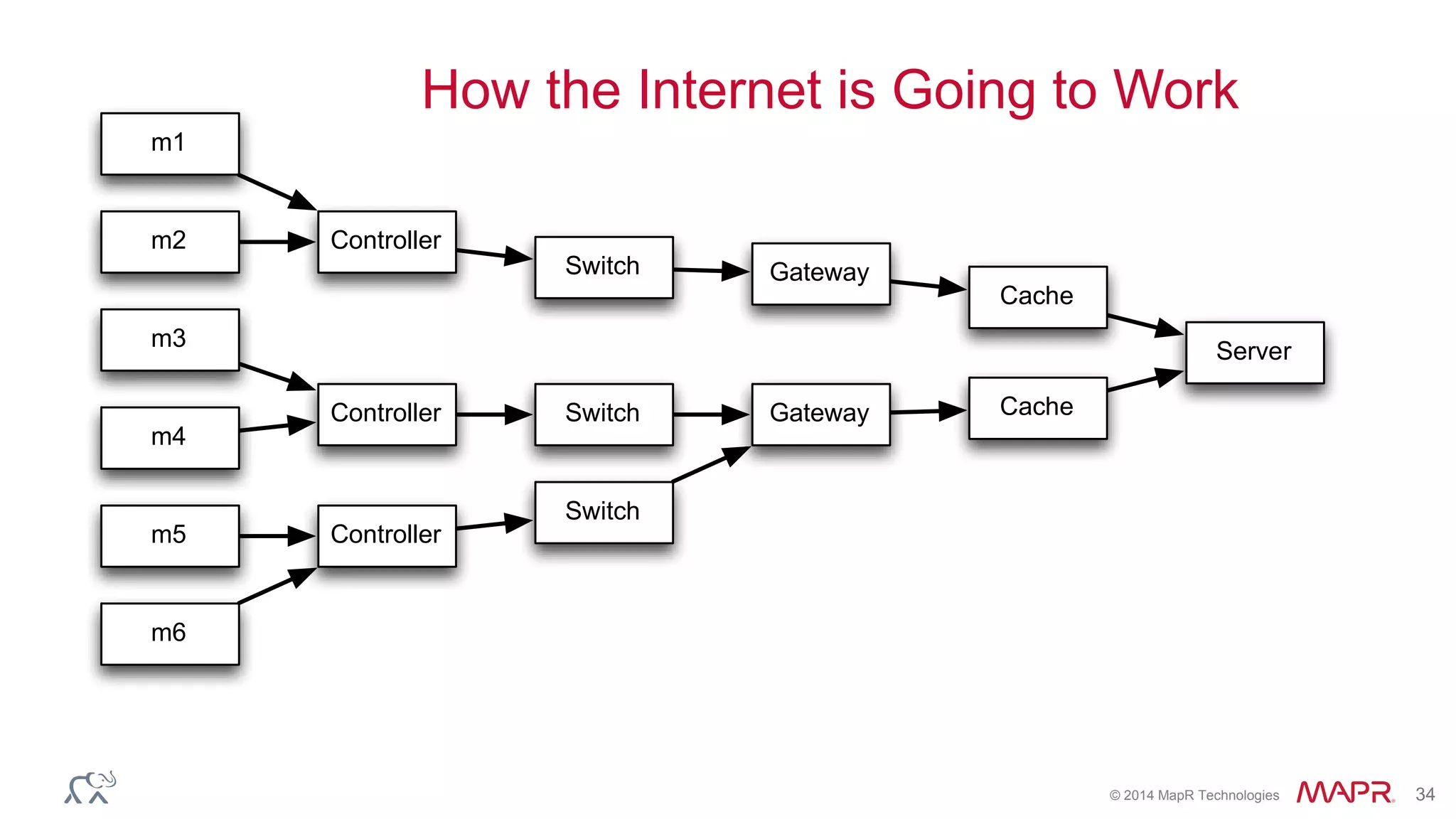
The document discusses the evolution of the internet and the challenges faced in last-mile delivery, emphasizing the importance of efficient time-series data management. It highlights the limitations of current systems in terms of speed and suggests that modern NoSQL solutions can enhance performance significantly. The document concludes by asserting that the future of time-series data will be shaped by advancements in technology, making it more prevalent and accessible.







































![© 2014 MapR Technologies 54
Declare metric
$ tsdb mkmetric mysql.bytes_sent mysql.bytes_received
metrics mysql.bytes_sent: [0, 0, 1]
metrics mysql.bytes_received: [0, 0, 2]
… or use –auto-metric](https://image.slidesharecdn.com/dunning-time-series-2015-150417000107-conversion-gate02/75/How-the-Internet-of-Things-is-Turning-the-Internet-Upside-Down-54-2048.jpg)