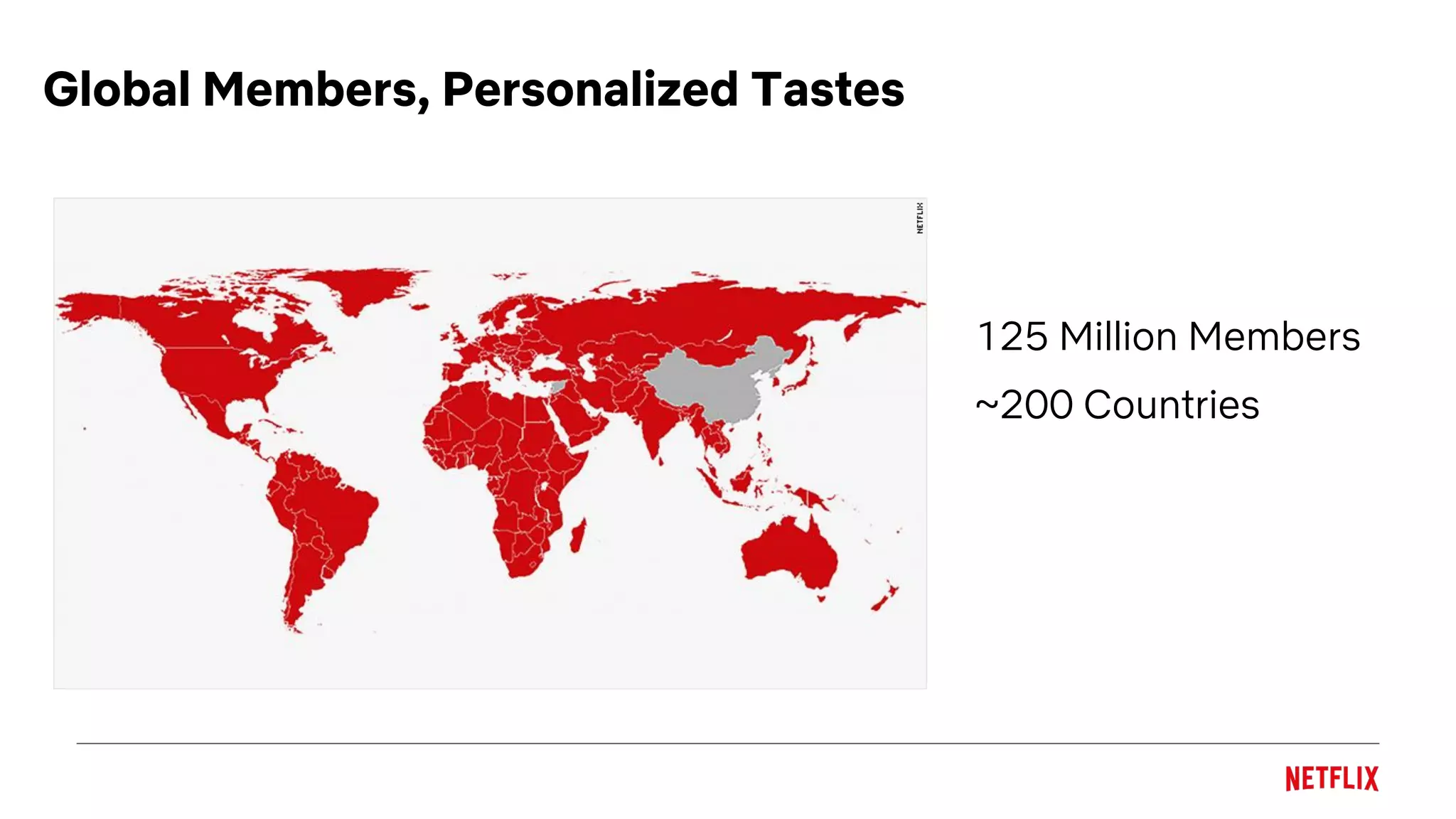
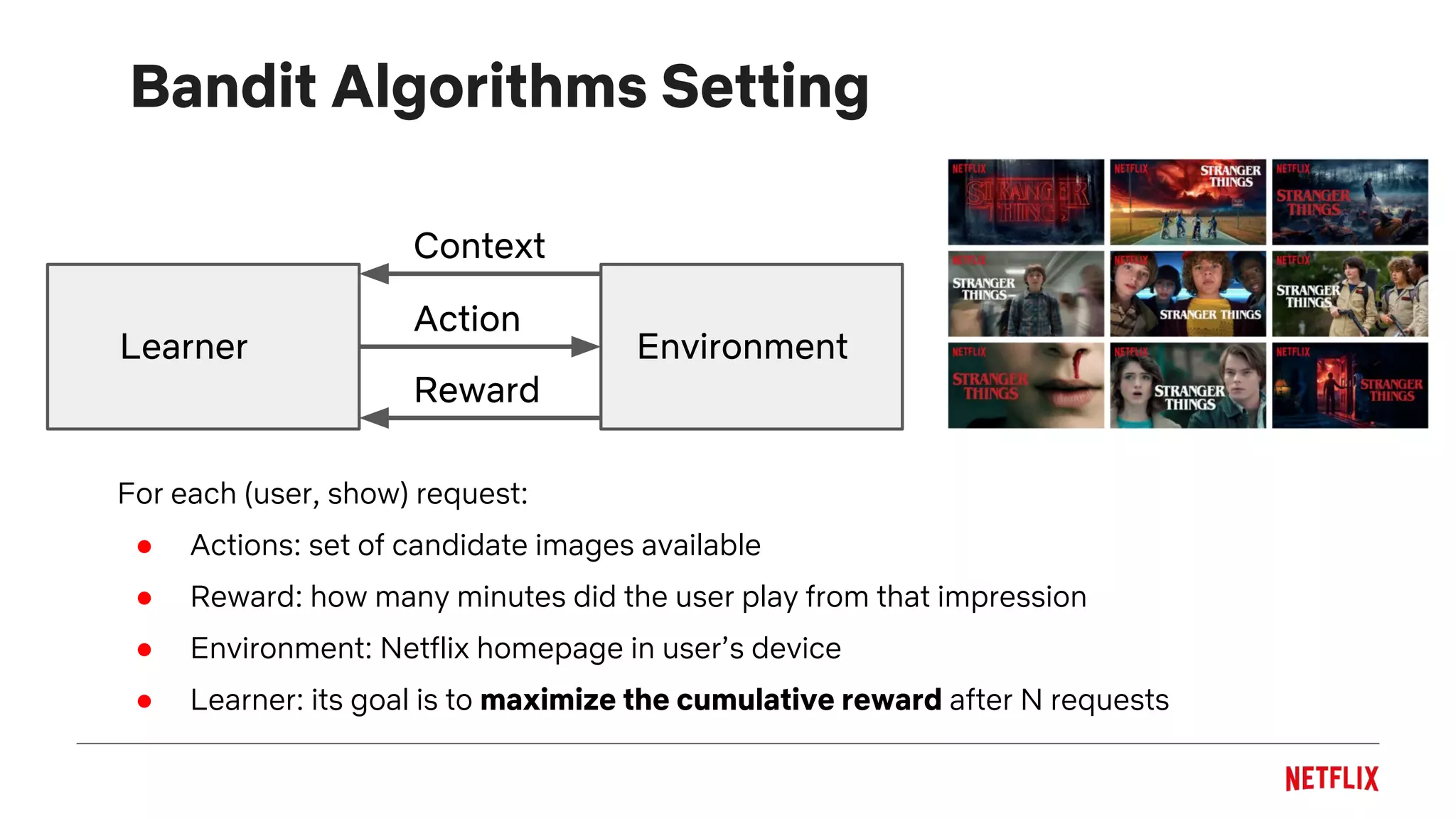
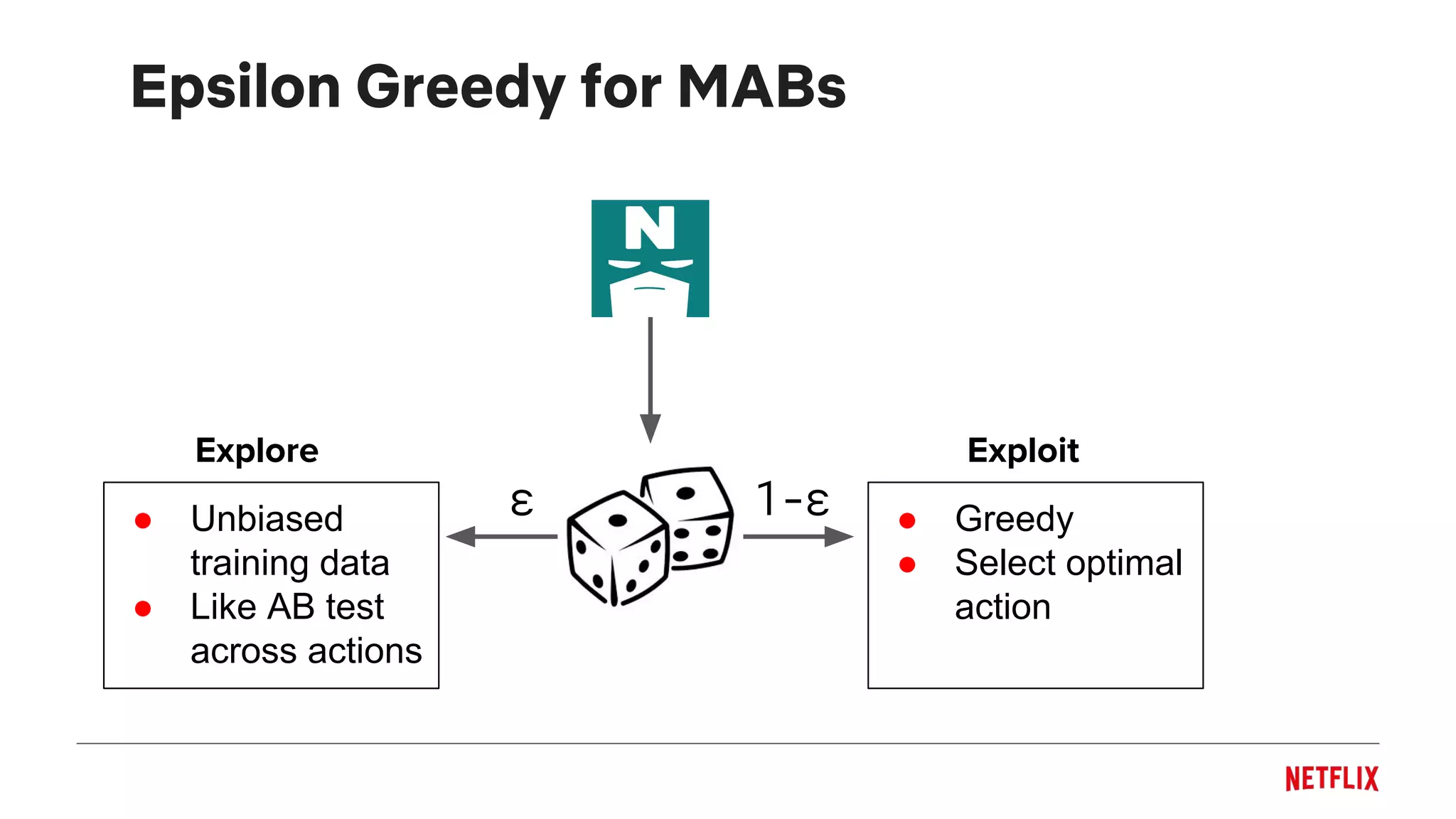
The document discusses the application of a multi-armed bandit framework for improving content recommendations at Netflix, focusing on case studies for artwork optimization and billboard recommendation. It highlights challenges faced by traditional recommendation methods, the exploration-exploitation tradeoff, and various bandit algorithms used for enhancing user engagement. The findings suggest that personalized recommendations, particularly for lesser-known titles, significantly improve user interaction compared to random selections.



















