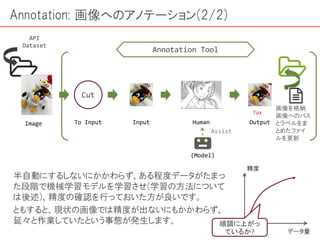
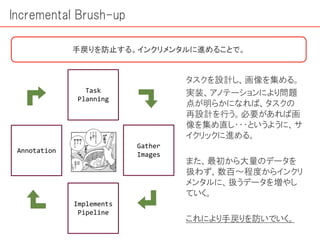
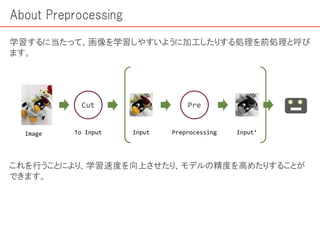
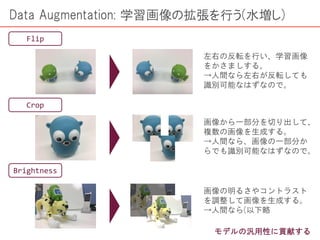
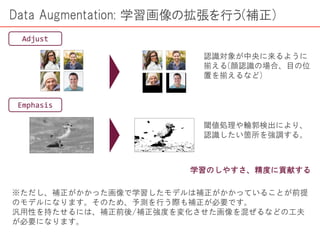
画像認識は現在、仕事・趣味と幅広い場面で欠かせないものとなってきています。その手段として機械学習を用いることももはや常識的になっていると言っても過言ではなく、そのためのチュートリアルも数多くあります。 ただ一方で、機械学習のもとになる「学習データの作り方」についてはあまり情報がありません。 本編では、この「データの取り方、処理方法(下ごしらえ)」にフォーカスした解説を進めていきます。
































![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators](https://cdn.slidesharecdn.com/ss_thumbnails/stylegan-nada-210813013304-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[オープンキャンプin南島原2020]深層学習を使ってキュウリ選別機作ってみた](https://cdn.slidesharecdn.com/ss_thumbnails/opencampminamishimabara-200523041547-thumbnail.jpg?width=640&height=640&fit=bounds)























