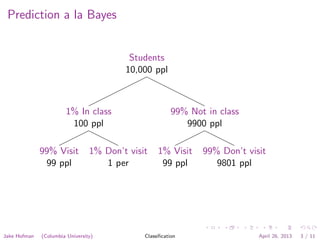
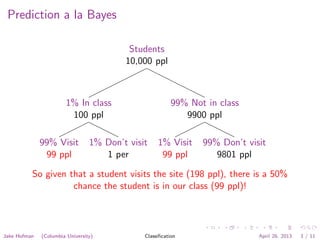
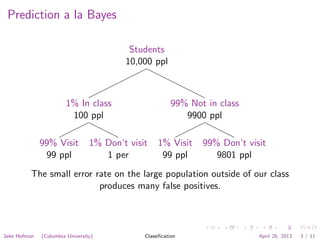
The document discusses the Naive Bayes classification algorithm. It explains how Naive Bayes can be used to classify students based on whether they visit an online course site. It describes representing each student as a binary vector indicating which sites they visited. The algorithm then treats site visits as independent Bernoulli trials to calculate the probability that a student is in a particular class based on the sites they visited. The document outlines how to estimate the model parameters from training data and use the model to make predictions.

































![Conferencia educación católica versión final - abril 24, 2009..[1]](https://cdn.slidesharecdn.com/ss_thumbnails/conferenciaeducacincatlica-versinfinal-abril242009-1-100218133542-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



























































