Downloaded 1,028 times







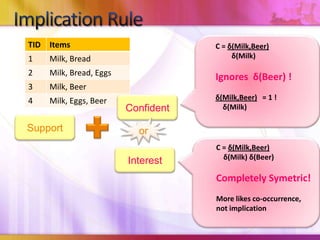

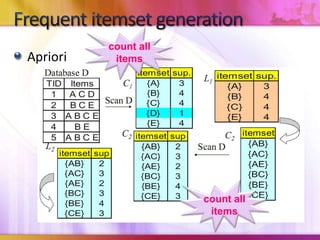
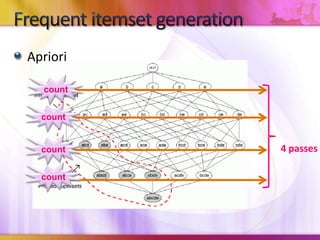
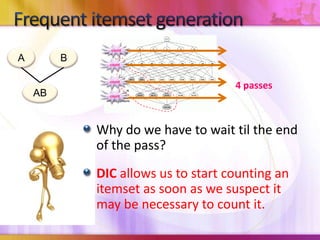
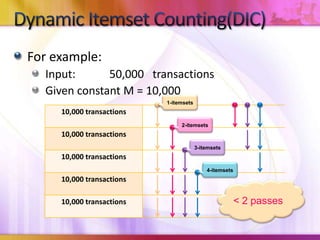
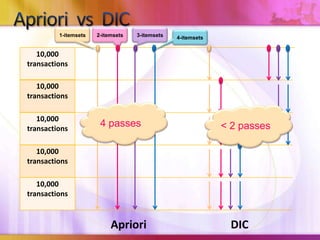



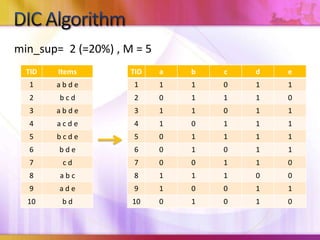
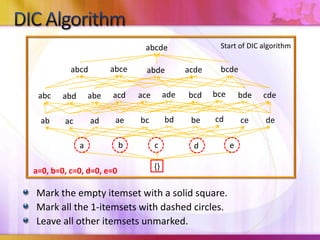
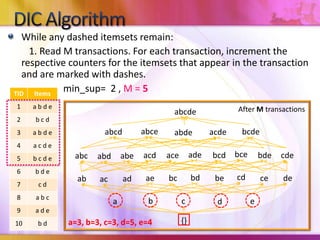
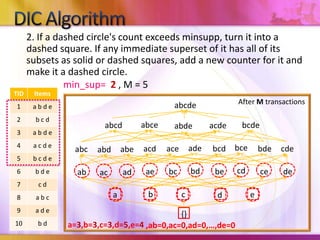

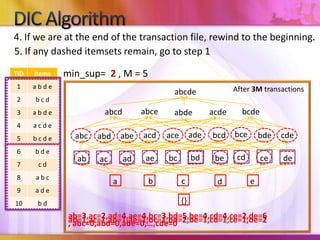
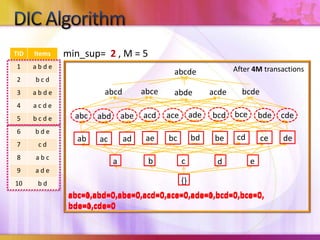
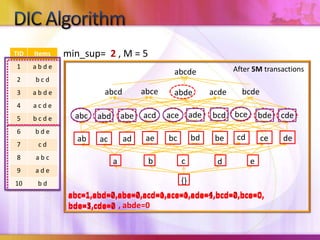
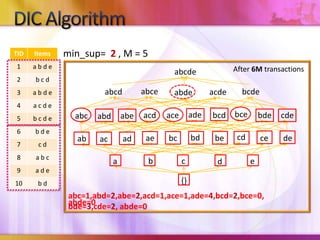
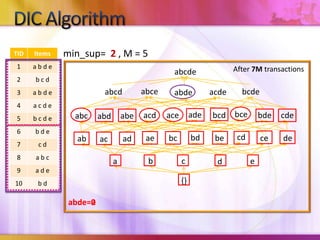









Dynamic Itemset Counting (DIC) is an algorithm for efficiently mining frequent itemsets from transactional data that improves upon the Apriori algorithm. DIC allows itemsets to begin being counted as soon as it is suspected they may be frequent, rather than waiting until the end of each pass like Apriori. DIC uses different markings like solid/dashed boxes and circles to track the counting status of itemsets. It can generate frequent itemsets and association rules using conviction in fewer passes over the data compared to Apriori.























































































