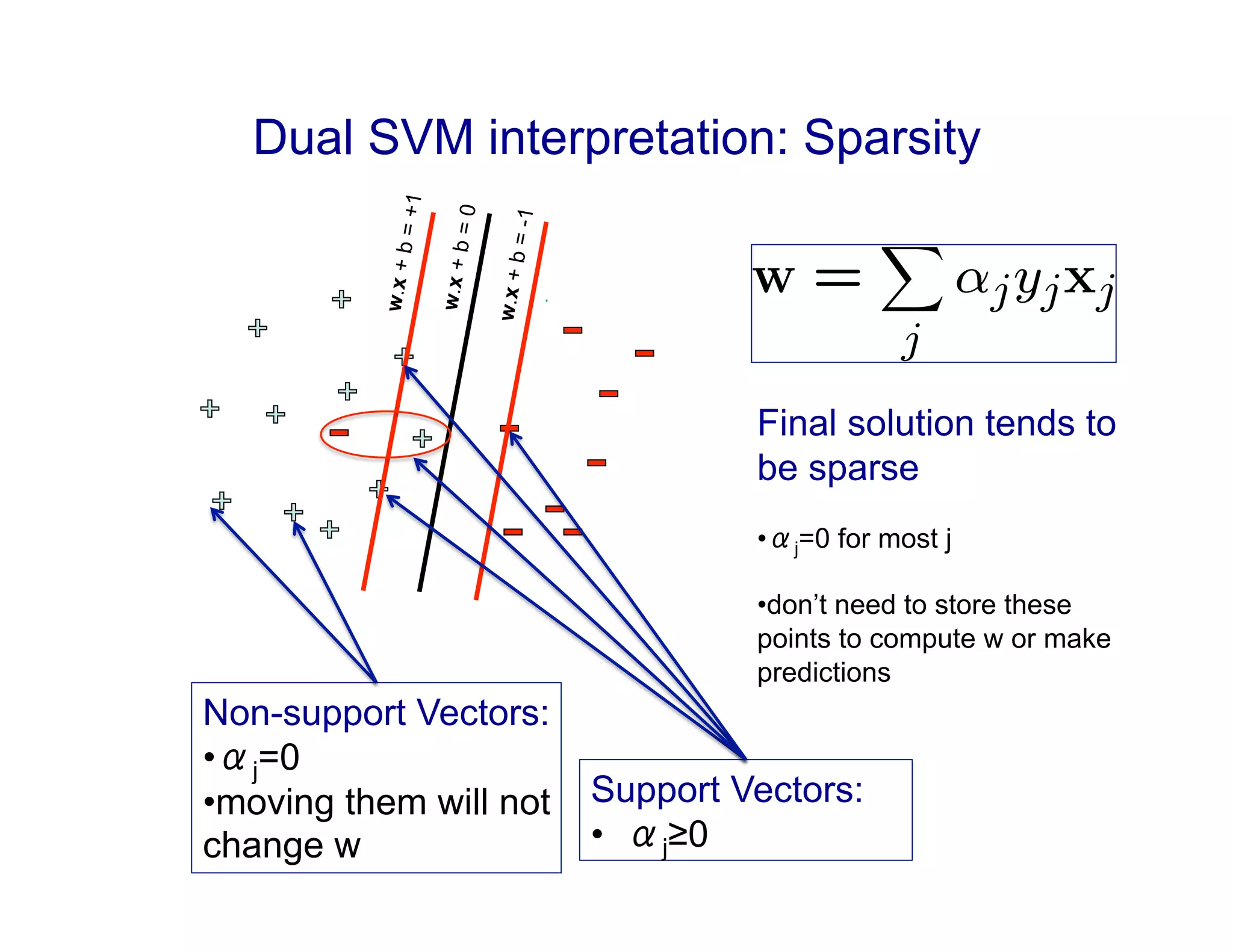
1) The document discusses support vector machines and kernels. It covers the derivation of the dual formulation of SVMs, which allows solving directly for the α values rather than w and b.
2) It explains how kernels can be used to transform data into a higher dimensional feature space without explicitly computing the features. Common kernels discussed include polynomial and Gaussian kernels.
3) The document notes that while kernels create a huge feature space, SVMs seek a large margin solution to generalize well, but overfitting can still occur and needs to be controlled through parameters like C and the kernel.










![[Tommi Jaakkola]
Quadratic kernel](https://image.slidesharecdn.com/dualsvmproblem-220719165208-e56457b5/75/Dual-SVM-Problem-pdf-12-2048.jpg)
![Quadratic kernel
[Cynthia Rudin]
Feature mapping given by:](https://image.slidesharecdn.com/dualsvmproblem-220719165208-e56457b5/75/Dual-SVM-Problem-pdf-13-2048.jpg)

![Gaussian kernel
[Cynthia Rudin] [mblondel.org]
Support vectors
Level sets, i.e. w.x=r for some r](https://image.slidesharecdn.com/dualsvmproblem-220719165208-e56457b5/75/Dual-SVM-Problem-pdf-15-2048.jpg)
![Kernel algebra
[Justin Domke]
Q: How would you prove that the “Gaussian kernel” is a valid kernel?
A: Expand the Euclidean norm as follows:
Then, apply (e) from above
To see that this is a kernel, use the
Taylor series expansion of the
exponential, together with repeated
application of (a), (b), and (c):
The feature mapping is
infinite dimensional!](https://image.slidesharecdn.com/dualsvmproblem-220719165208-e56457b5/75/Dual-SVM-Problem-pdf-16-2048.jpg)


















































![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)

