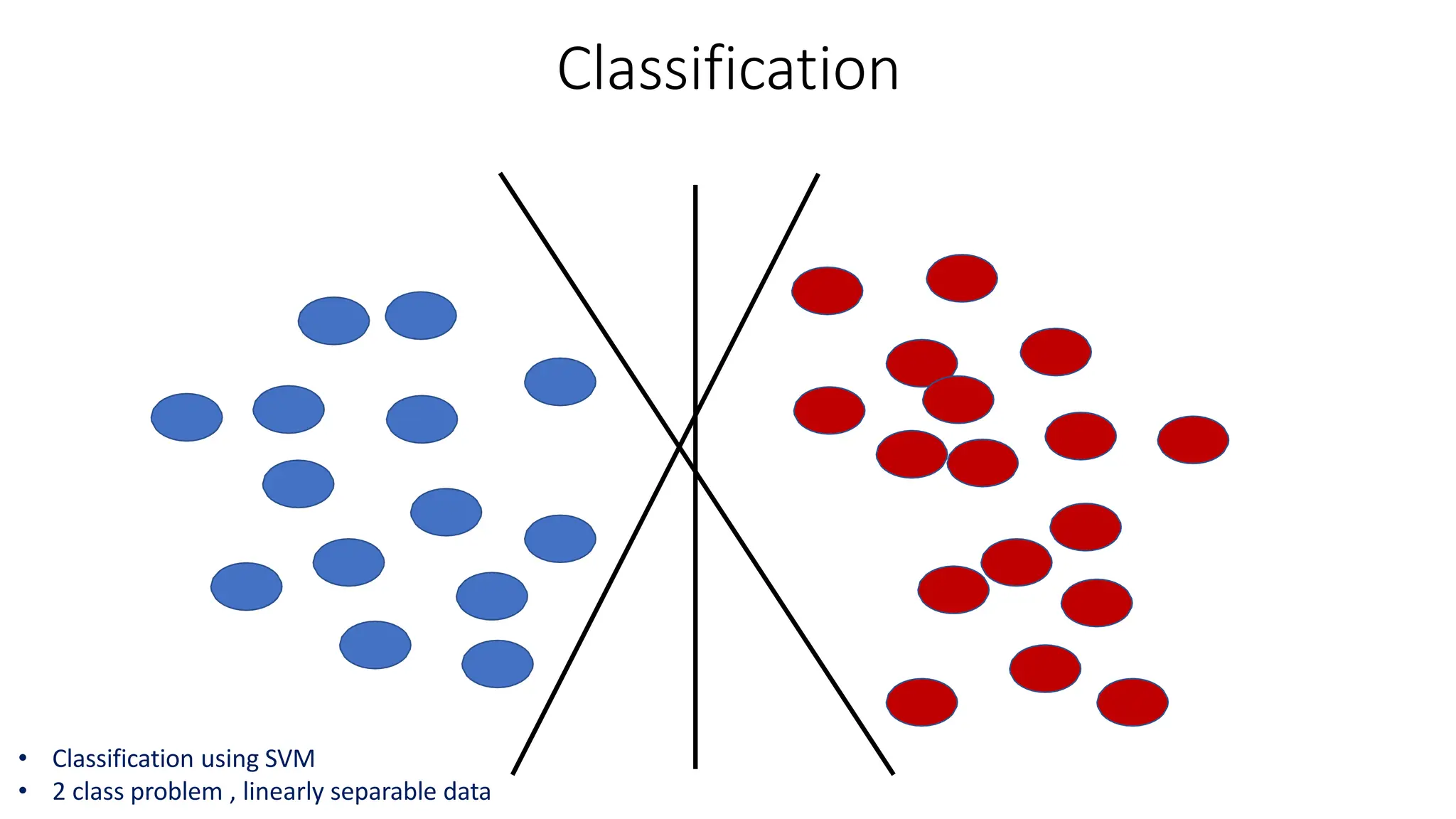
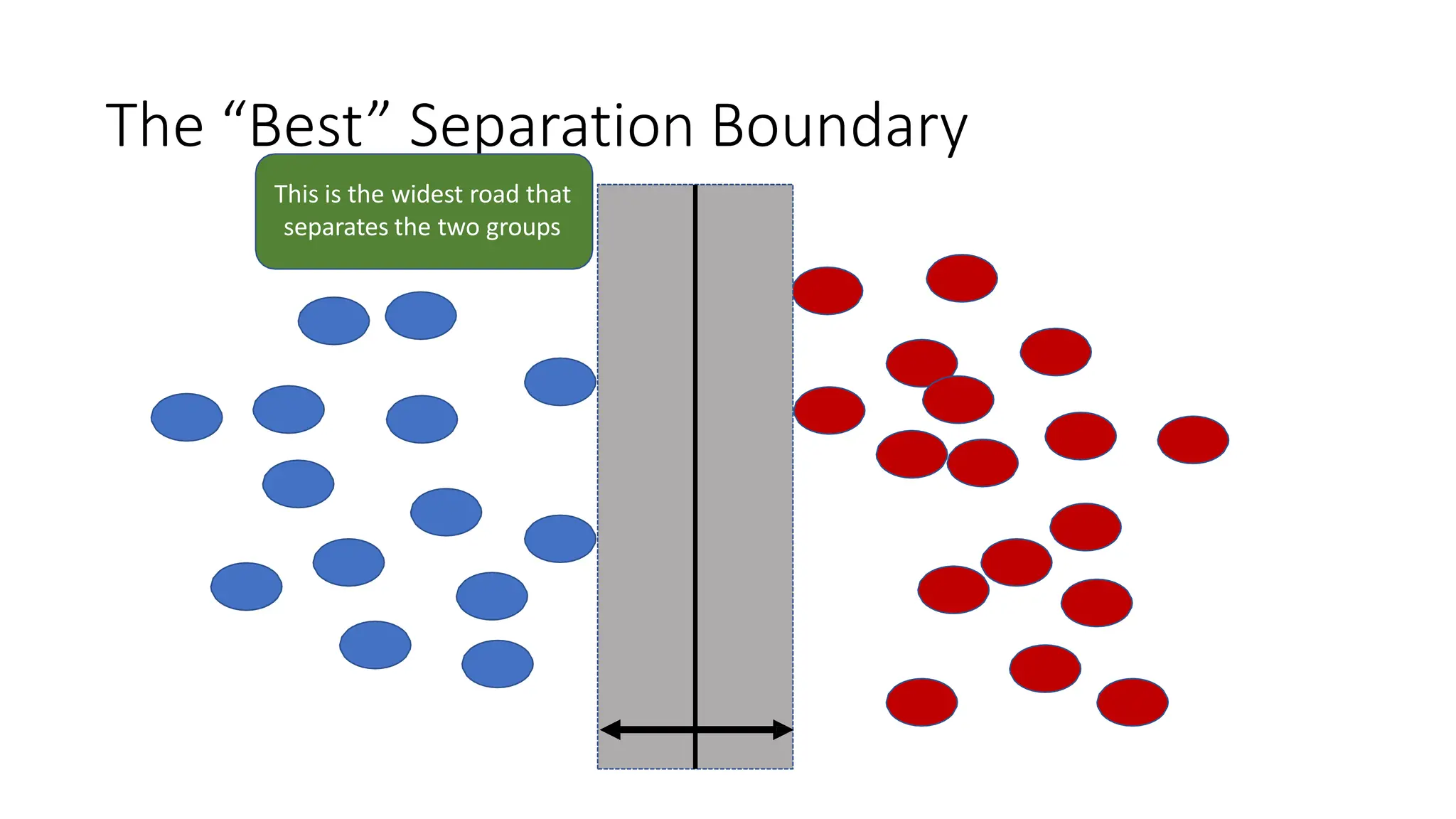
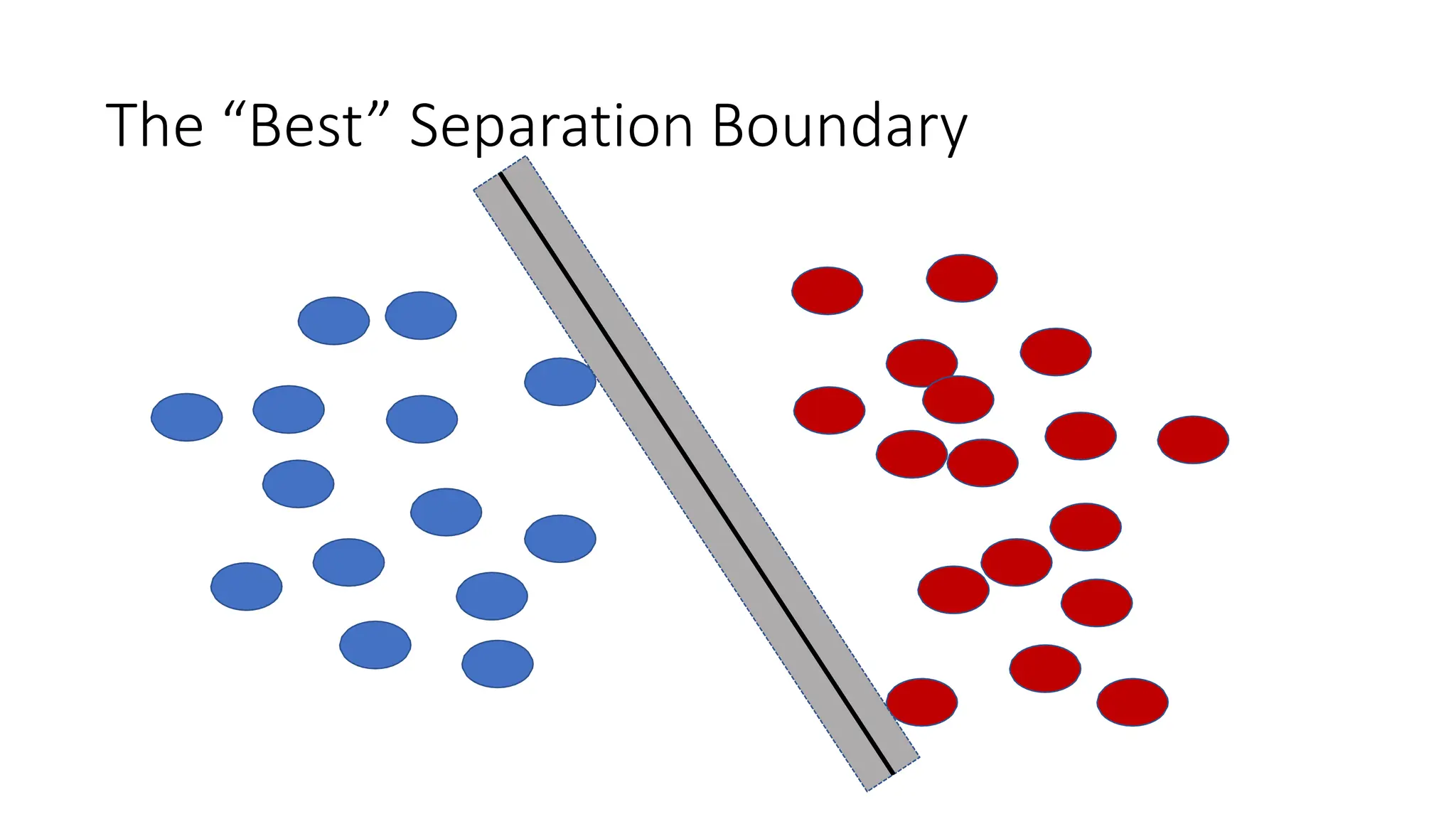
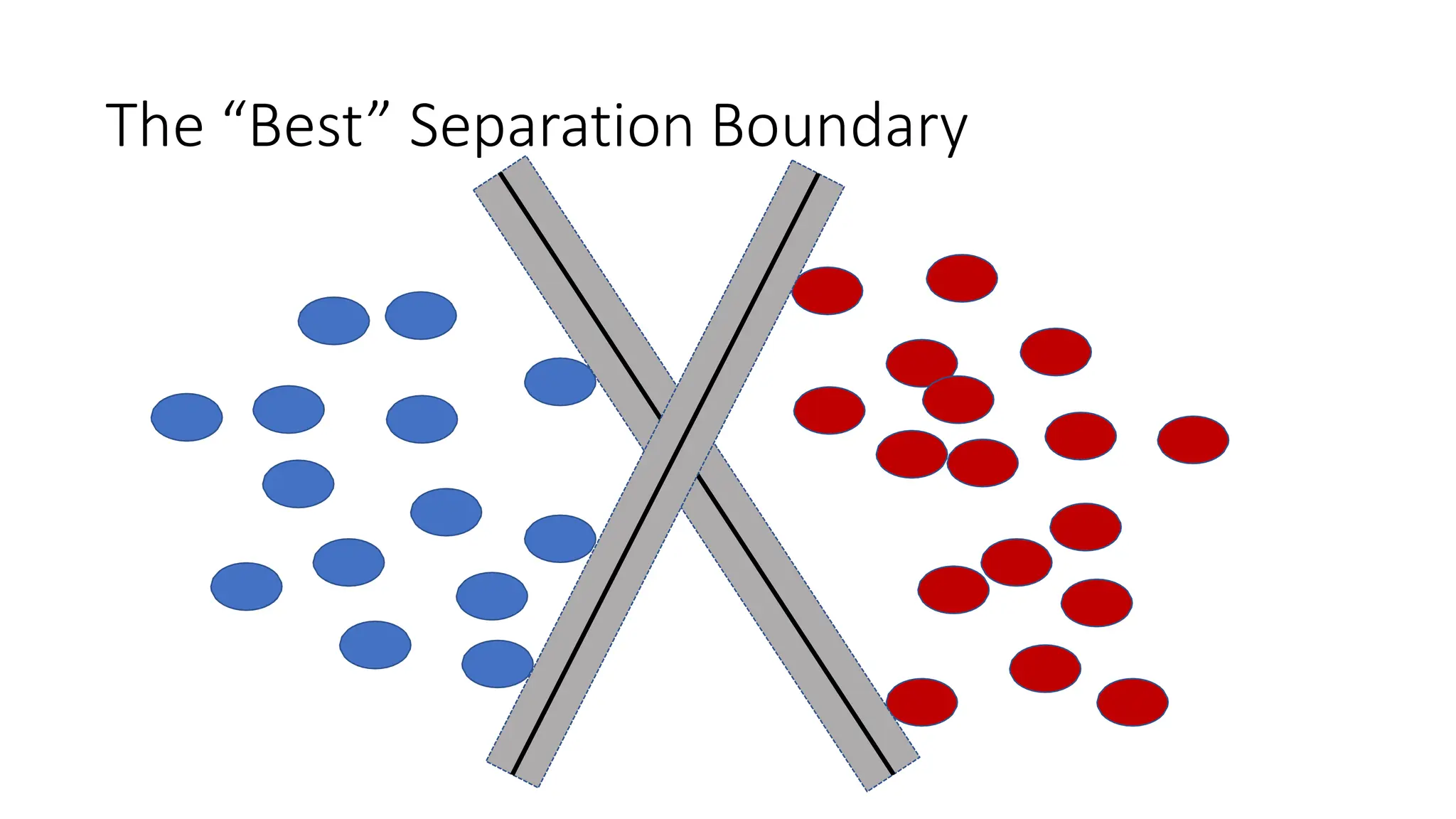
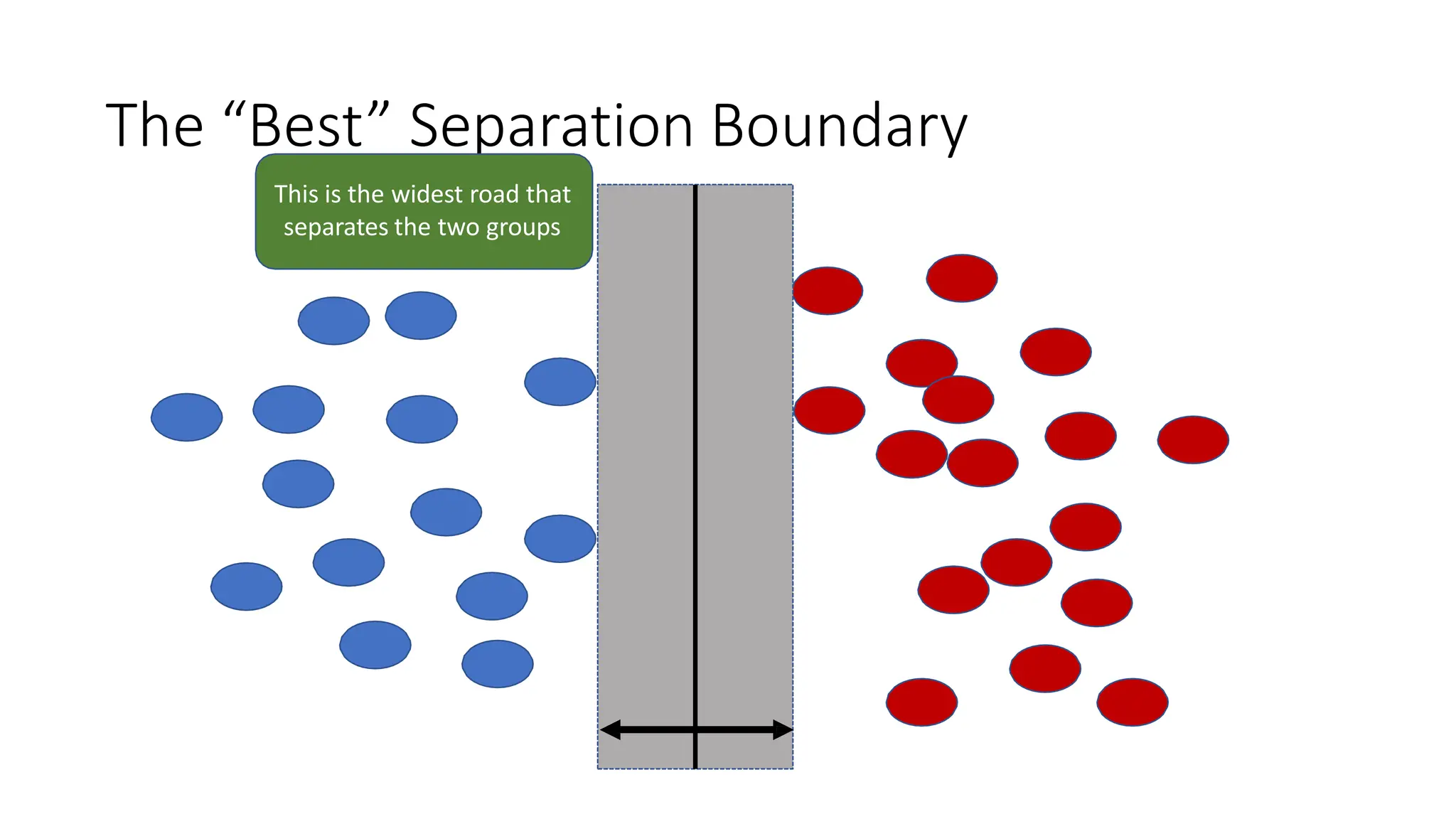
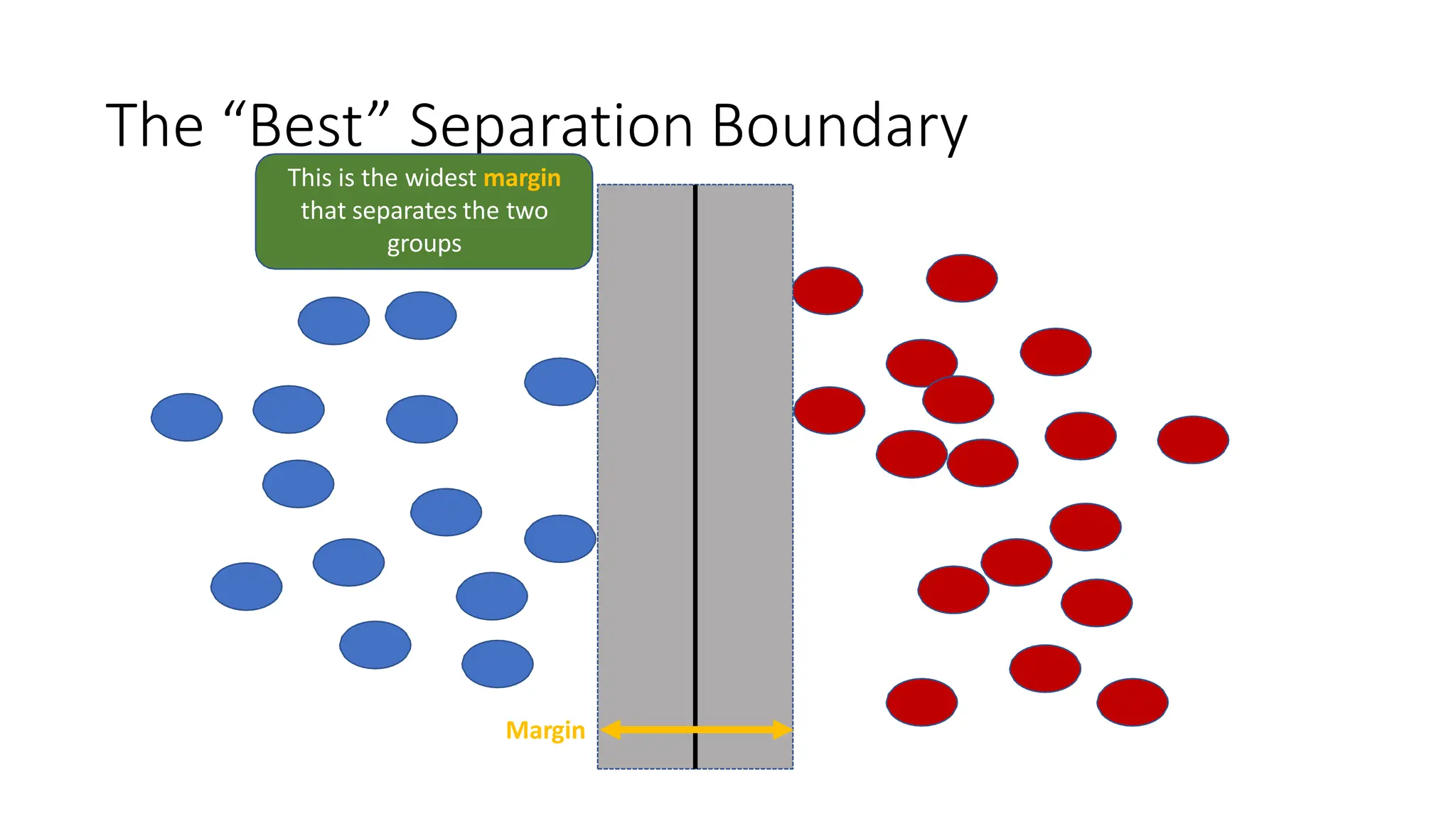
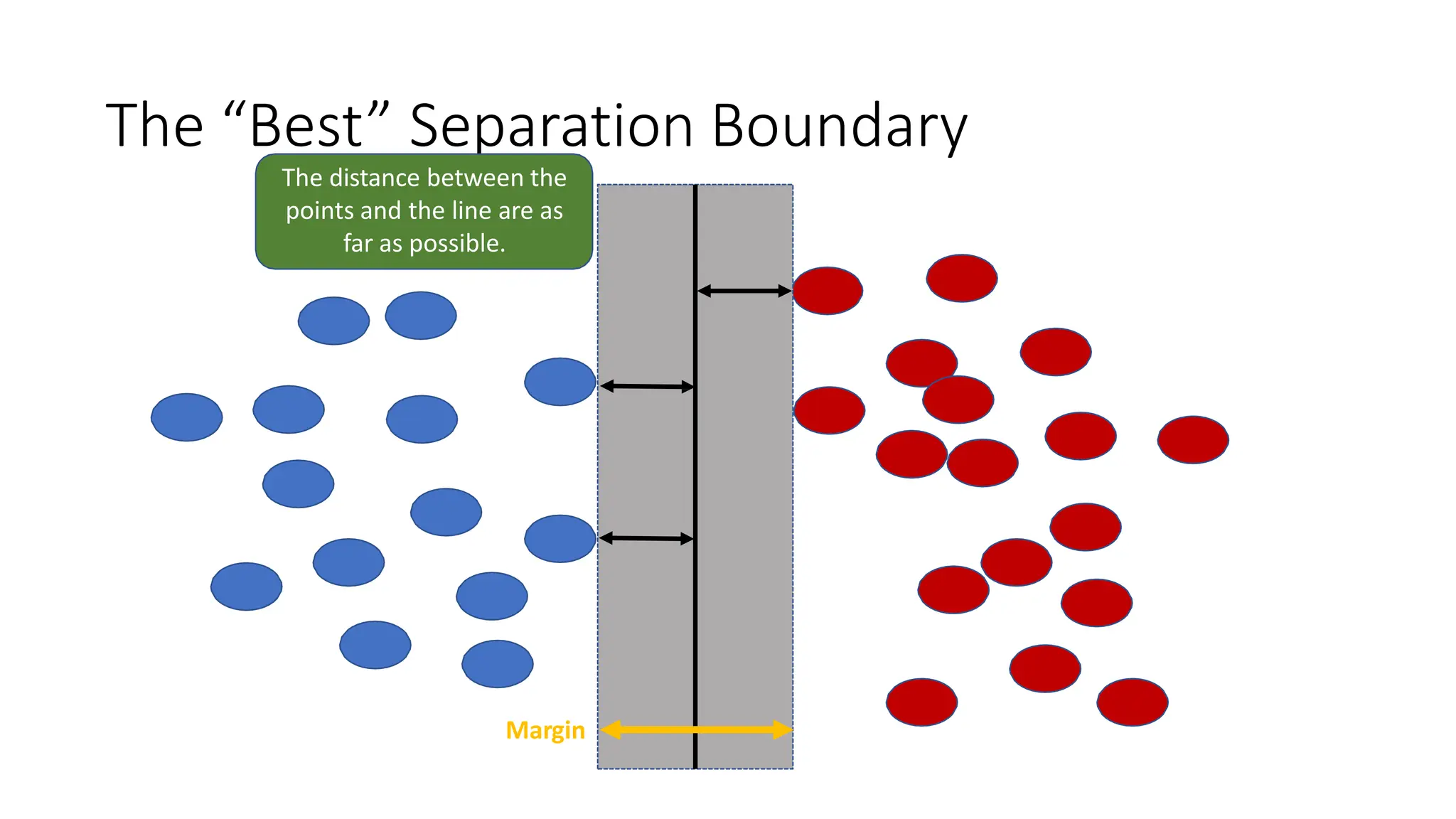