![● Unbiased offline evaluation from explore data
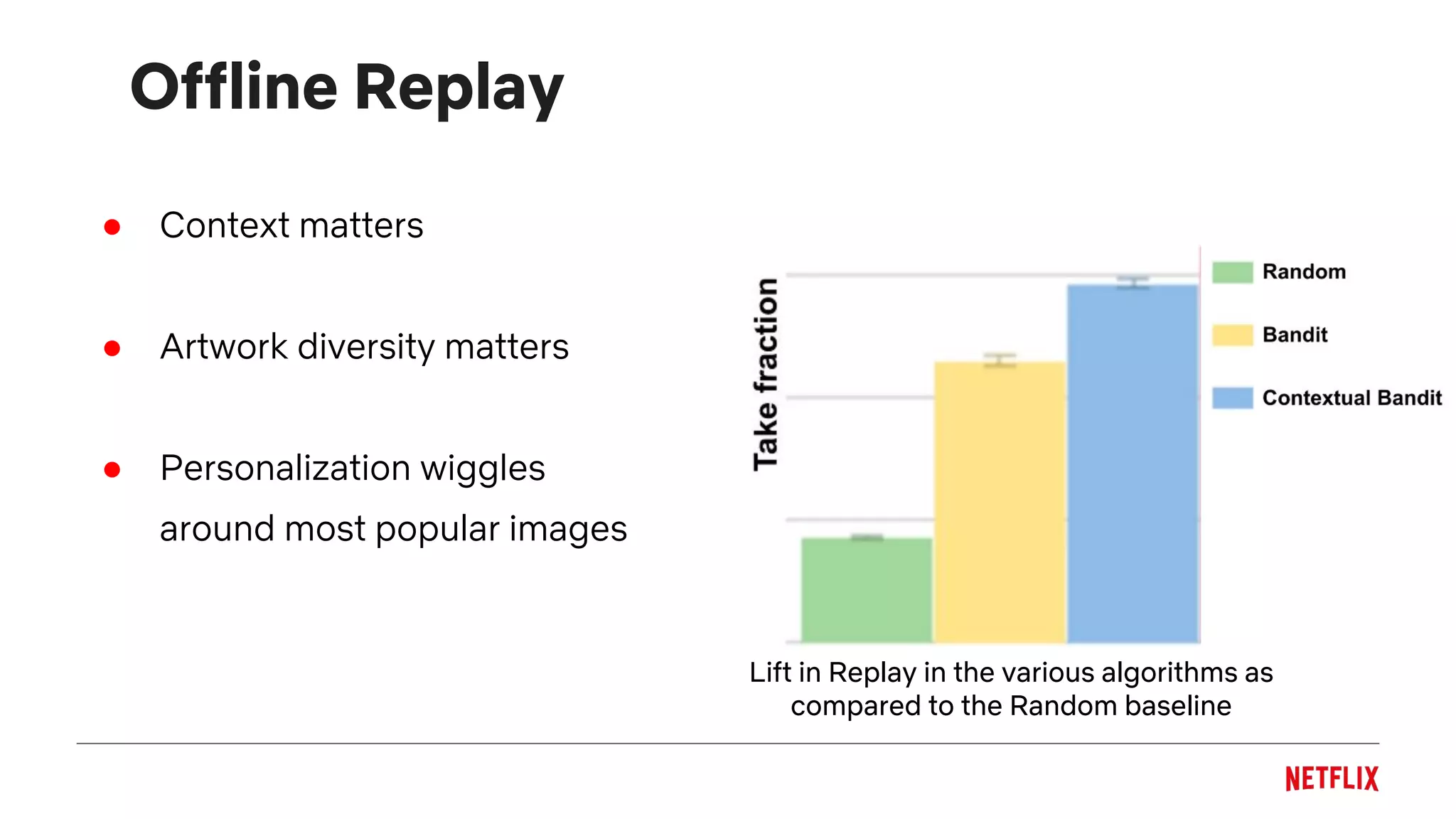
Offline metric: Replay [Li et al, 2010]
Offline Take Fraction = 2 / 3
User 1 User 2 User 3 User 4 User 5 User 6
Random Assignment
Play?
Model Assignment](https://image.slidesharecdn.com/prs-bandits-jun2018-180618235026/75/A-Multi-Armed-Bandit-Framework-For-Recommendations-at-Netflix-27-2048.jpg)
































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















