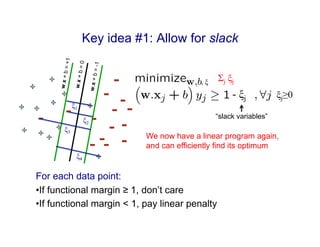
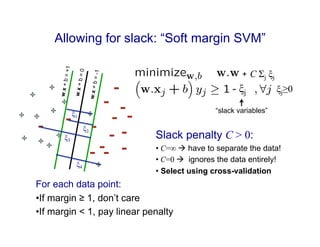
Support vector machines (SVMs) find the optimal separating hyperplane between two classes of data points that maximizes the margin between the classes. SVMs address nonlinear classification problems by using kernel functions to implicitly map inputs into high-dimensional feature spaces. The three key ideas of SVMs are: 1) Allowing for misclassified points using slack variables. 2) Seeking a large margin hyperplane for better generalization. 3) Using the "kernel trick" to efficiently perform computations in high-dimensional feature spaces without explicitly computing the mappings.







![• Try to find weights that violate as few
constraints as possible?
• Formalize this using the 0-1 loss:
• Unfortunately, minimizing 0-1 loss is
NP-hard in the worst-case
– Non-starter. We need another
approach.
#(mistakes)
Minimizing number of errors (0-1 loss)
min
w,b
X
j
`0,1(yj, w · xj + b)
where `0,1(y, ŷ) = 1[y 6= sign(ŷ)]](https://image.slidesharecdn.com/svmnotes-240316170455-f85acd4d/85/Notes-relating-to-Machine-Learning-and-SVM-8-320.jpg)


![Hinge loss vs. 0/1 loss
1
0
1
Hinge loss upper bounds 0/1 loss!
It is the tightest convex upper bound on the 0/1 loss
Hinge loss:
`hinge(y, ŷ) = max
⇣
0, 1 ŷy
⌘
0-1 Loss:
`0,1(y, ŷ) = 1[y 6= sign(ŷ)]](https://image.slidesharecdn.com/svmnotes-240316170455-f85acd4d/85/Notes-relating-to-Machine-Learning-and-SVM-12-320.jpg)






![[Tommi Jaakkola]
Example](https://image.slidesharecdn.com/svmnotes-240316170455-f85acd4d/85/Notes-relating-to-Machine-Learning-and-SVM-20-320.jpg)









![[Tommi Jaakkola]
Quadratic kernel](https://image.slidesharecdn.com/svmnotes-240316170455-f85acd4d/85/Notes-relating-to-Machine-Learning-and-SVM-30-320.jpg)
![Quadratic kernel
[Cynthia Rudin]
Feature mapping given by:](https://image.slidesharecdn.com/svmnotes-240316170455-f85acd4d/85/Notes-relating-to-Machine-Learning-and-SVM-31-320.jpg)















































