Downloaded 70 times















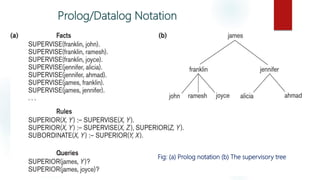










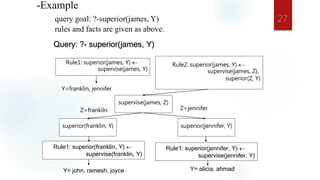
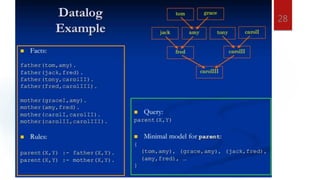



The document discusses deductive databases and how they differ from conventional databases. Deductive databases contain facts and rules that allow implicit facts to be deduced from the stored information. This reduces the amount of storage needed compared to explicitly storing all facts. Deductive databases use logic programming through languages like Datalog to specify rules that define virtual relations. The rules allow new facts to be inferred through an inference engine even if they are not explicitly represented.





























![[ABDO] Logic As A Database Language](https://cdn.slidesharecdn.com/ss_thumbnails/logicasadblanguage-1232531111014566-3-thumbnail.jpg?width=640&height=640&fit=bounds)

























