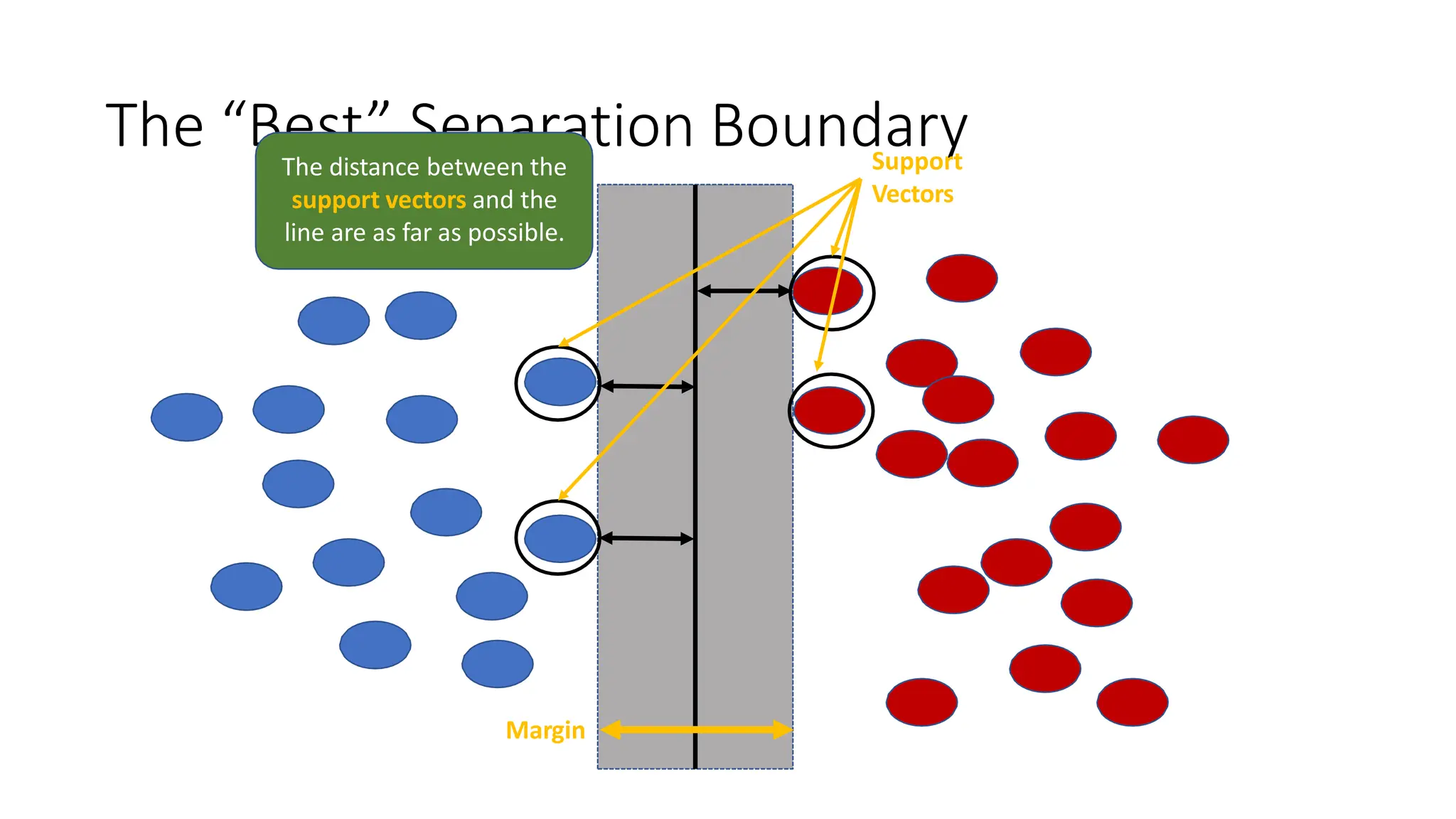
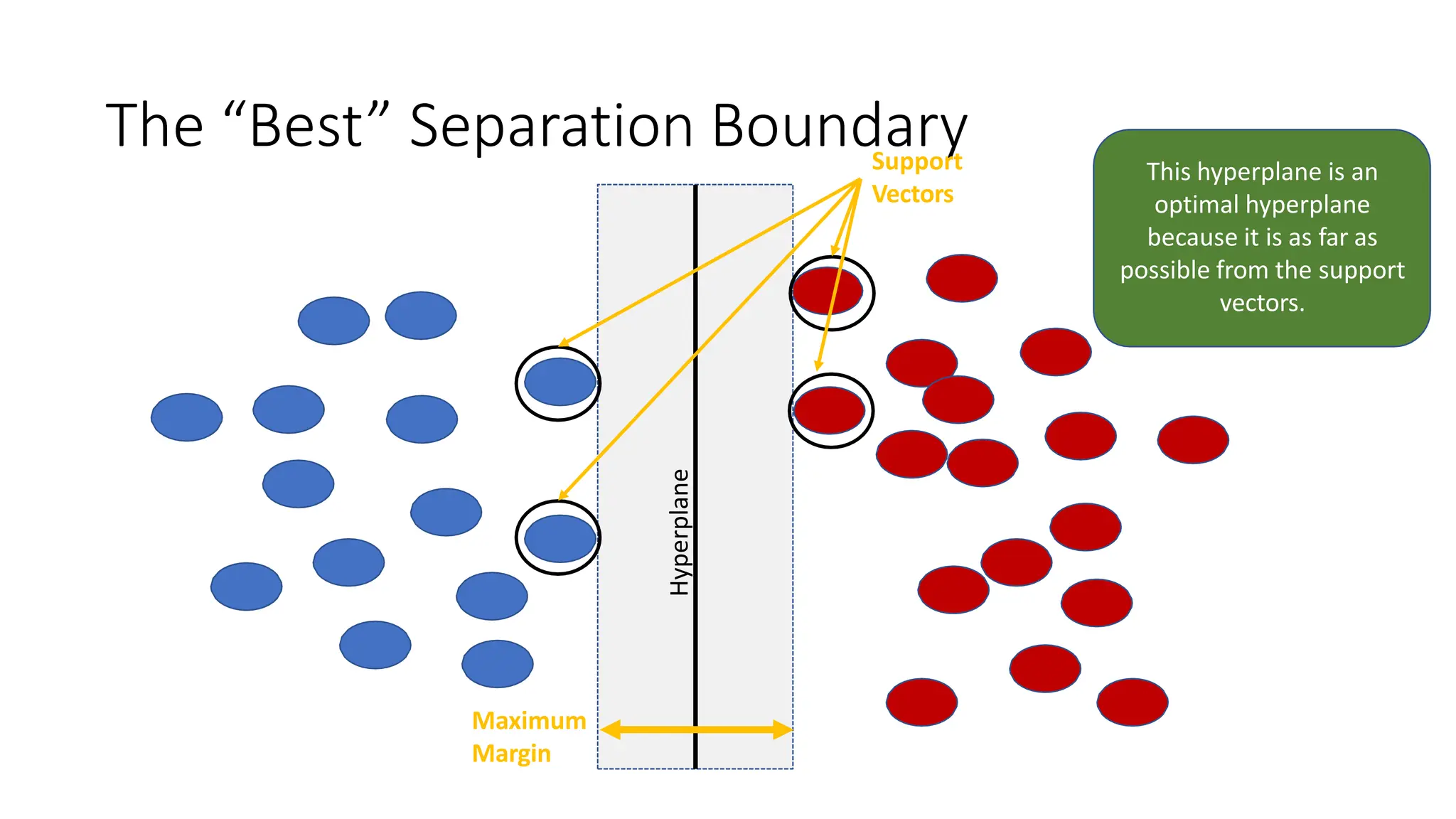
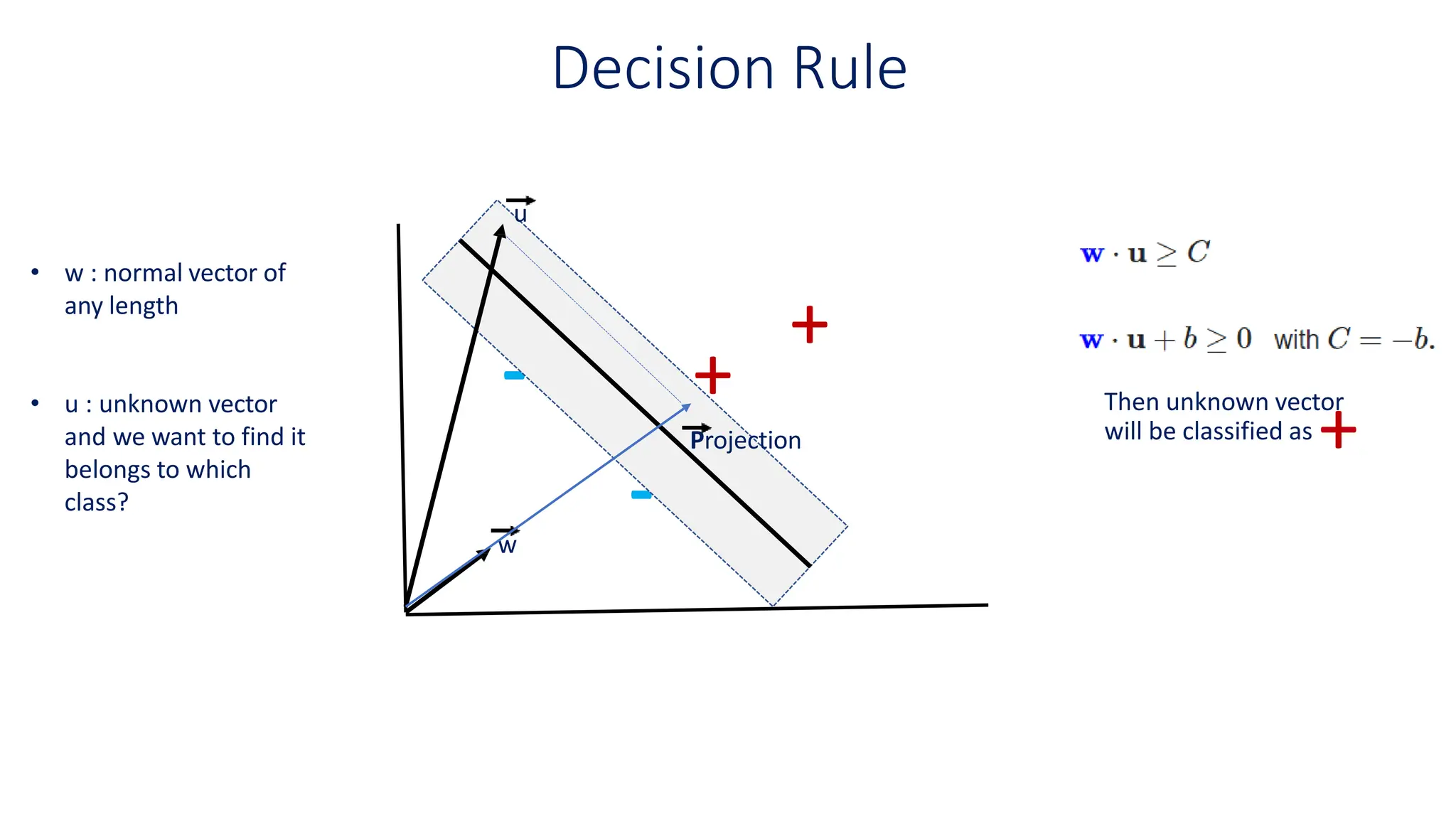
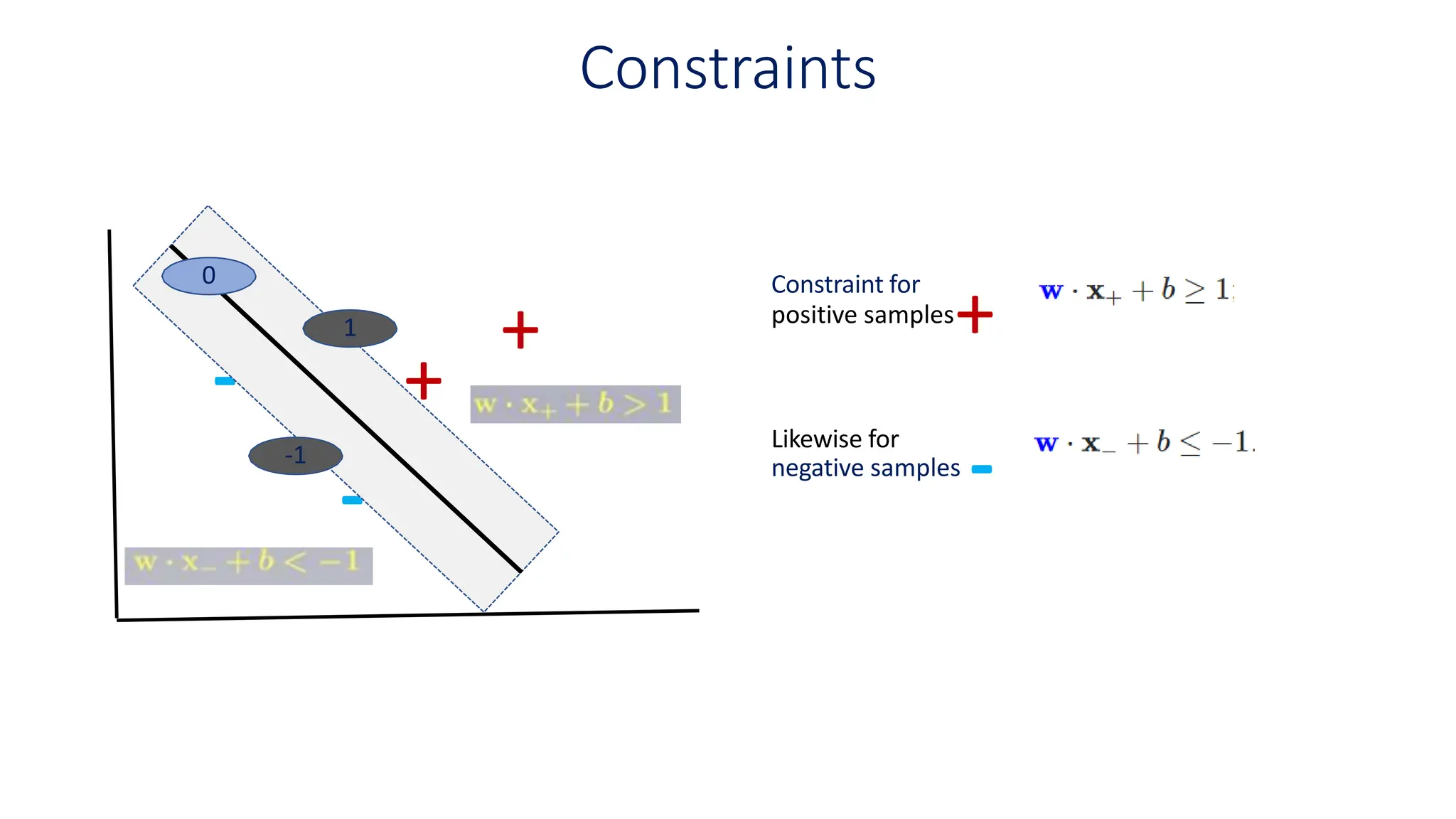
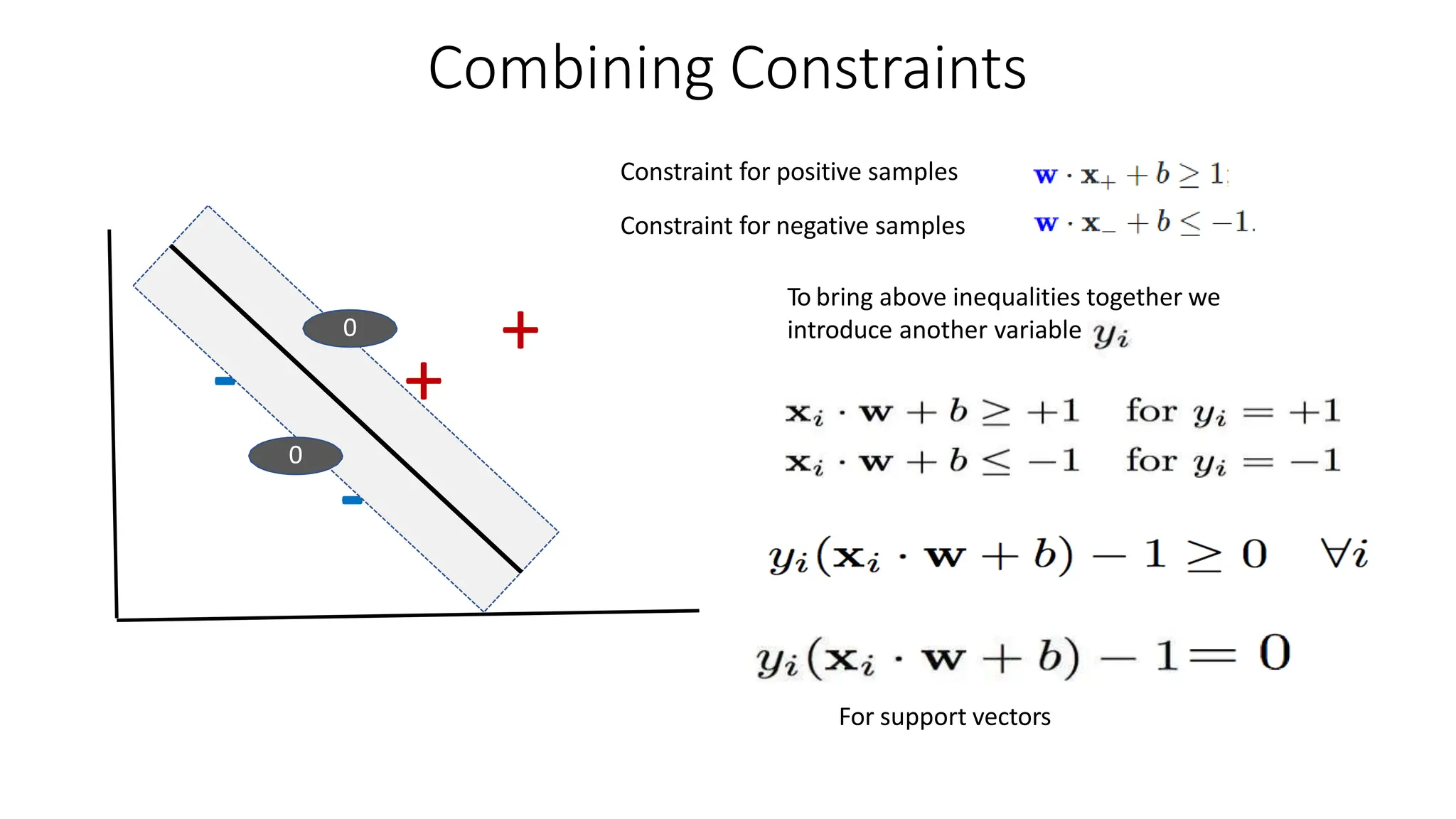
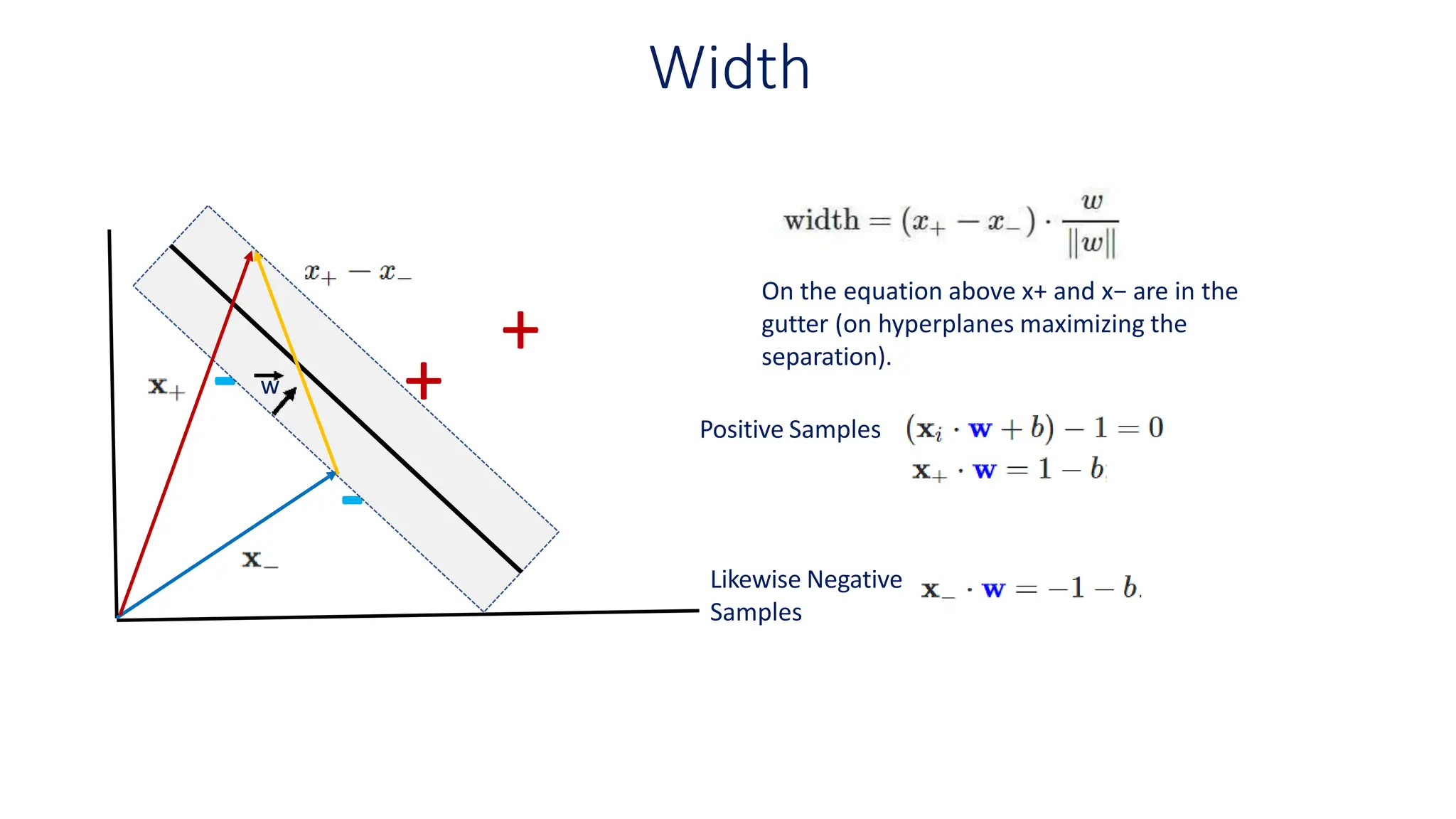
