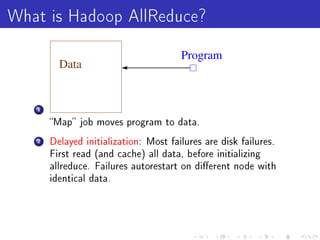
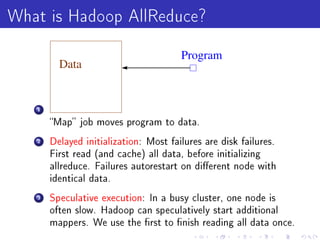
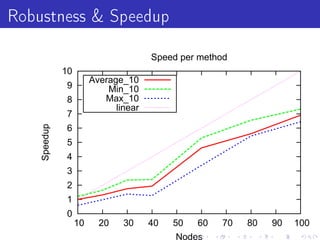
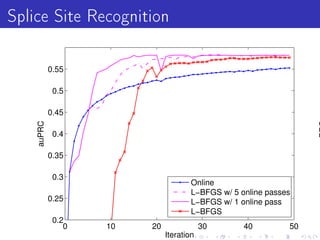
Vowpal Wabbit is a machine learning system that has four main goals: scalable and efficient machine learning, supporting new algorithm research, simplicity with few dependencies, and usability with minimal setup requirements. It uses several "tricks" like feature hashing and caching, online learning, and importance weighting to achieve scalability. It also supports newer algorithms like adaptive learning rates and dimensional correction. Vowpal Wabbit can be run in parallel on large clusters to handle terascale problems with billions of examples.








![The spam example [WALS09]
1 3.2 ∗ 106 labeled emails.
2 433167 users.
3 ∼ 40 ∗ 106 unique features.
How do we construct a spam lter which is personalized, yet
uses global information?](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-8-320.jpg)
![The spam example [WALS09]
1 3.2 ∗ 106 labeled emails.
2 433167 users.
3 ∼ 40 ∗ 106 unique features.
How do we construct a spam lter which is personalized, yet
uses global information?
Answer: Use hashing to predict according to:
w , φ(x ) + w , φ (x )
u](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-9-320.jpg)
![Basic Online Learning
Start with ∀i : w
i = 0, Repeatedly:
1 Get example x ∈ (∞, ∞)∗.
2 Make prediction y −
ˆ w x clipped to interval [0, 1].
i i i
3 Learn truth y ∈ [0, 1] with importance I or goto (1).
4 Update w ← w + η 2(y − y )Ix and go to (1).
i i ˆ i](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-11-320.jpg)




![Adaptive Learning [DHS10,MS10]
For example t , let g it = 2(y − y )xit .
ˆ](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-16-320.jpg)
![Adaptive Learning [DHS10,MS10]
For example t , let g it = 2(y − y )xit .
ˆ
New update rule: w i ← wi − η √Pit,t +1
g
2
t =1 git](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-17-320.jpg)
![Adaptive Learning [DHS10,MS10]
For example t , let g it = 2(y − y )xit .
ˆ
New update rule: w i ← wi − η √Pit,t +1
g
2
t =1 git
Common features stabilize quickly. Rare features can have
large updates.](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-18-320.jpg)
![Learning with importance weights [KL11]
y](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-19-320.jpg)
![Learning with importance weights [KL11]
wt x y](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-20-320.jpg)
![Learning with importance weights [KL11]
−η( ) x
wt x y](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-21-320.jpg)
![Learning with importance weights [KL11]
−η( ) x
wt x wt+1 x y](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-22-320.jpg)
![Learning with importance weights [KL11]
−6η( ) x
wt x y](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-23-320.jpg)
![Learning with importance weights [KL11]
−6η( ) x
wt x y wt+1 x ??](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-24-320.jpg)
![Learning with importance weights [KL11]
−η( ) x
wt x y wt+1 x](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-25-320.jpg)
![Learning with importance weights [KL11]
wt x wt+1 x y](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-26-320.jpg)
![Learning with importance weights [KL11]
s(h)||x||2
wt x wt+1 x y](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-27-320.jpg)
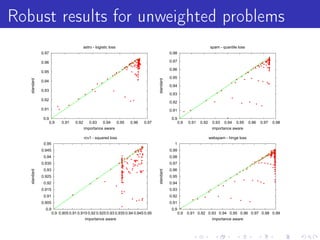



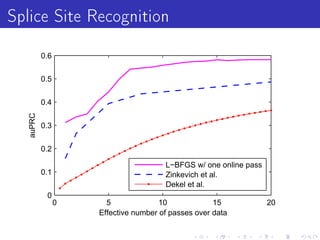
![LBFGS [Nocedal80]
Batch(!) second order algorithm. Core idea = ecient
approximate Newton step.](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-32-320.jpg)
![LBFGS [Nocedal80]
Batch(!) second order algorithm. Core idea = ecient
approximate Newton step.
H = ∂ (∂w (i ∂)−j )
2 f x y
2
= Hessian.
w w
Newton step = w → w + H −1g .](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-33-320.jpg)
![LBFGS [Nocedal80]
Batch(!) second order algorithm. Core idea = ecient
approximate Newton step.
H = ∂ (∂w (i ∂)−j )
2 f x y
2
= Hessian.
w w
Newton step = w → w + H −1g .
Newton fails: you can't even represent H.
Instead build up approximate inverse Hessian according to:
∆w ∆Tw where ∆ is a change in weights
∆T ∆g
w w w
and ∆g is a change
in the loss gradient g.](https://image.slidesharecdn.com/jlddmvw-120503135745-phpapp01/85/Technical-Tricks-of-Vowpal-Wabbit-34-320.jpg)

































































![[Harvard CS264] 09 - Machine Learning on Big Data: Lessons Learned from Googl...](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
























































