Downloaded 46 times






















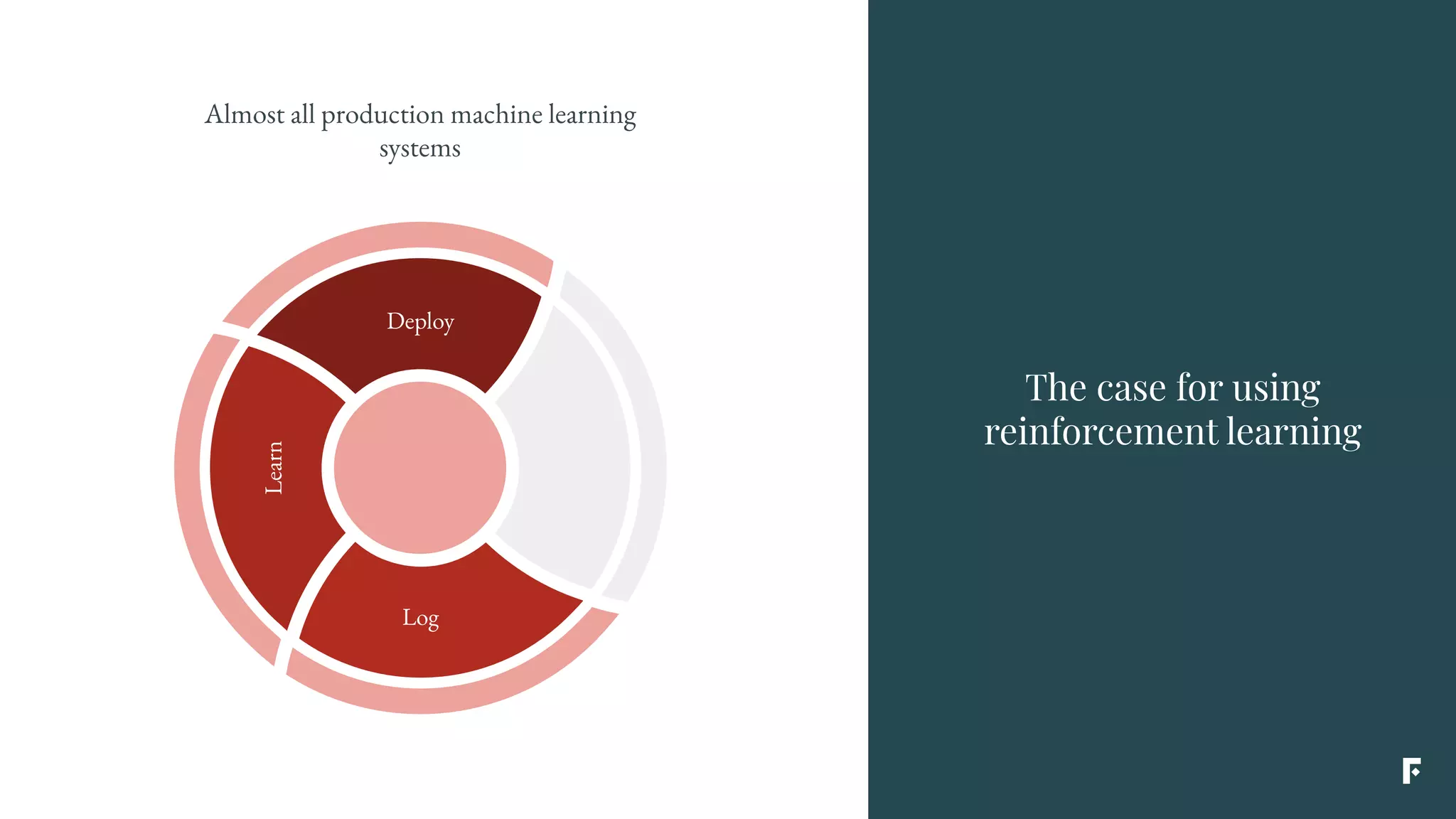
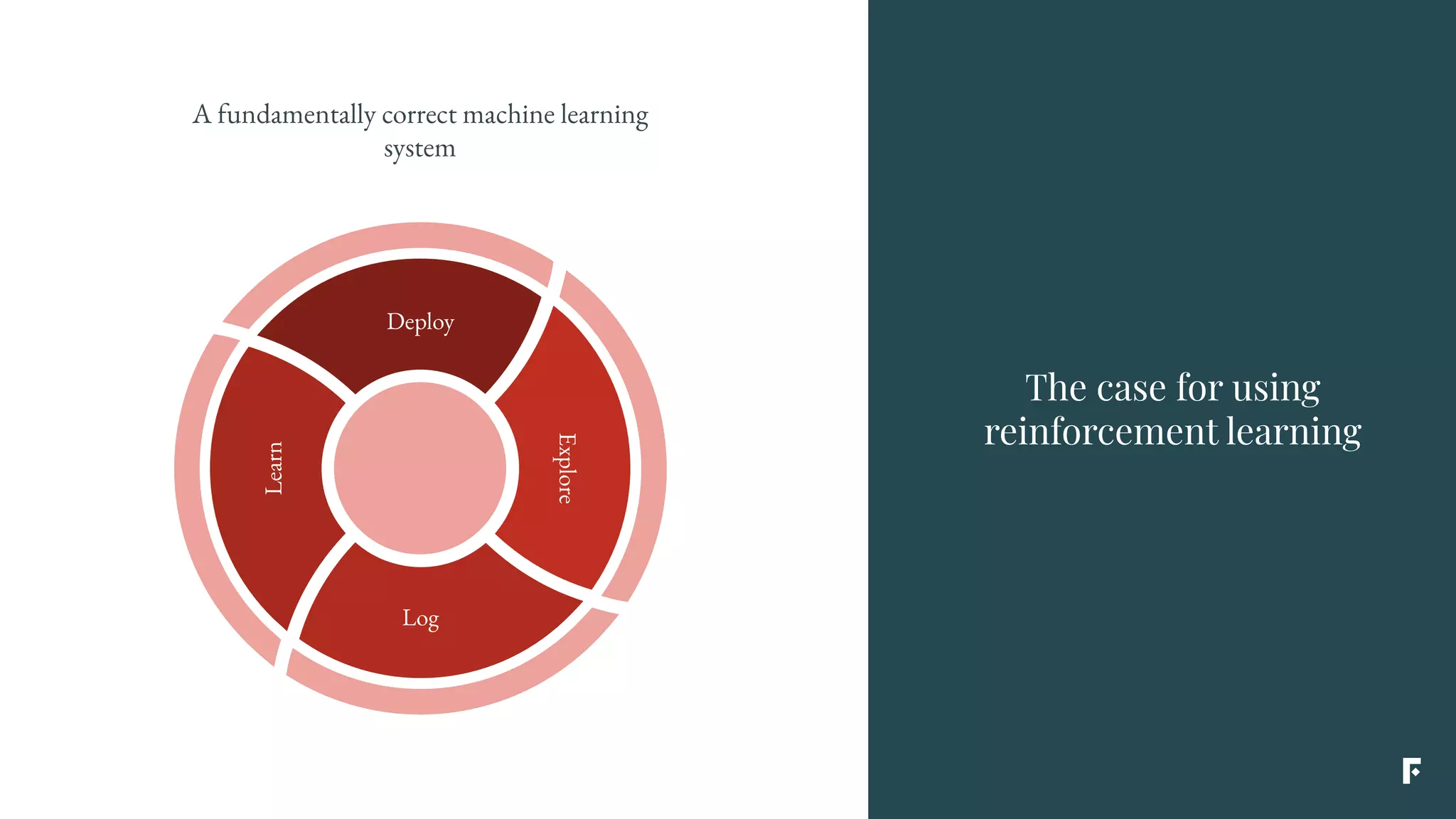





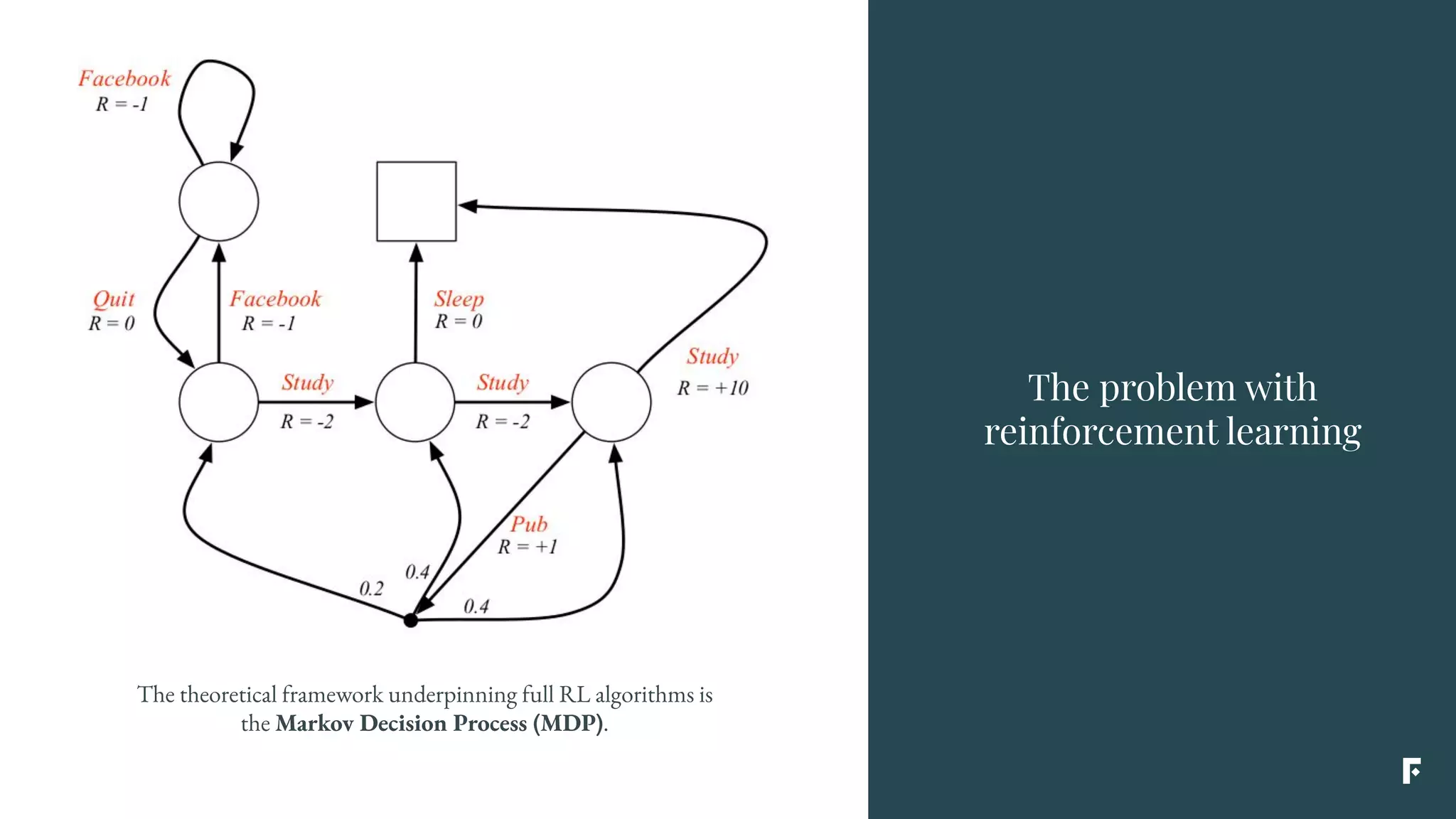
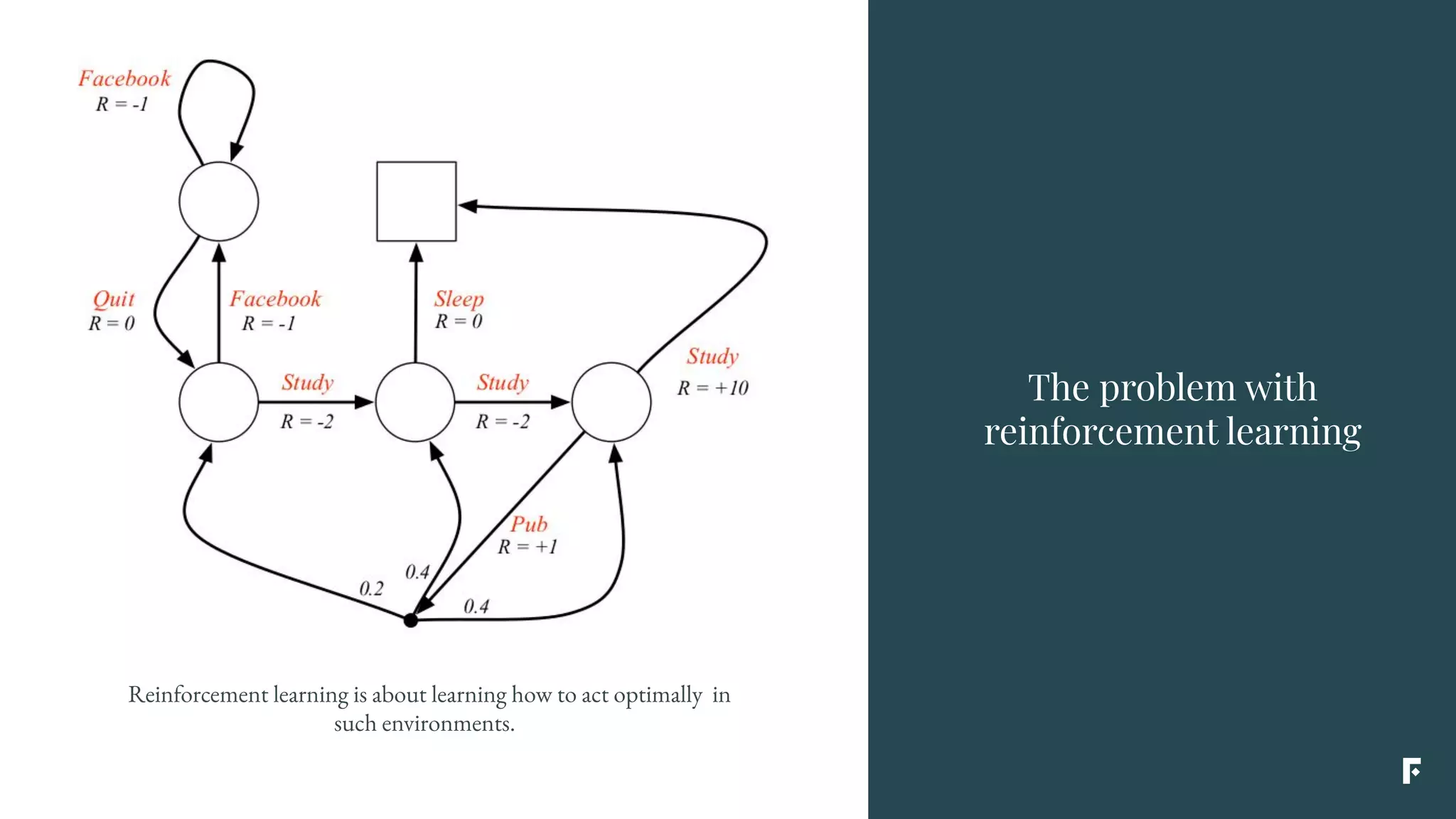
