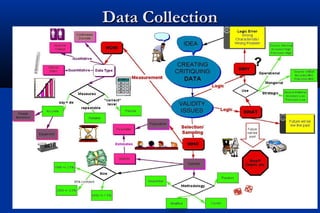
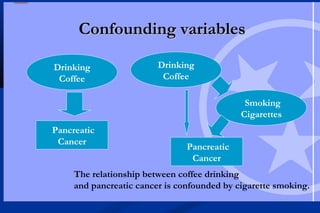
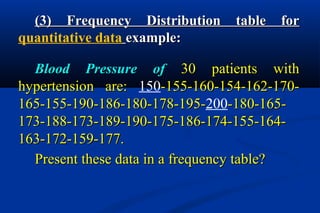
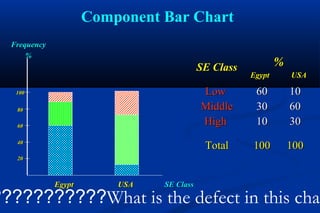
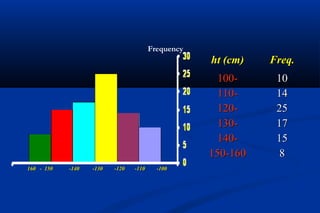
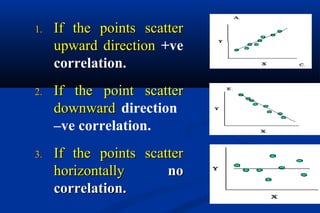
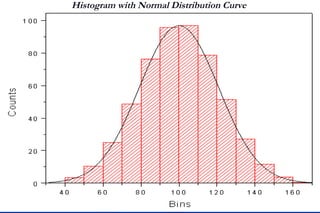
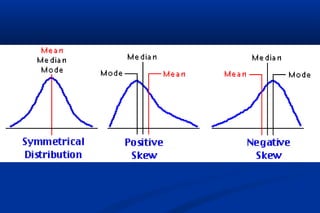
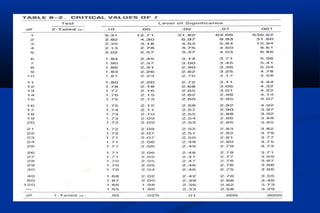
Statistics is the science of dealing with numbers and is used for collecting, summarizing, presenting, and analyzing data. It plays important roles in health care planning and evaluation, epidemiological studies, diagnosing community health problems, and comparing diseases and health status. Data can be quantitative or qualitative, discrete or continuous. Data is commonly presented using tables and graphs like bar charts, pie charts, histograms, scatter plots, and line graphs. Key measures used to summarize data include the mean, median, and mode for measures of central tendency, and the range, variance, and standard deviation for measures of dispersion.