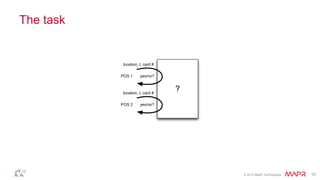
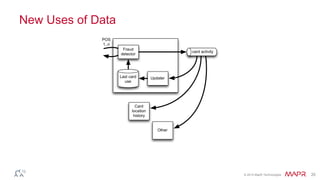
The document outlines a presentation by Ted Dunning at a conference discussing the importance of real-time data processing and micro-service architecture. It emphasizes the need for service isolation, effective data management, and the use of modern protocols for improved performance and scalability. Additionally, it covers the innovative features of MapR's data platform, including the integration of tables, streams, and enhanced compatibility with the Kafka API.





































































































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)