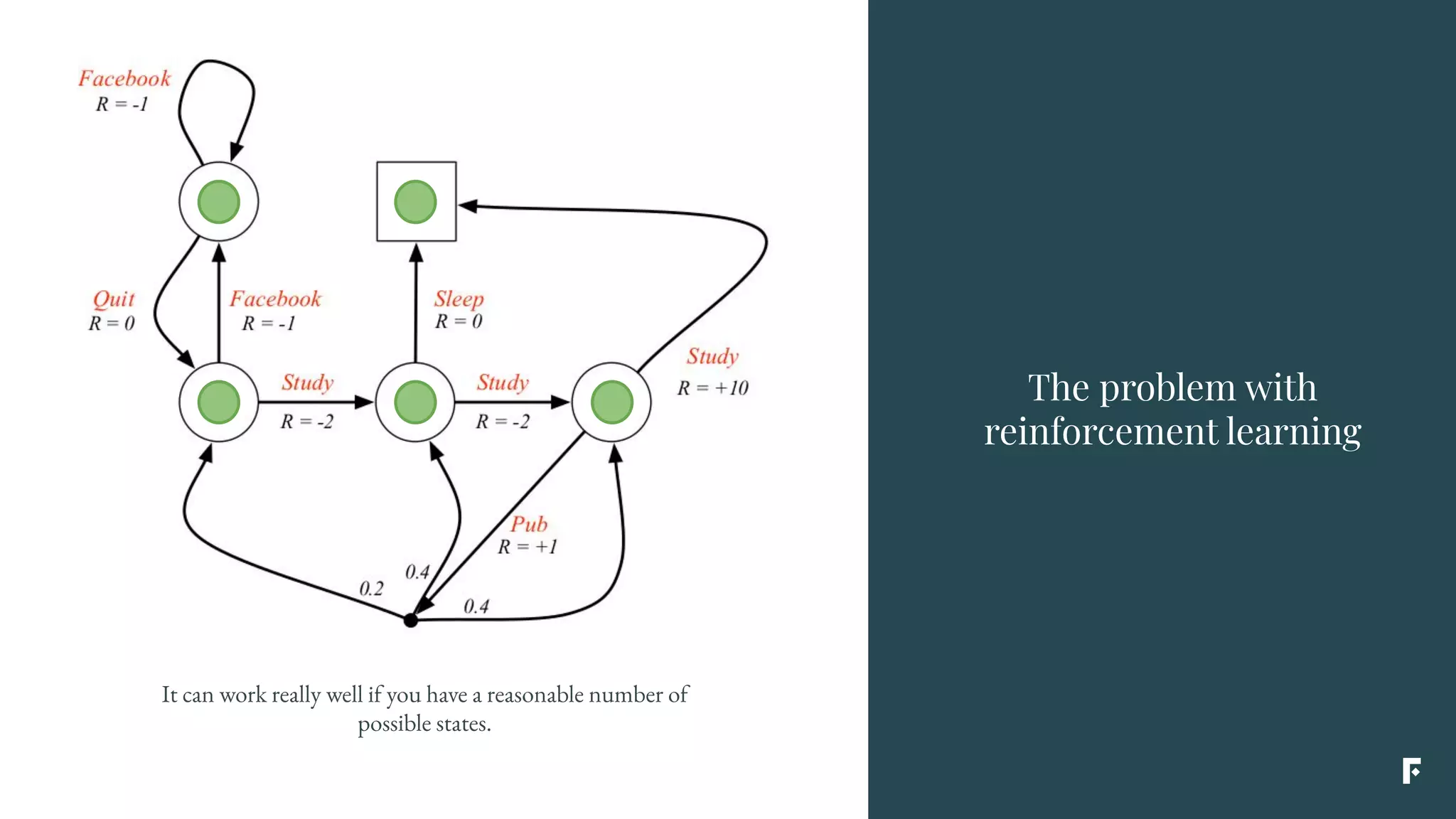




















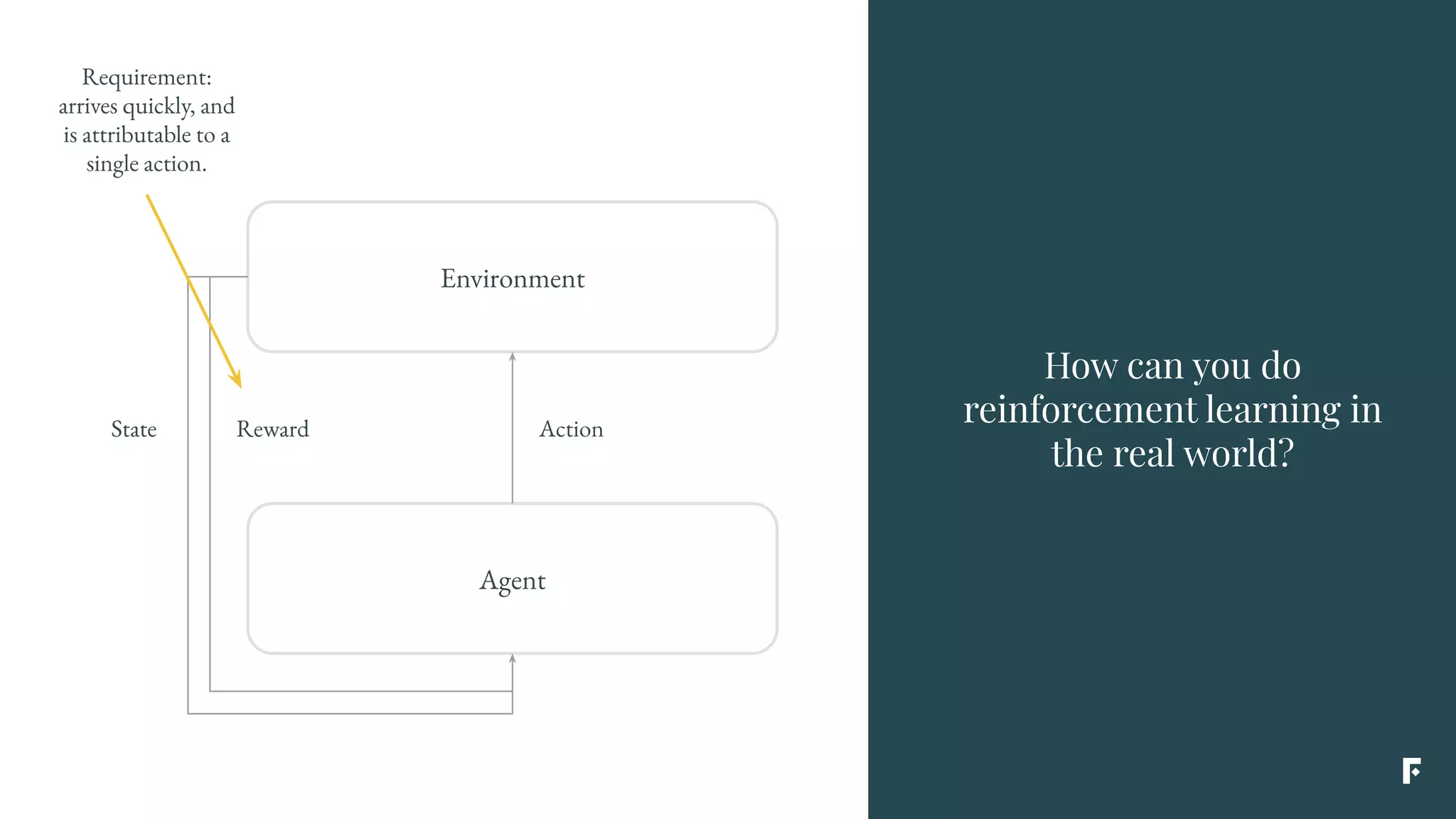



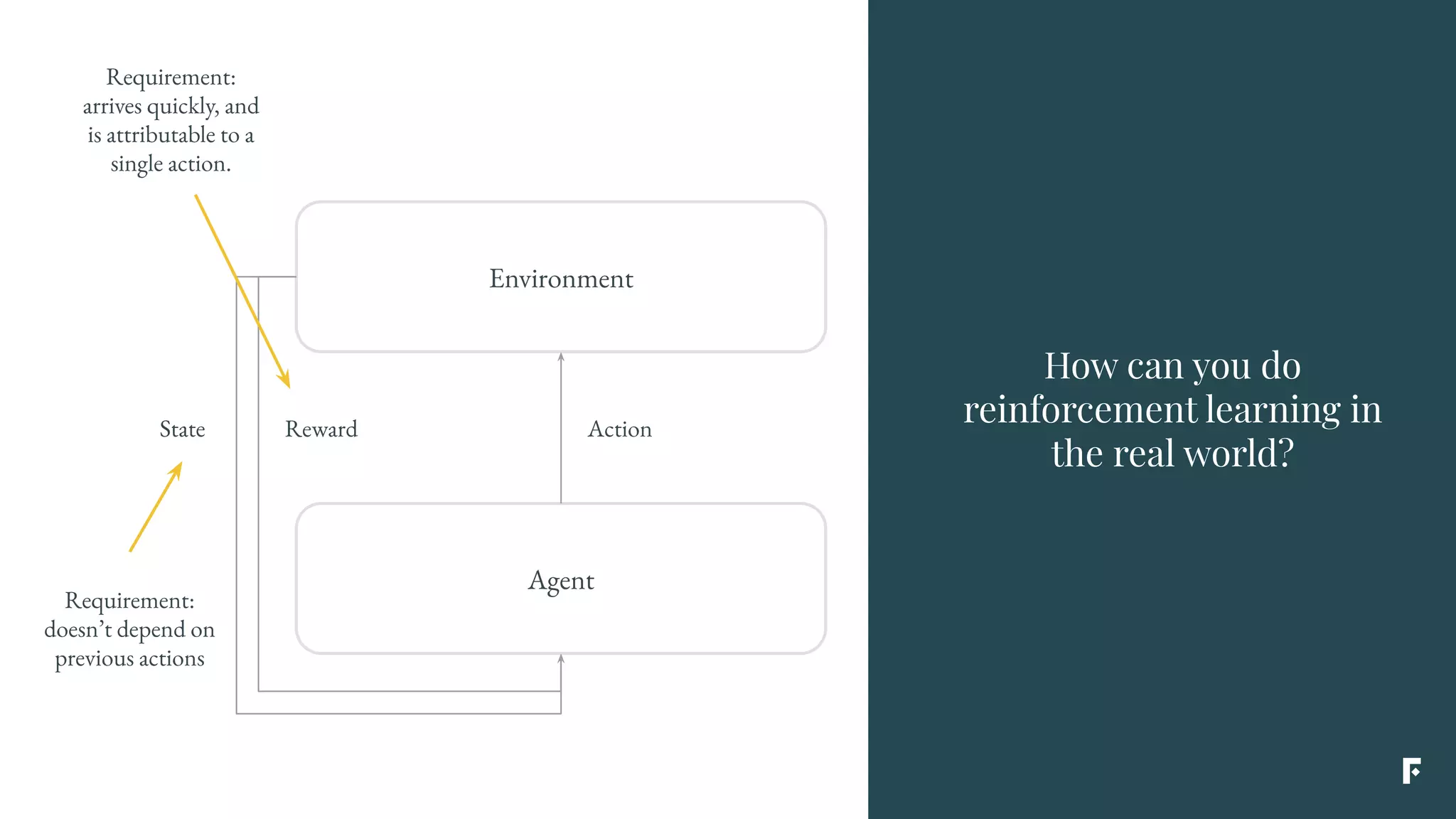















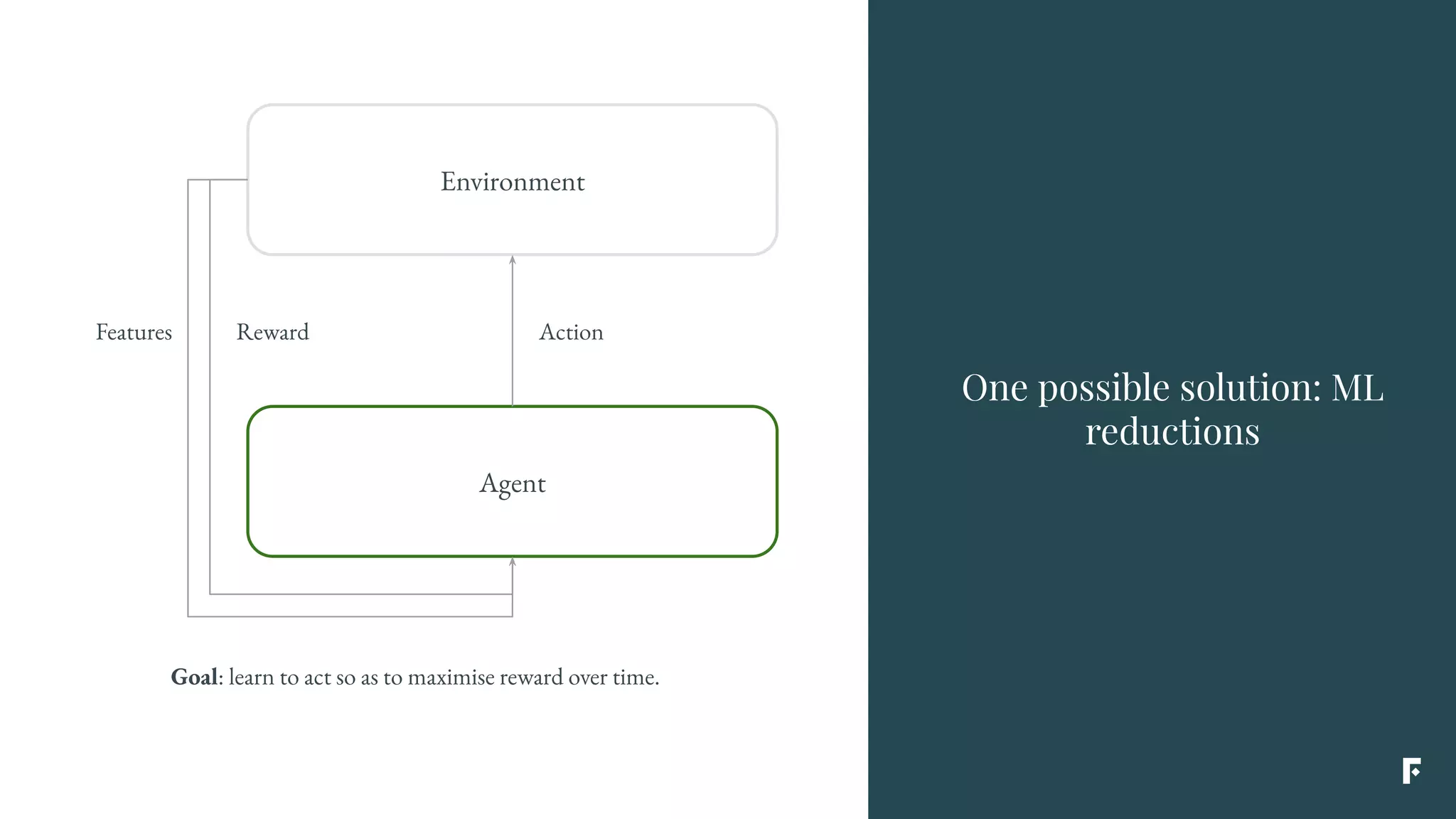