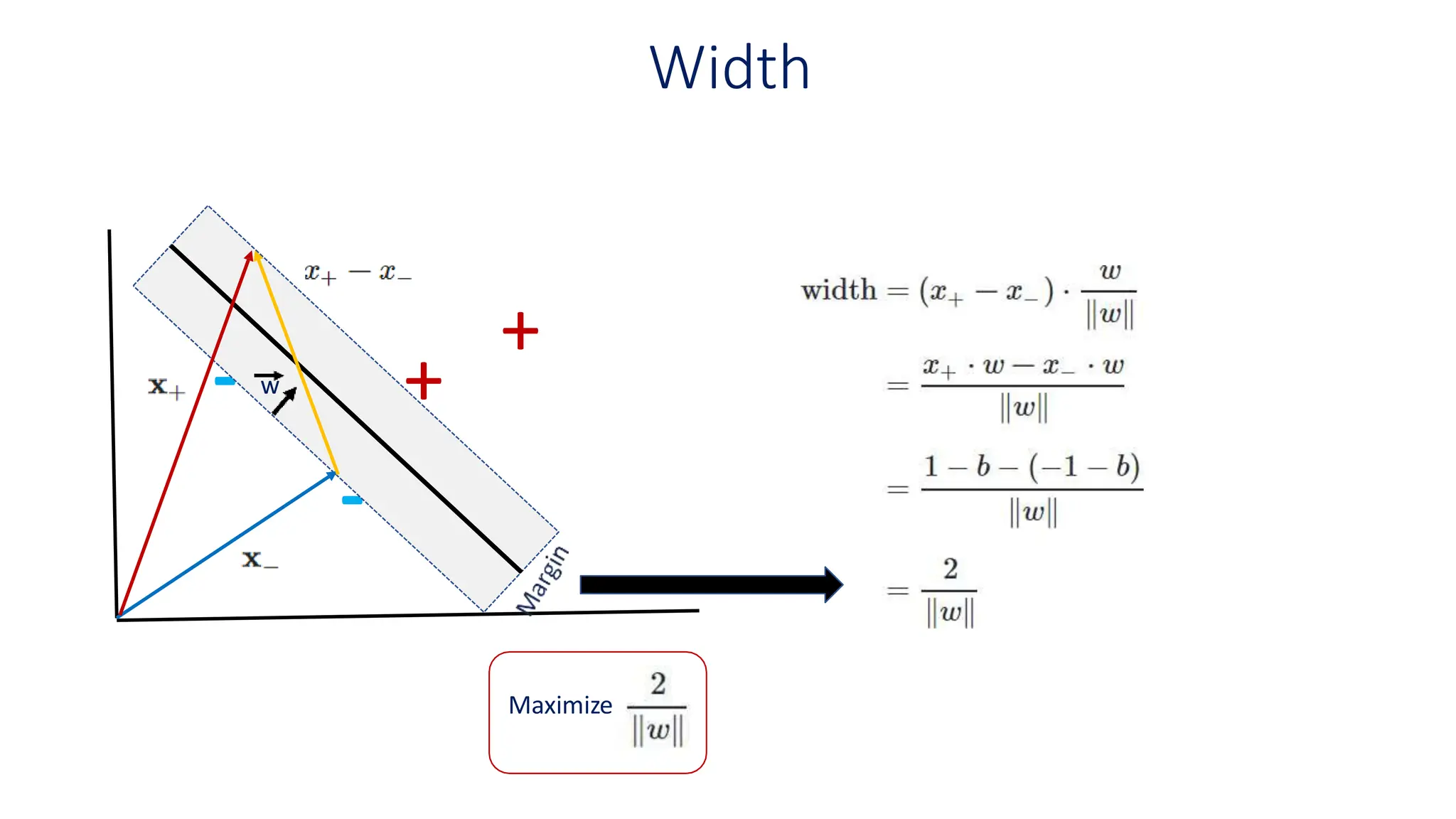
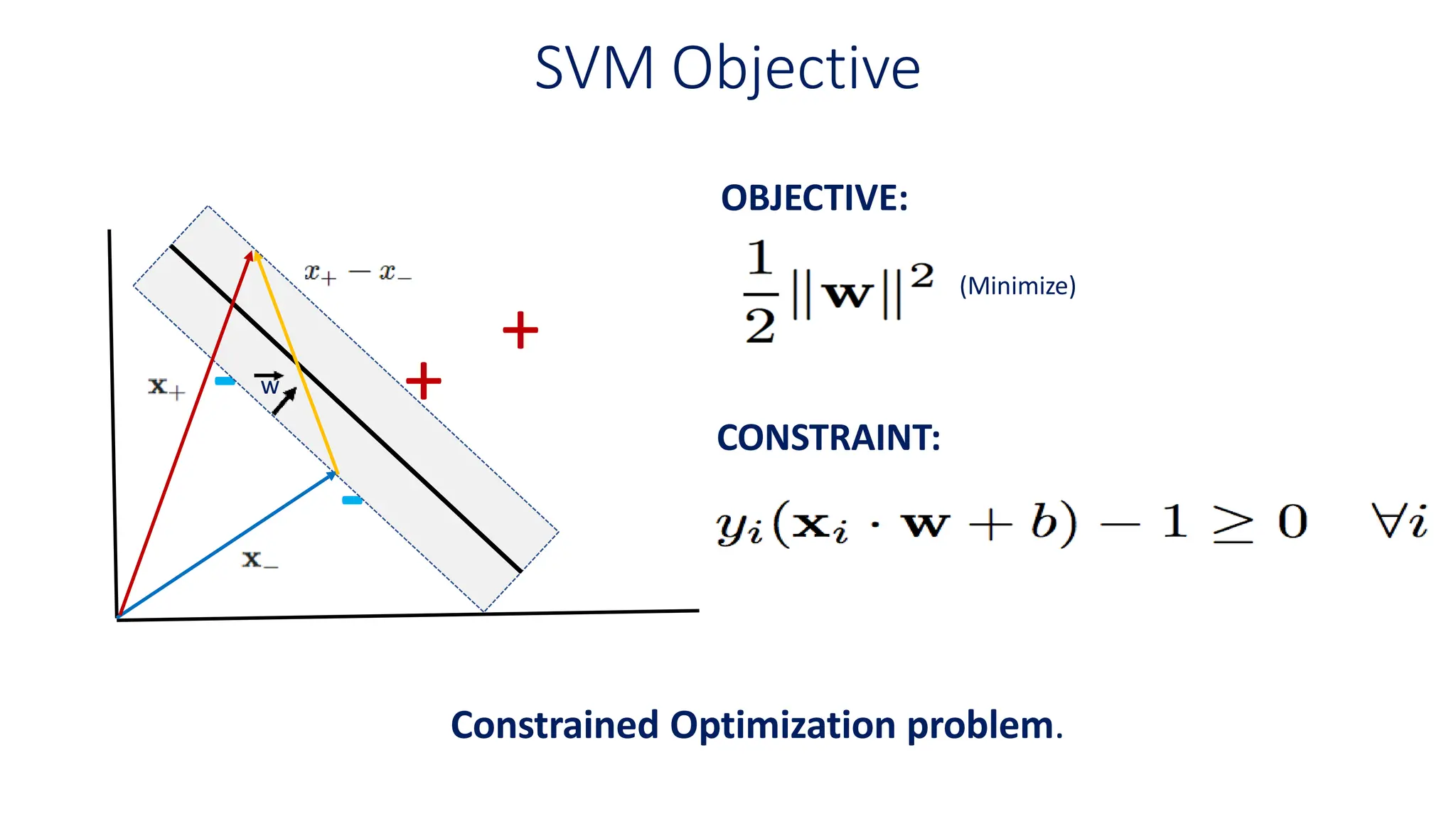
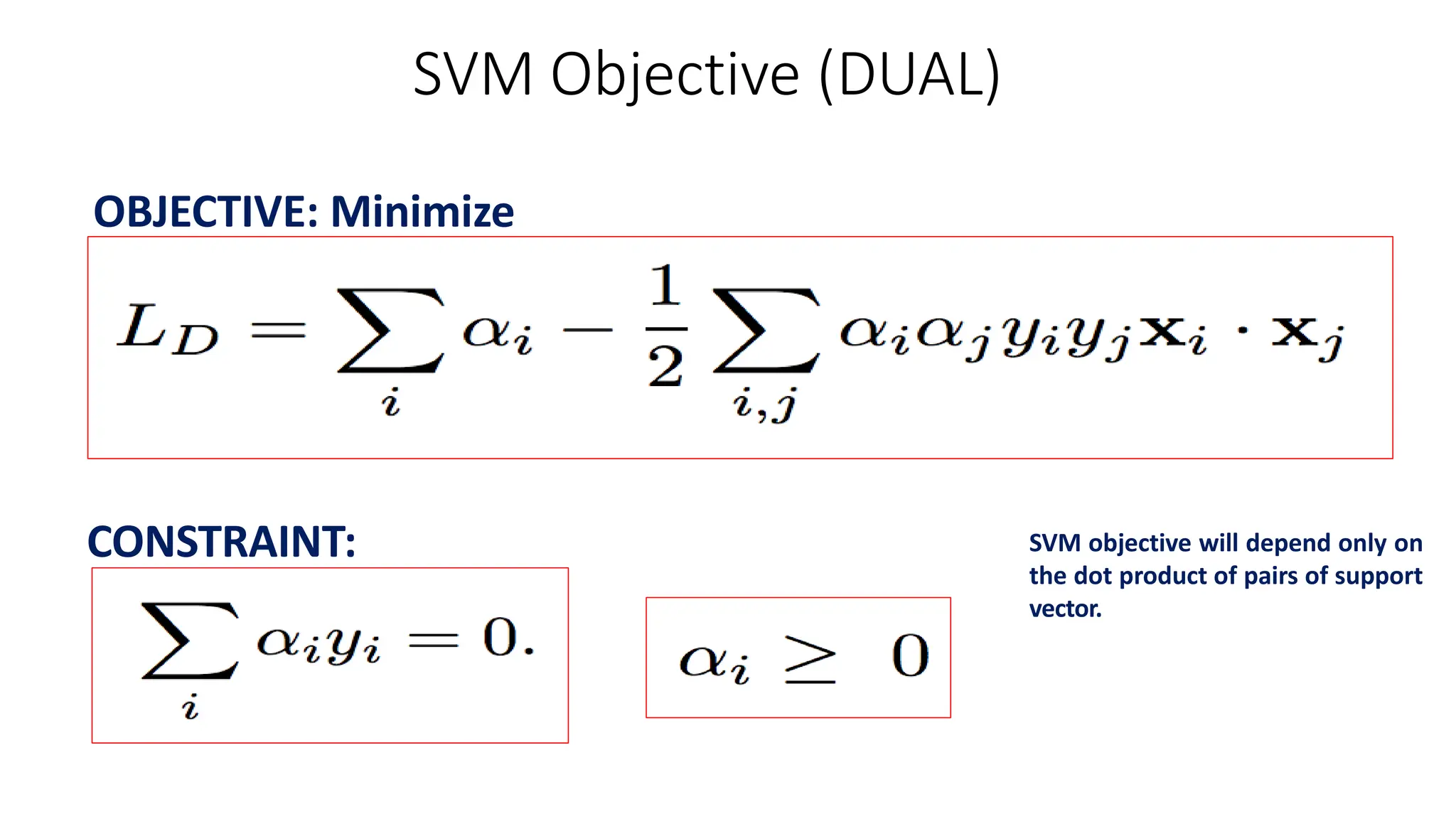
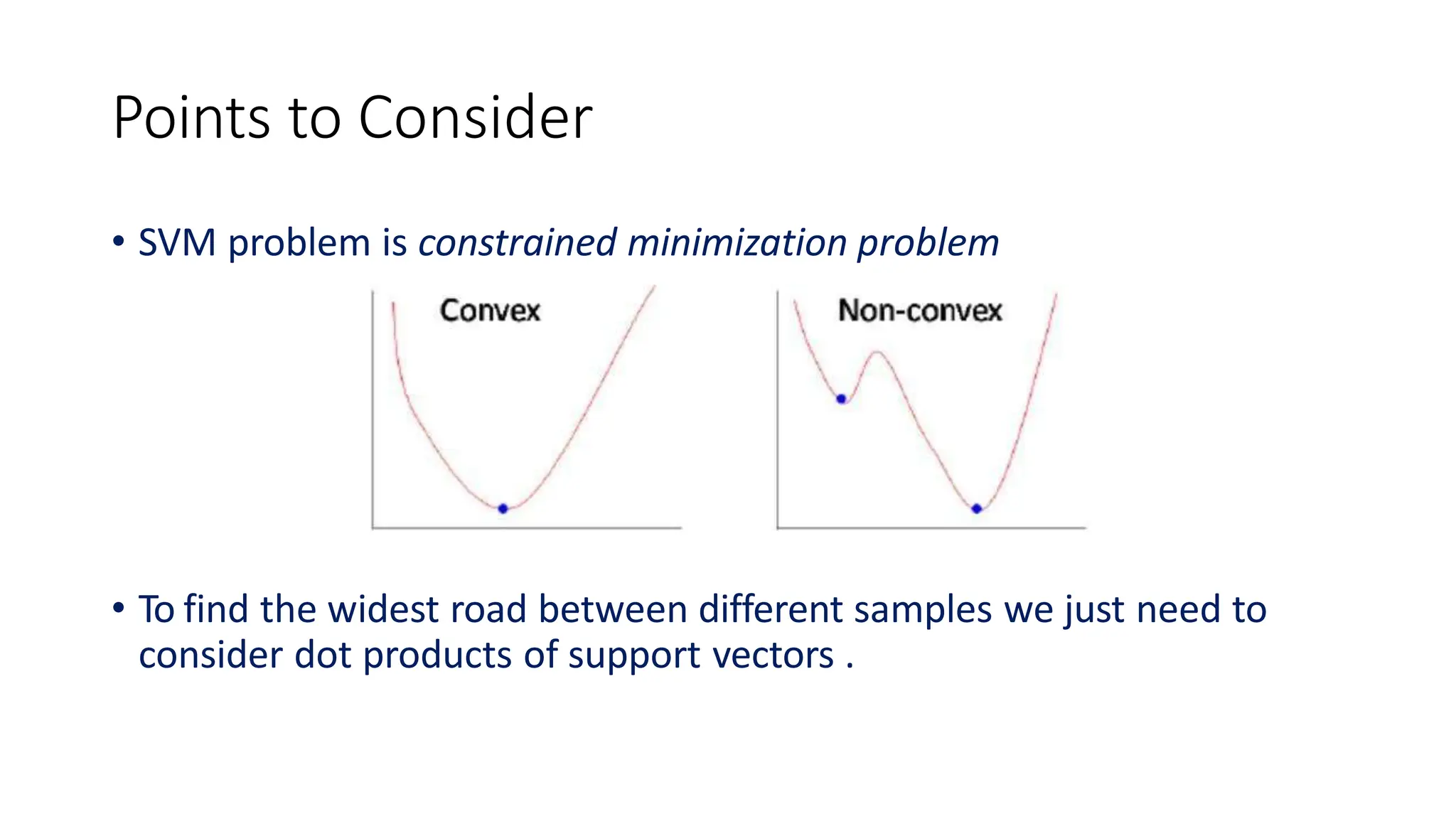
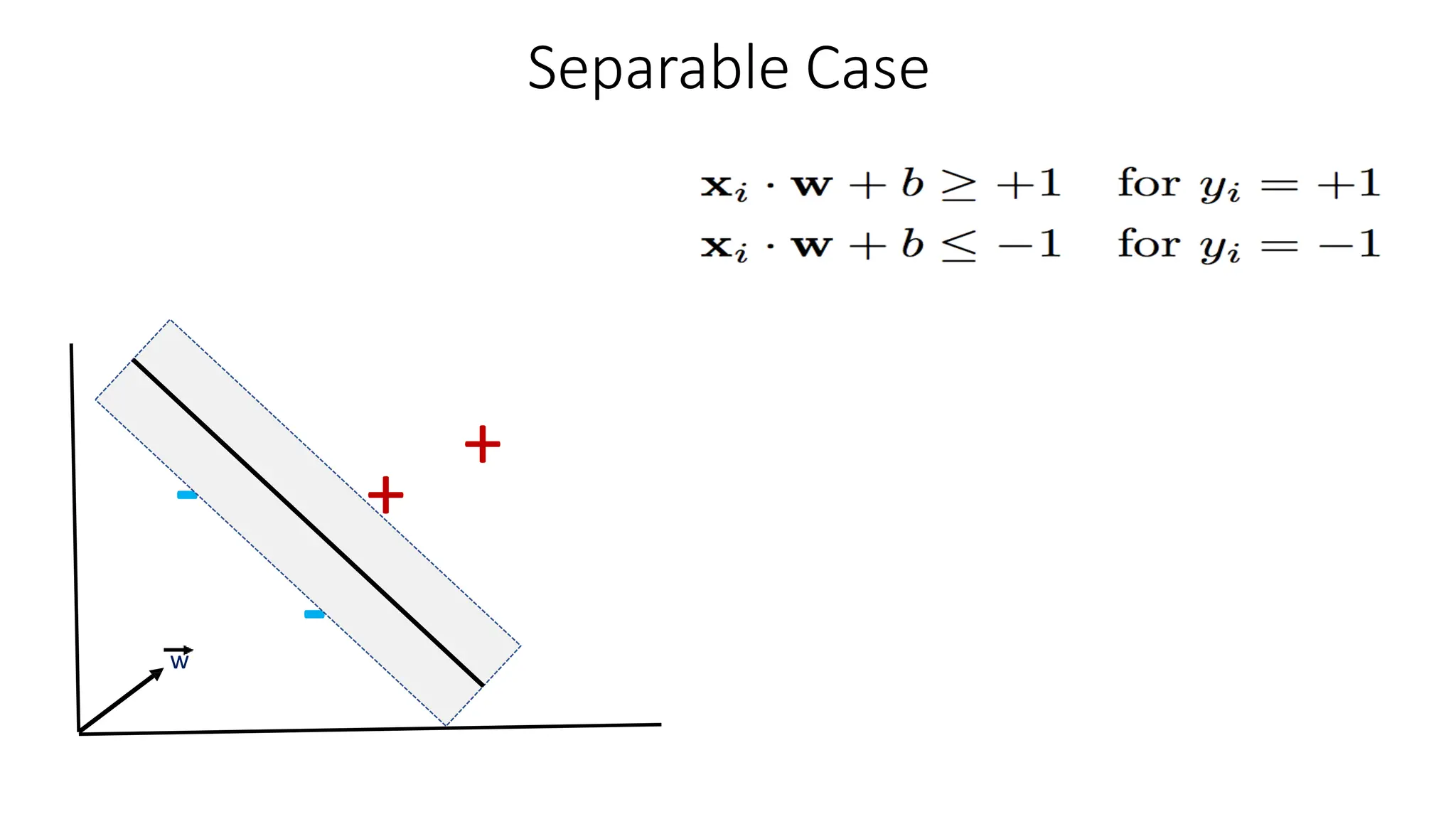
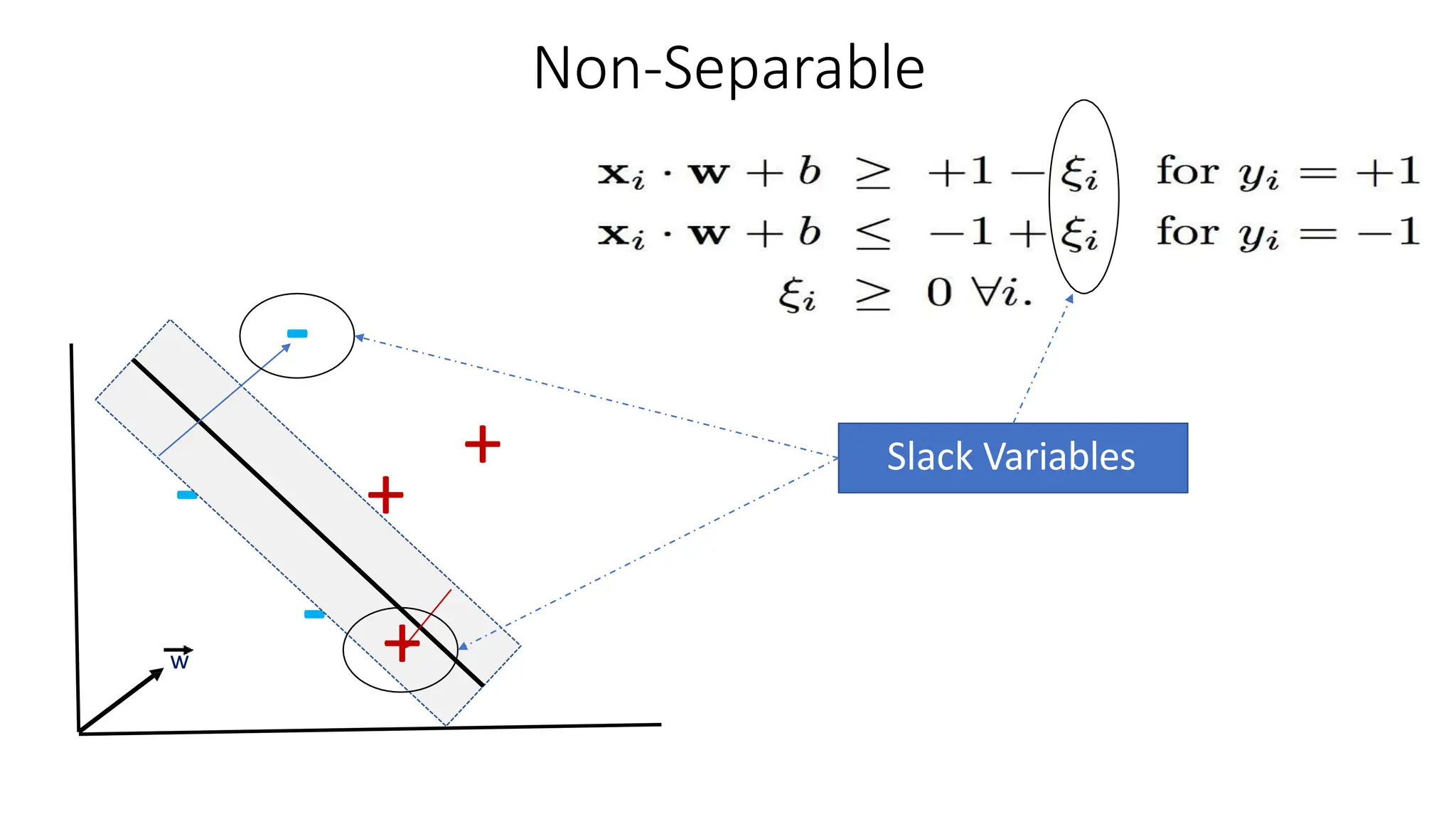
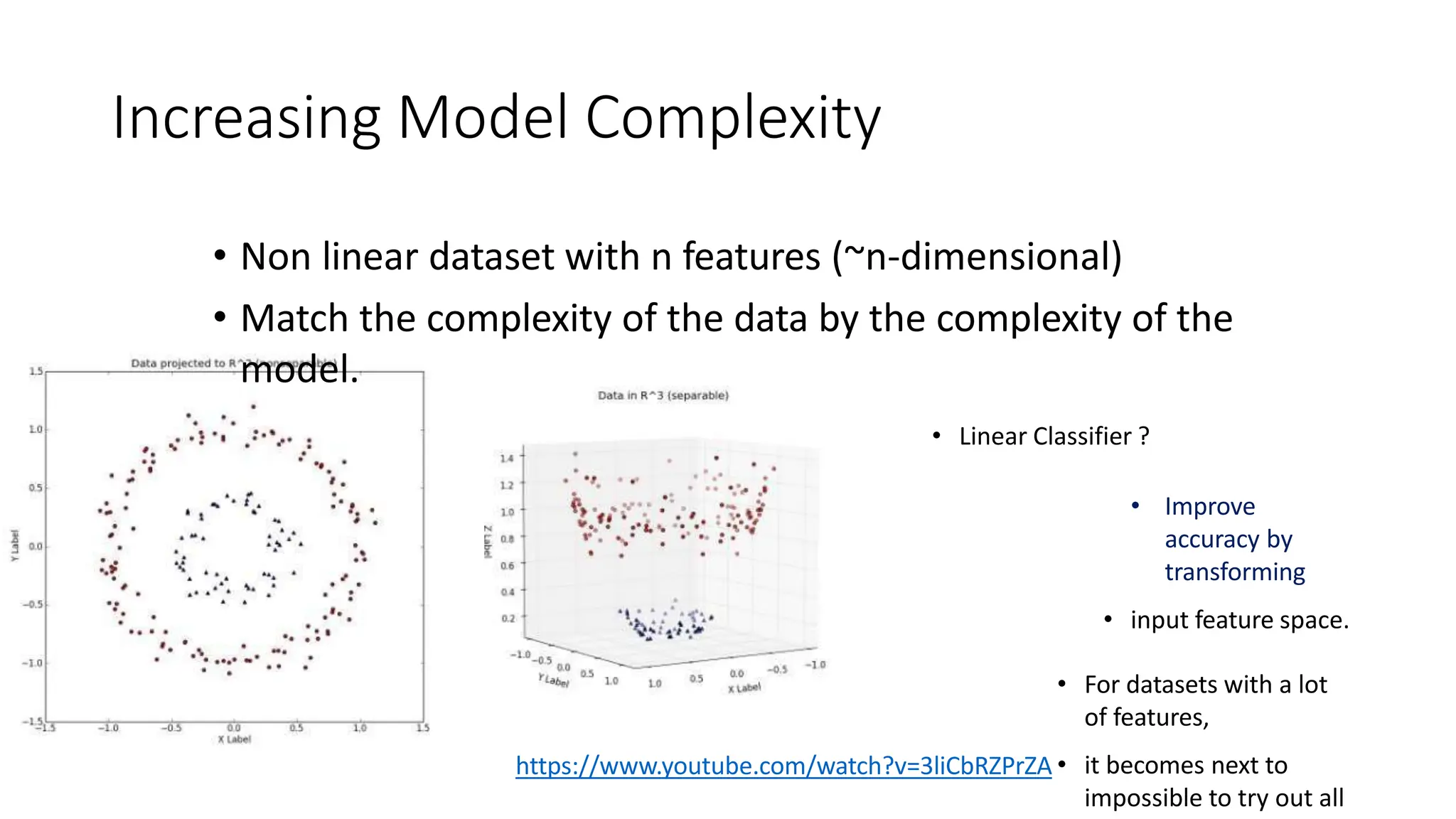
