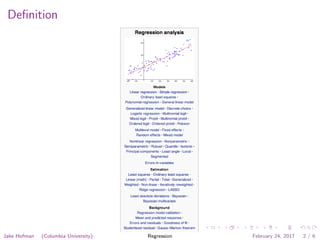
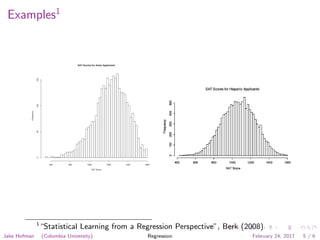
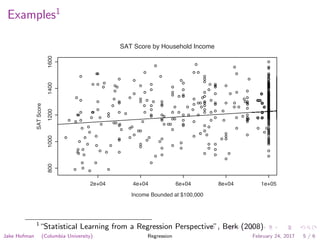
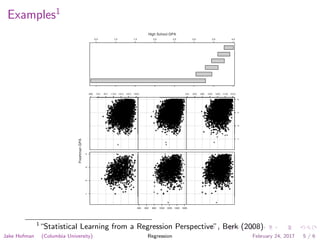
This document discusses regression analysis as presented by Jake Hofman of Columbia University. It defines regression as understanding how a response variable varies across subgroups based on predictor variables. The goals of regression are to describe outcomes under different conditions, predict future outcomes, and explain associations between predictors and outcomes. Examples shown include comparing SAT score distributions between ethnic groups and examining the relationship between SAT scores and household income. The framework for regression involves specifying the outcome and predictors, defining a loss function, fitting the model to minimize loss, and assessing performance.