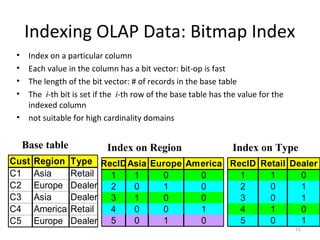
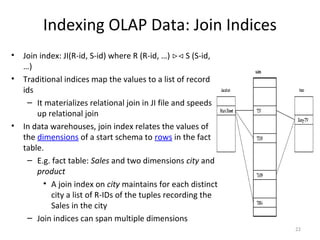
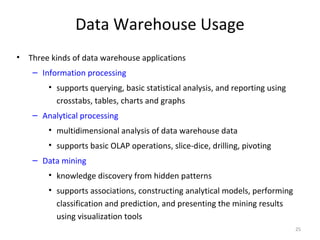
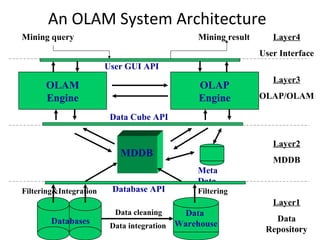
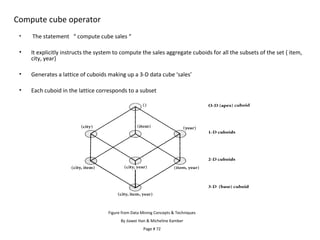
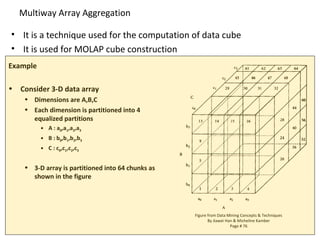
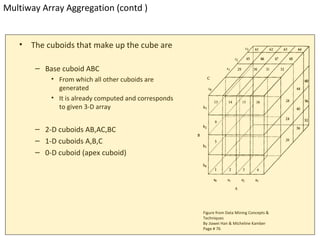
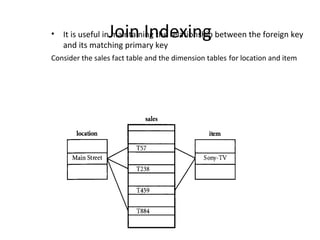
The document discusses data warehouse implementation and online analytical processing (OLAP). It describes the compute cube operator, which computes aggregates for all subsets of specified dimensions. It also covers efficient cube computation techniques like chunking and materialized views. Better access methods for OLAP like bitmap indexing and join indexing are also summarized. The document emphasizes that efficient query processing requires determining which operations to perform on available cuboids and selecting the optimal cuboid based on factors like storage size and indexing.




![Cube Operation
• Cube definition and computation in DMQL
define cube sales[item, city, year]: sum(sales_in_dollars)
compute cube sales
• Transform it into a SQL-like language (with a new operator cube by,
introduced by Gray et al.’96) ()
SELECT item, city, year, SUM (amount)
FROM SALES (city) (item) (year)
CUBE BY item, city, year
• Need compute the following Group-Bys
(city, item) (city, year) (item, year)
(date, product, customer),
(date,product),(date, customer), (product, customer),
(date), (product), (customer) (city, item, year)
() 4](https://image.slidesharecdn.com/datacube-120829060819-phpapp01/85/Datacube-4-320.jpg)









![Consider a data cube for “Best Electronics” of the form
• “sales [time, item, location]:sum(sales_in_dollars)
• Dimension hierarchies used are :
– “ day<month<quarter<year ” for time
– “ item_name<brand<type” for item
– “ street<city<province_or_state<country “ for location
• Query :{ brand,province_or_state} with year = 2000
• Materialized cuboids available are
• Cuboid 1: { item_name,city,year}
• Cuboid 2: {brand,country,year}
• Cuboid 3: {brand,province_or_state,year}
• Cuboid 4: {item_name,province_or_state} where year=2000](https://image.slidesharecdn.com/datacube-120829060819-phpapp01/85/Datacube-18-320.jpg)