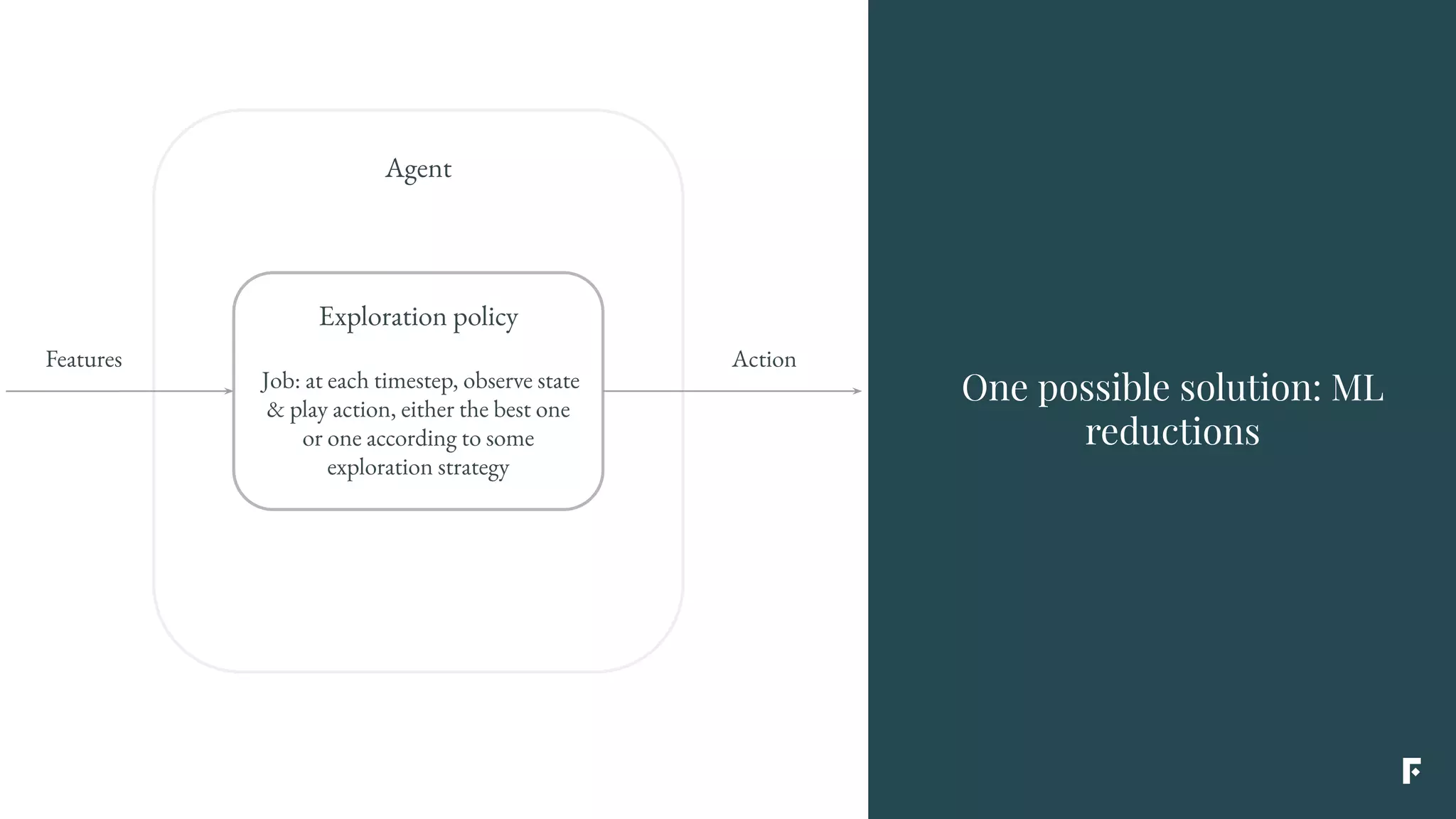
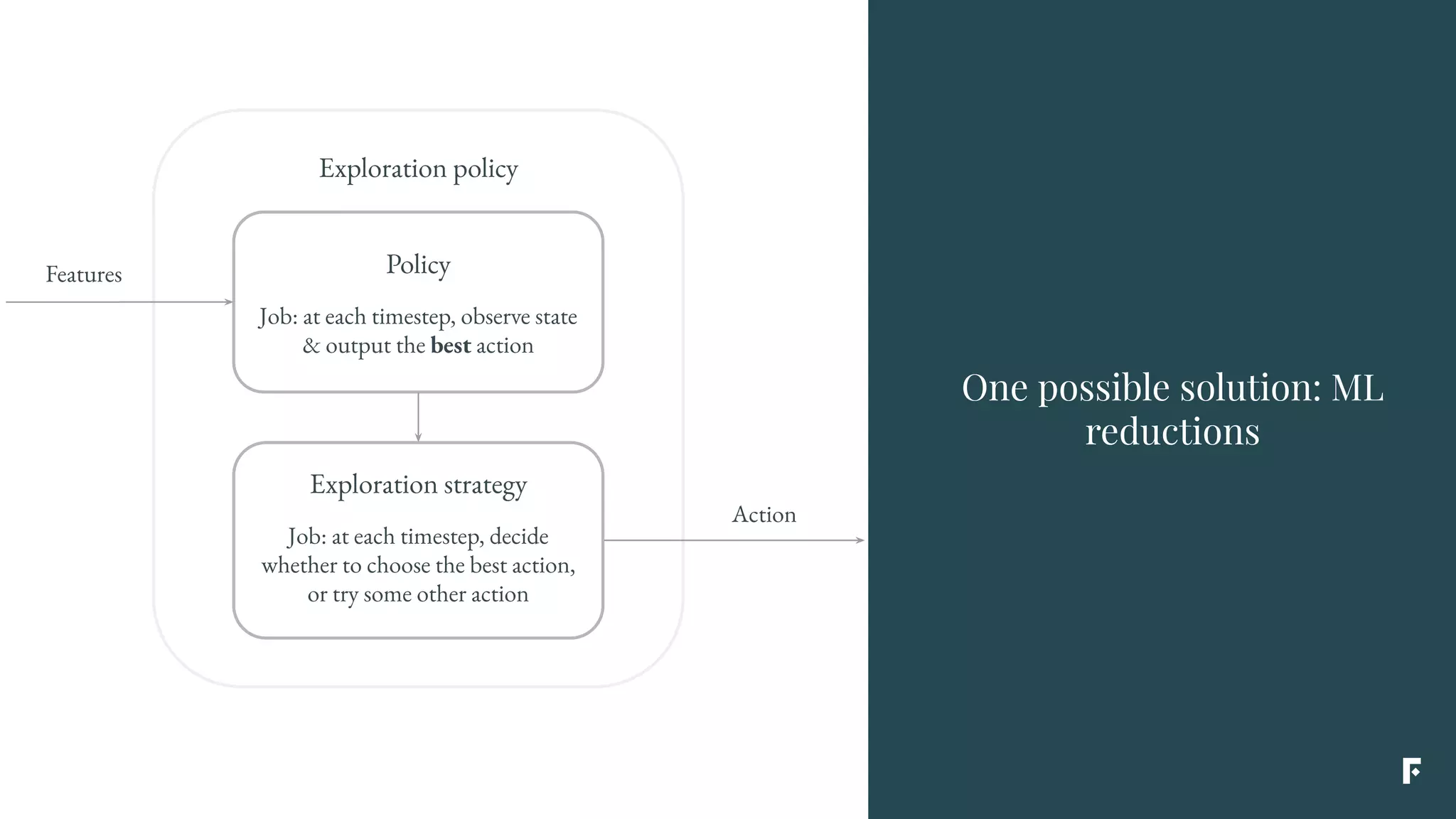







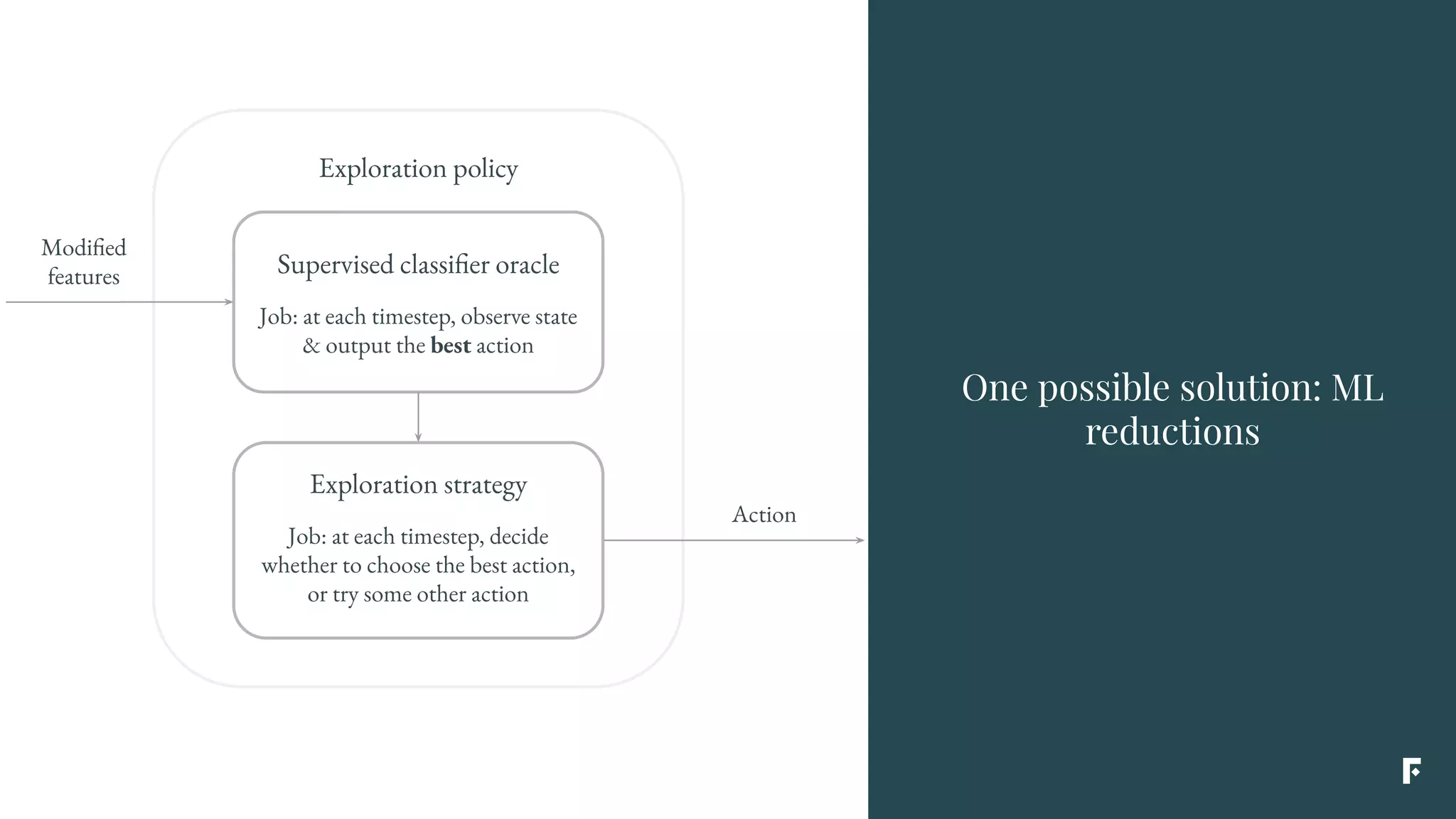

















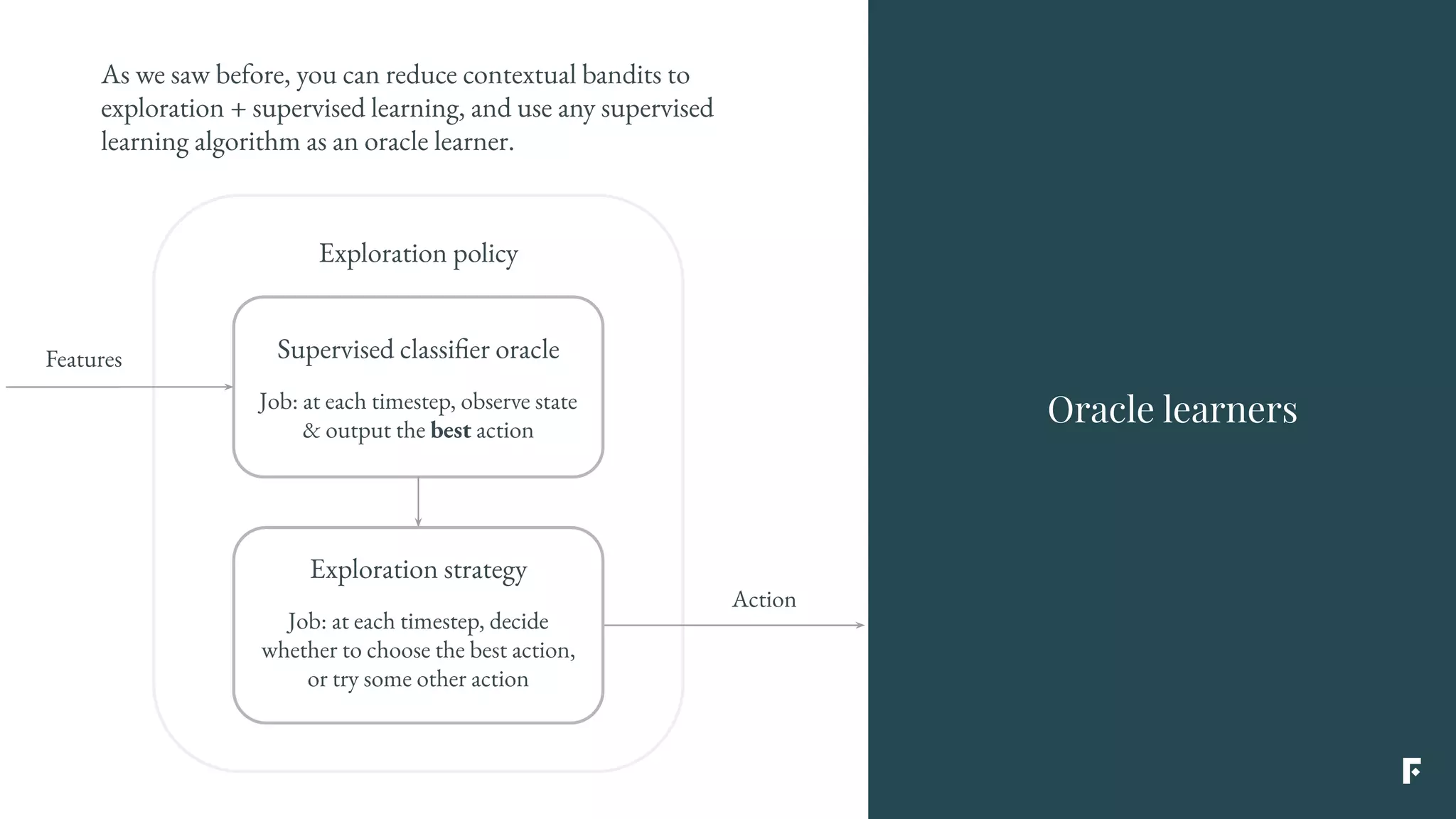
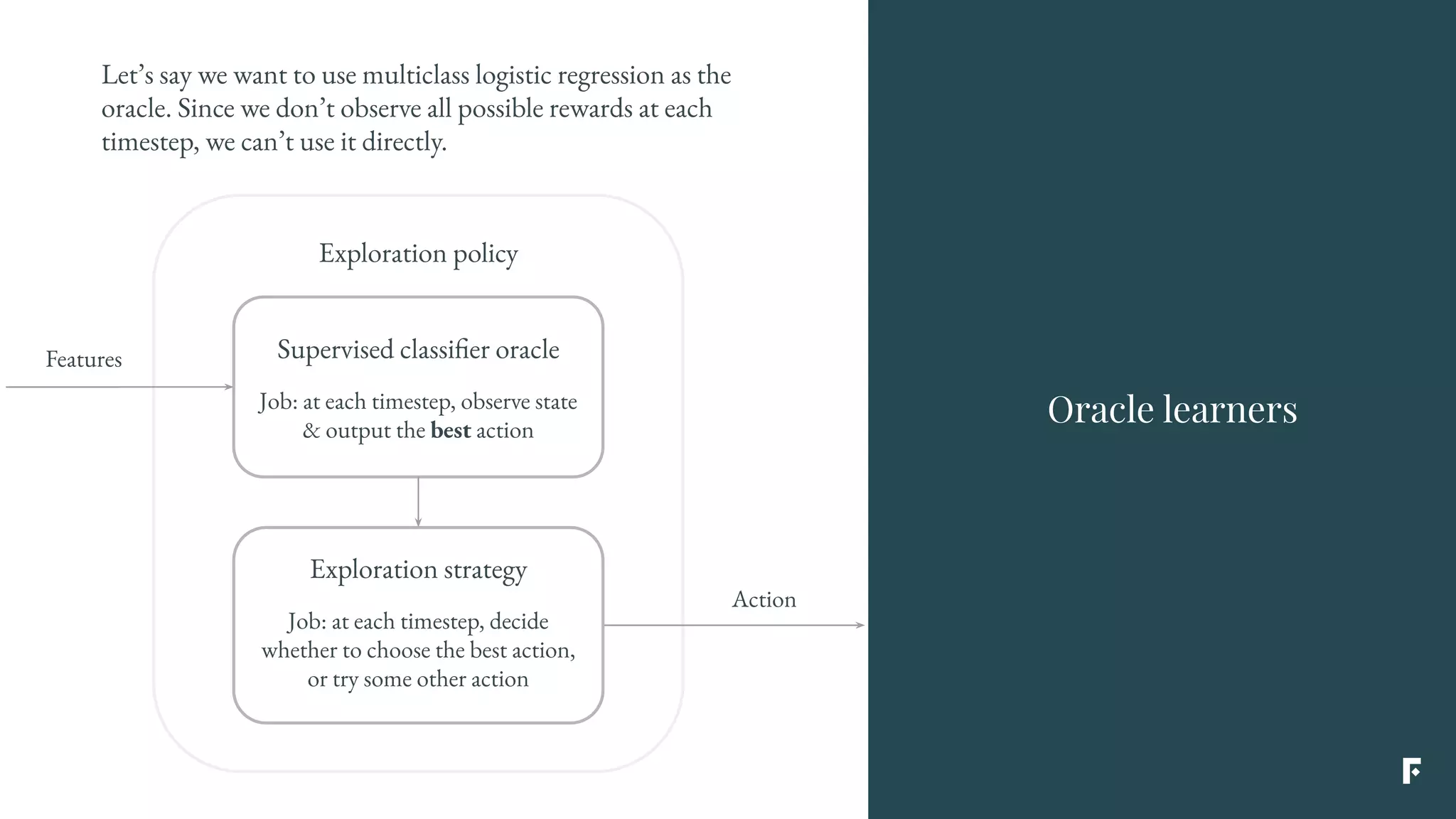
