Downloaded 425 times









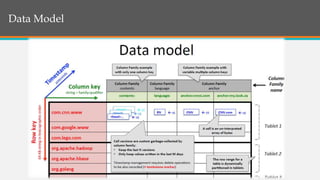



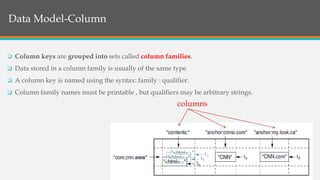

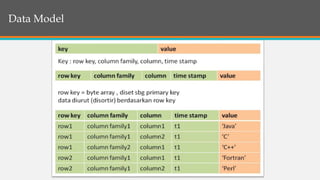







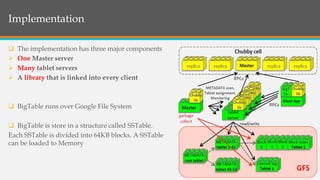

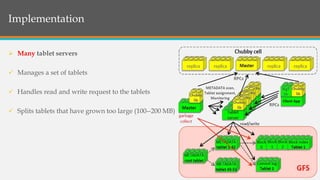

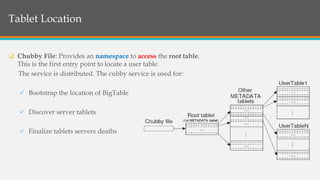








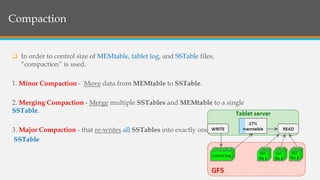
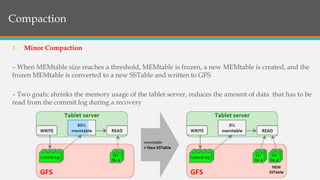





This document provides an overview of Google BigTable, including its motivation, key components, data model, and implementation. BigTable is a distributed storage system designed to scale to massive amounts of data across thousands of servers. It uses several Google technologies like Google File System for storage, Chubby for locking, and MapReduce for distributed processing. The document describes BigTable's data model of rows, columns, and timestamps, as well as its APIs, building blocks, load balancing structure, and compaction process.




















































