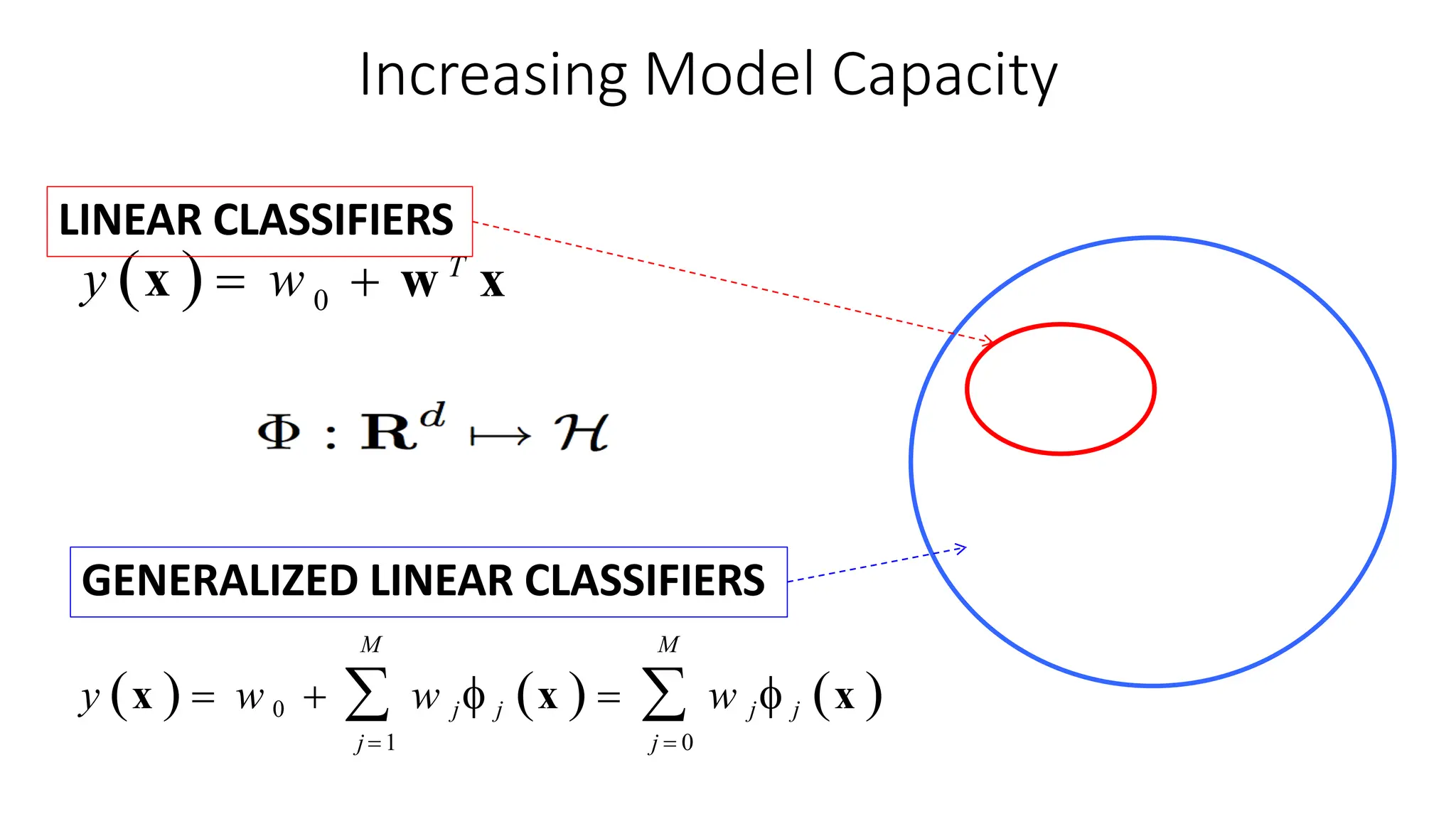
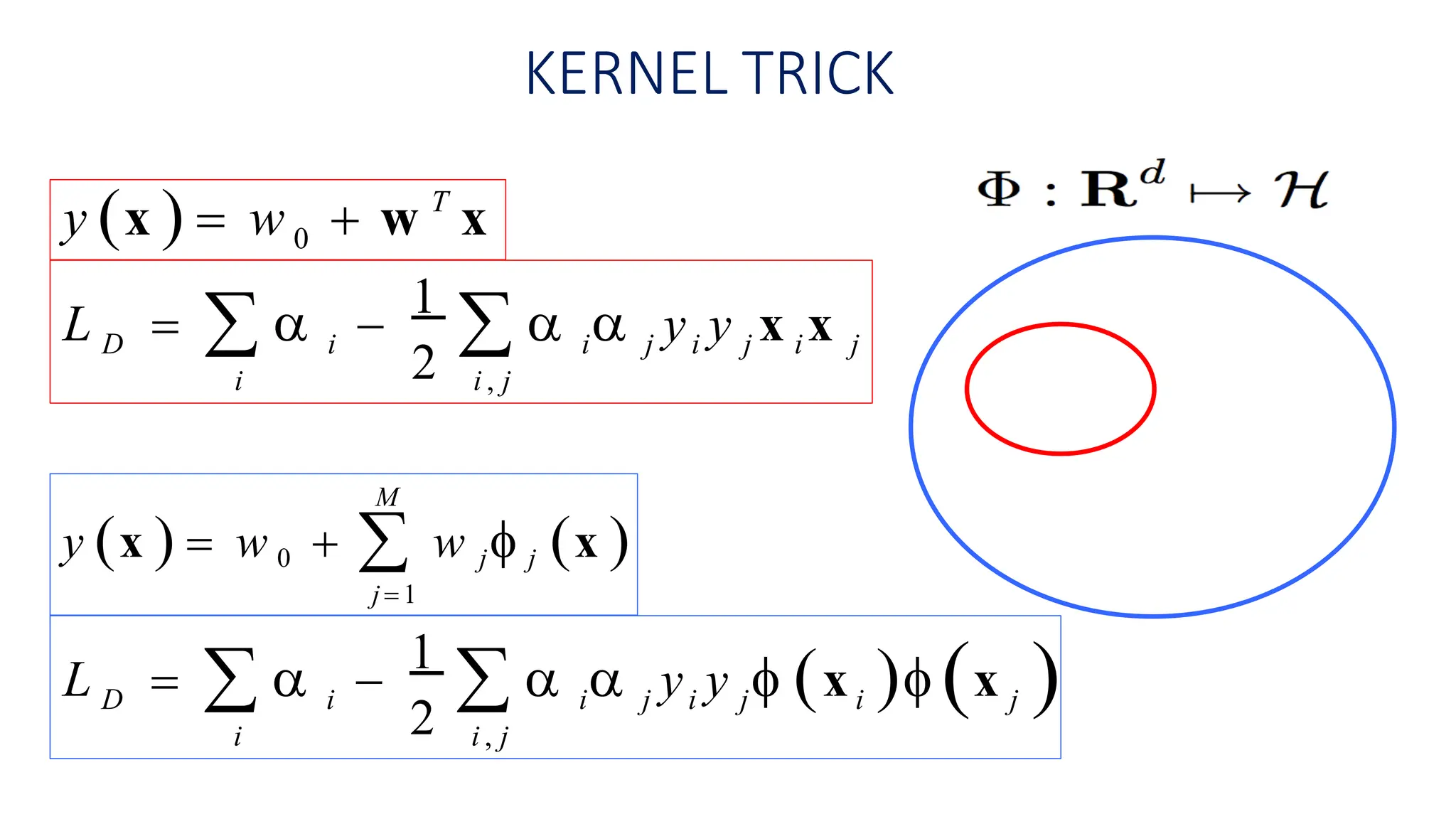
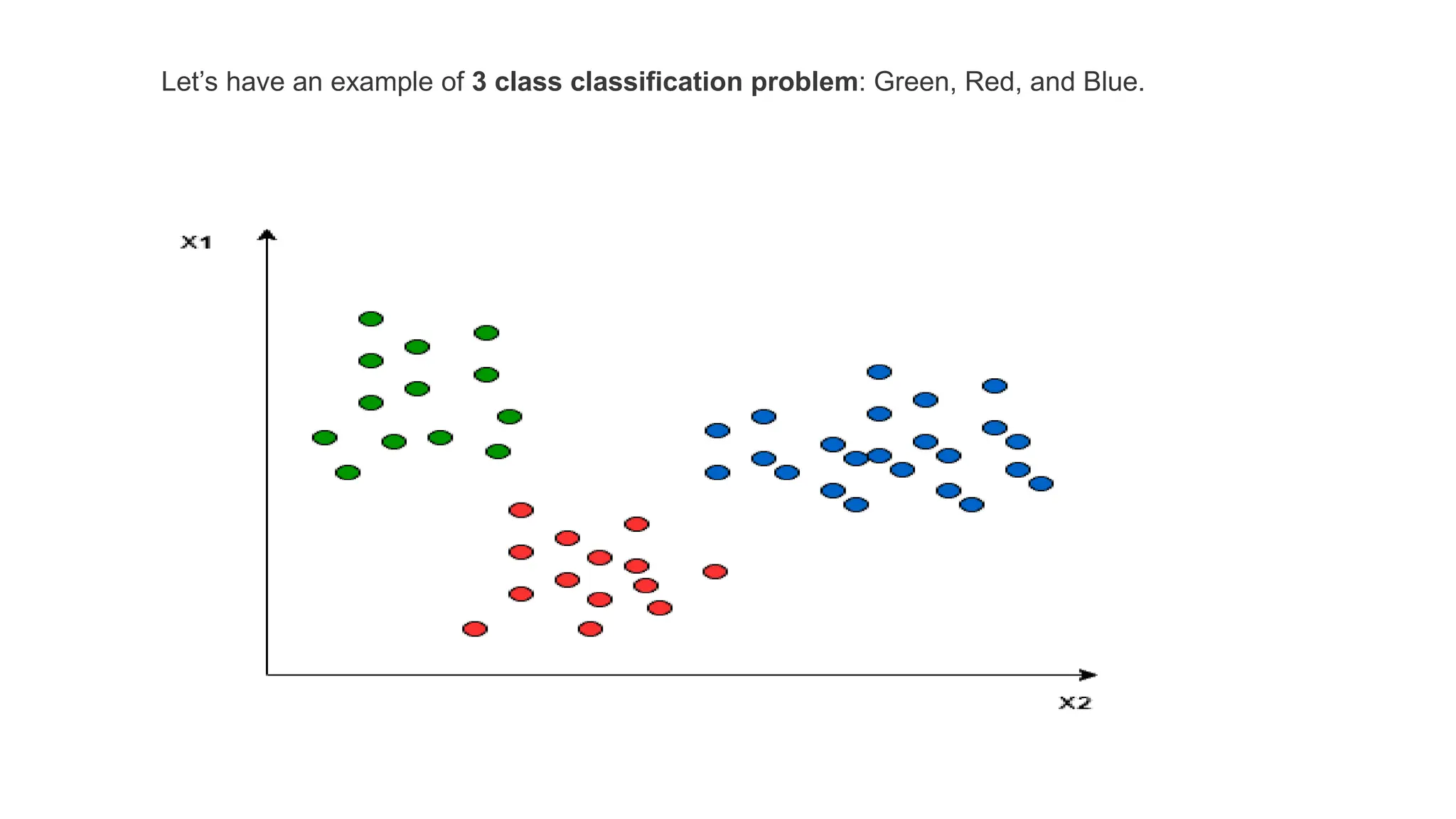
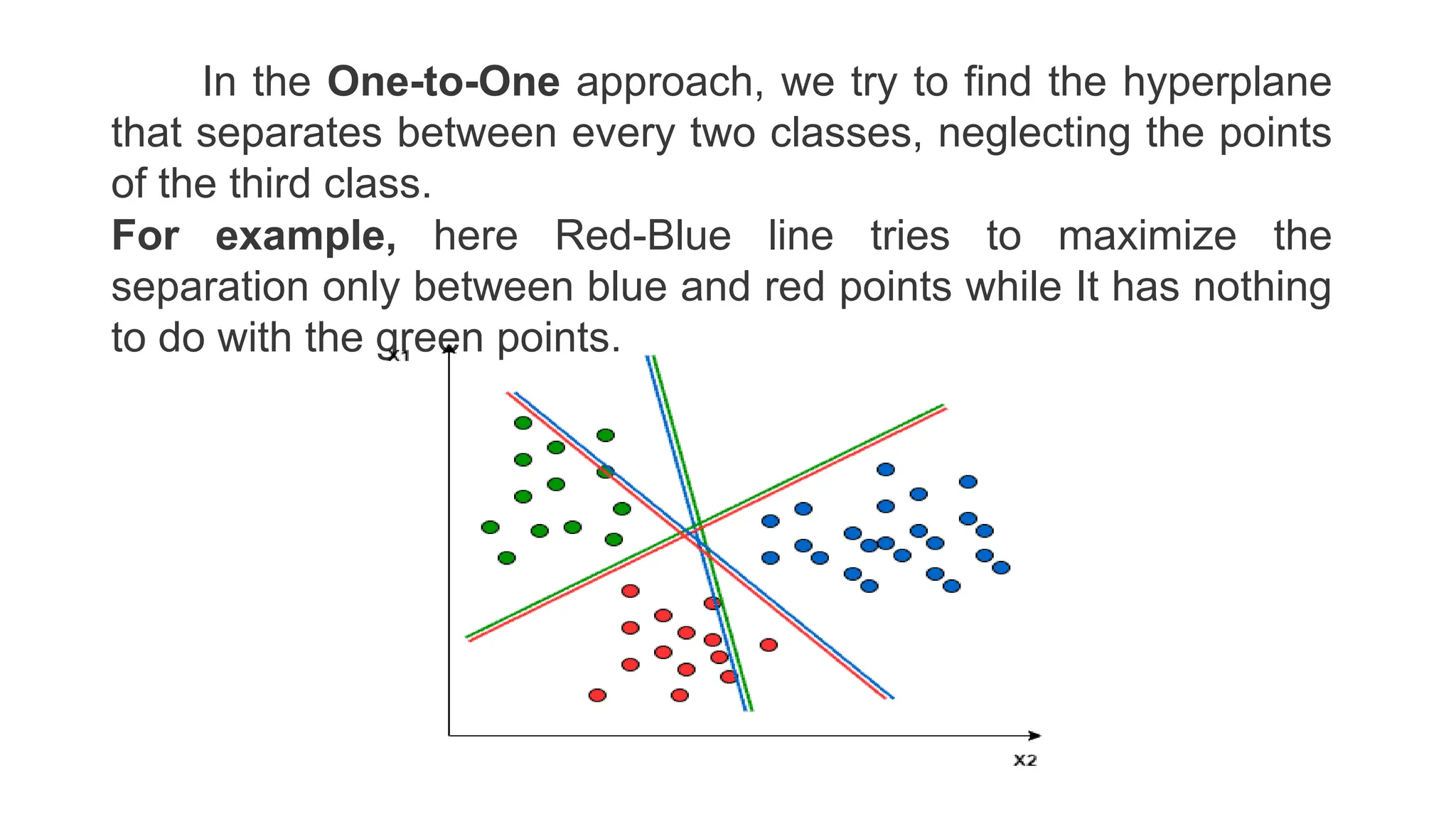
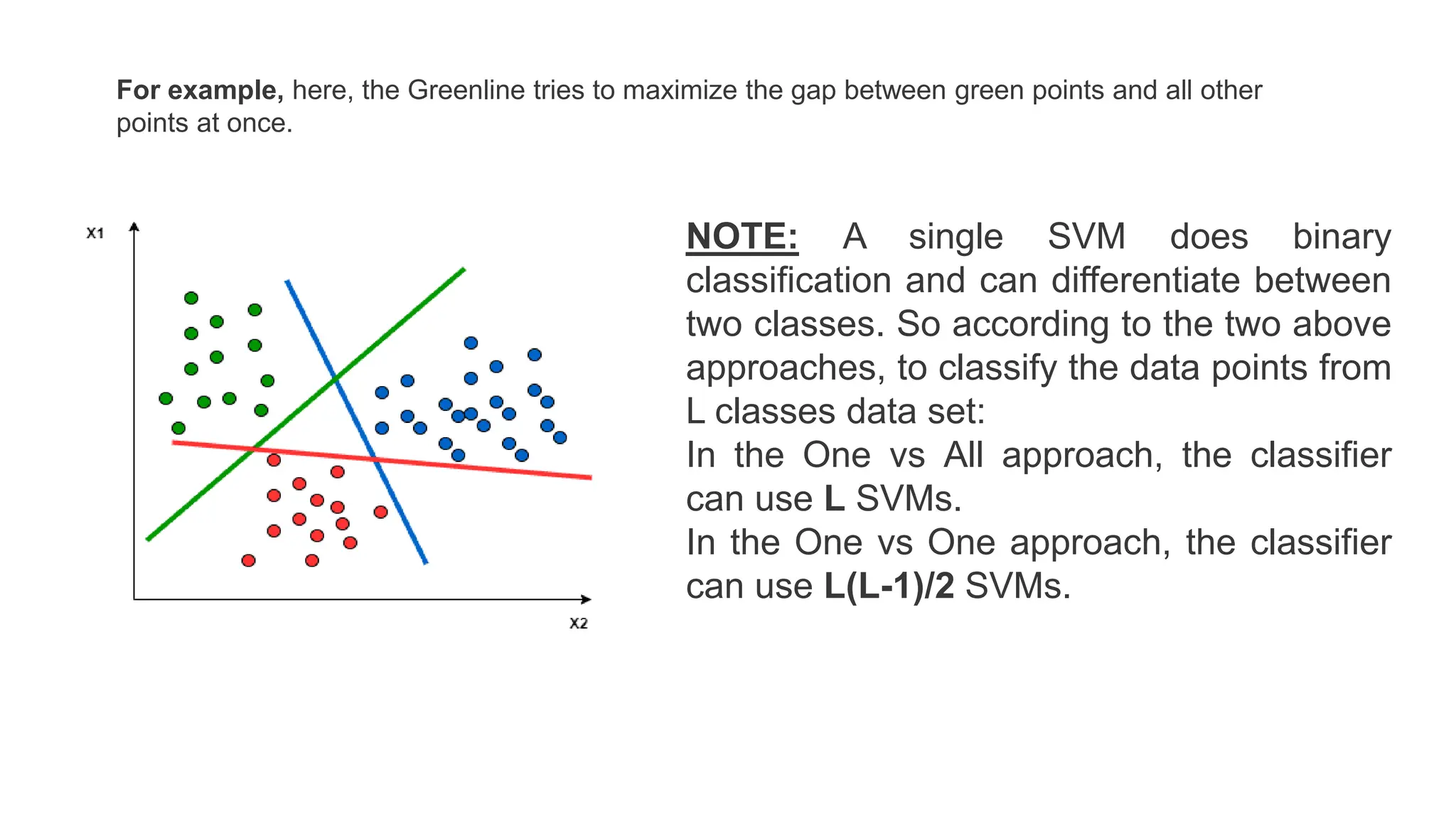
This document discusses support vector machines (SVM), a