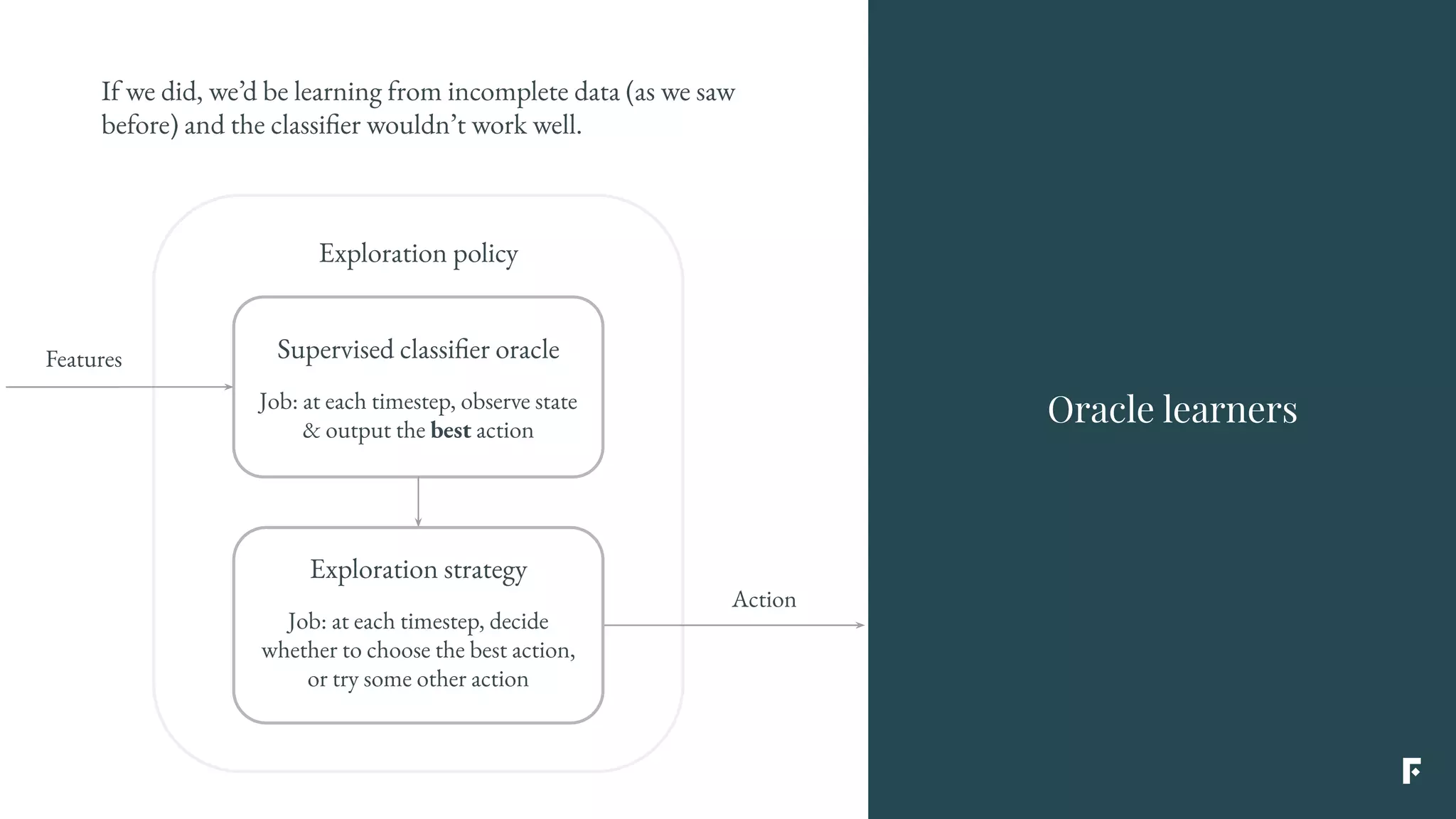
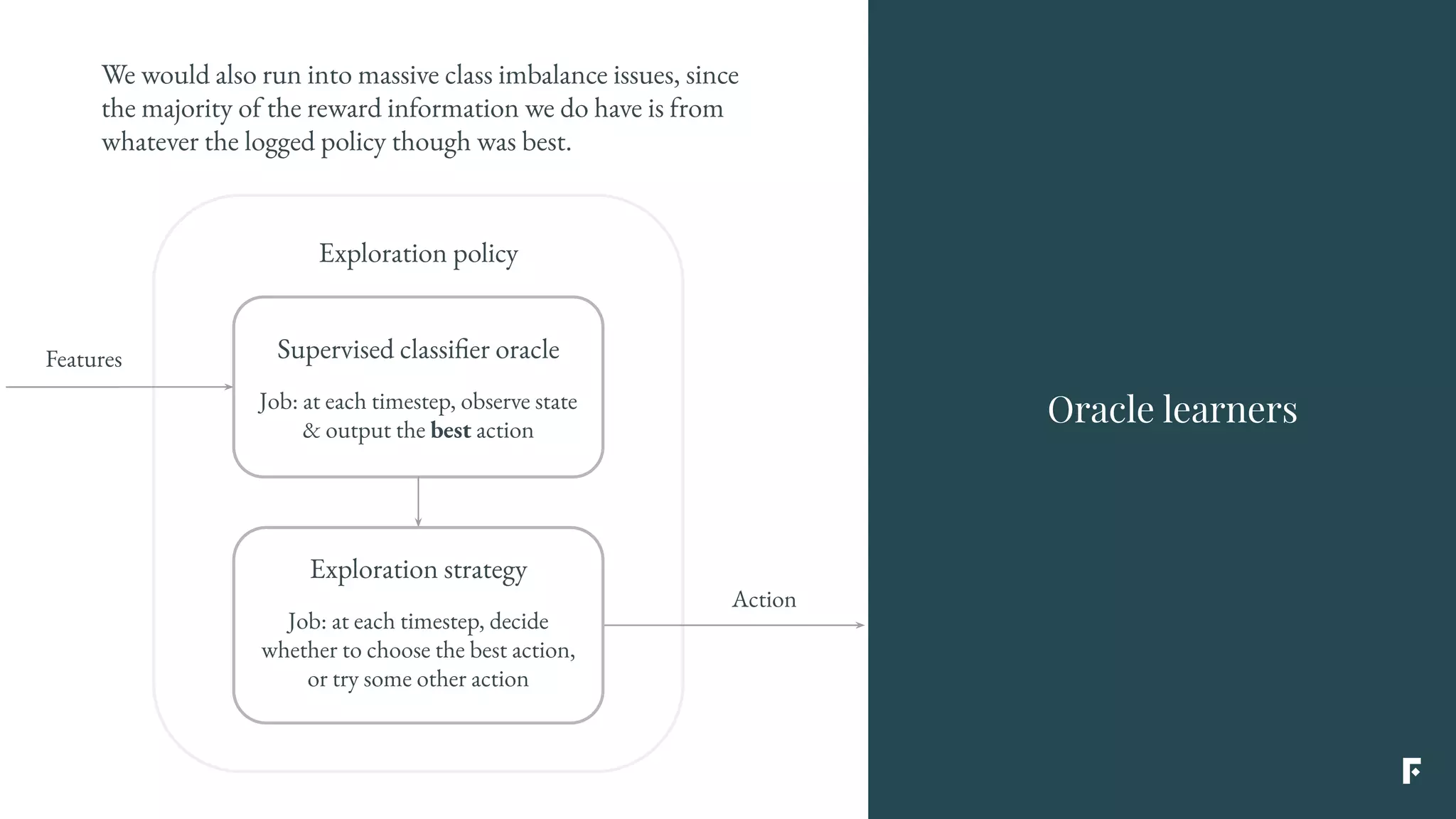
























This document discusses how reinforcement learning can be applied in the real world through simplifications and reductions. Reinforcement learning is challenging to apply to real-world problems due to issues like large state spaces requiring massive amounts of data and delayed rewards. However, it can be simplified by focusing on problems with immediate rewards attributable to single actions and state independence. This reduced problem is known as contextual bandits. Contextual bandits can be solved using machine learning reductions by treating the agent policy as a classifier and filling in missing reward information to allow supervised learning techniques to be applied. This involves reducing contextual bandits to supervised learning plus an exploration strategy, allowing any classification algorithm to be used as an "oracle learner" for the



































