supervised machine learning algorithm used for classification and regression. It explains that SVM finds the optimal boundary, known as a hyperplane, that separates classes with the maximum margin. When data is not linearly separable, kernel functions can transform the data into a higher-dimensional space to make it separable. The document discusses SVM for both linearly separable and non-separable data, kernel functions, hyperparameters, and approaches for multiclass classification like one-vs-one and one-vs-all.









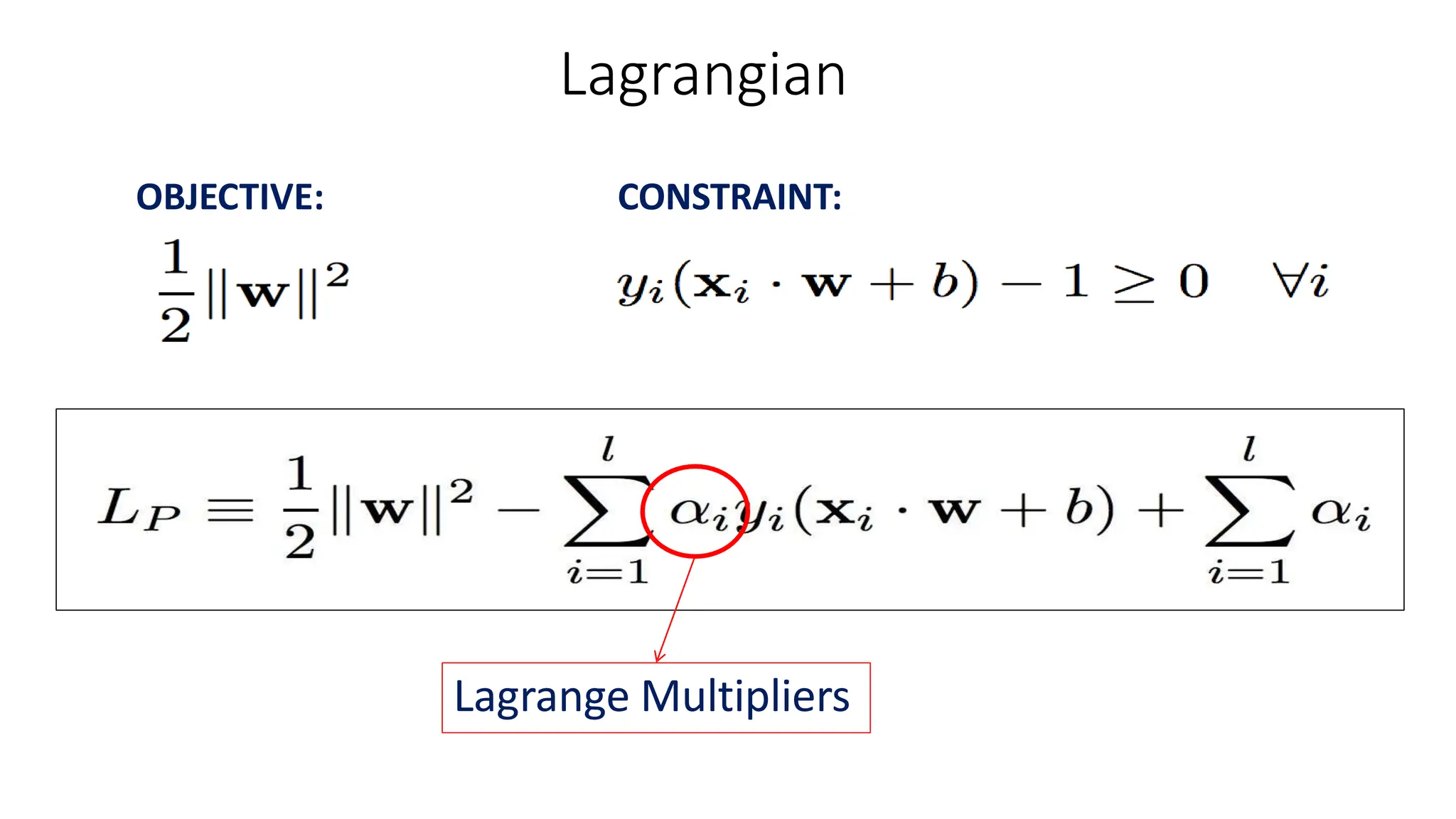



























































![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)














![R basics for MBA Students[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/rbasicsformbastudents1-240213044033-aee3b8d3-thumbnail.jpg?width=640&height=640&fit=bounds)




![Module_-_3_Product_Mgt_&_Pricing[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/module-3productmgtpricing1-240418034836-e464c428-thumbnail.jpg?width=640&height=640&fit=bounds)





























