Download as PDF, PPTX




![メタ学習 (Meta Learning)
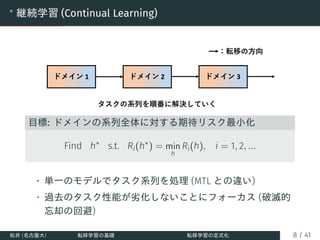
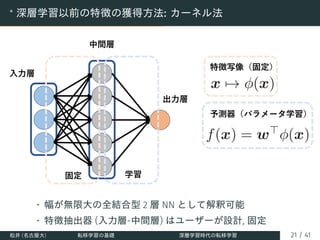
目標: メタ知識 (タスク集合/分布に関する知識) の獲得
Find ω∗
= arg min
ω
ET =(L,D)∼P(T )[L(ω; D)]
松井 (名古屋大) 転移学習の基礎 転移学習の定式化 7 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-9-320.jpg)


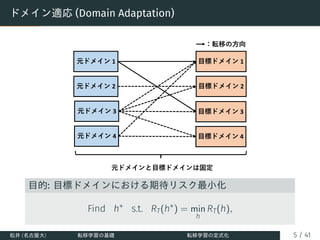
![何を転移するか
元ドメインから目標ドメインへ転移する「知識」の種類
! !"#$%&'$()*%+,-
./012 !,34562"
! 7!"#$89:;0<=>?@A
BCDE
! FG8HIJFGKLM$N&OP
! !"#!$%&'( !"#$%&'(')*+,-.,/0
! )*+,-#./01
!"#$ %&#$ '()*+#$
! !"#$%&'$()*%+Q5E
./012 !Q34562"
! 7!"#$89:;0RS8TU*%
BVW !XYZ["
! TU*%&,345]^/>?
FGKLM$N0_`
! 2345 !1#'2)*+,-.,/0
! 6789:;<=> !3'2%2)*+,-.4/0
! !"#$%&'()*+,-.
/0123456#789:;
"#$%&<=>
! ?@'(+,-4A<
! 5678*!19:;%2)*+,-.</0
! 3=8>,*!7'?@AB?)*+,-.C/0*
! 3=8>D*!5BAE2)*+,-,-/0
松井 (名古屋大) 転移学習の基礎 転移学習の基本問題 10 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-13-320.jpg)
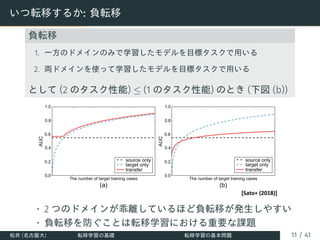
![いつ転移するか: ドメインの不一致度 (discrepancy)
ドメインの非類似度をデータ生成分布の不一致度で評価
• 不一致度が小さい → 両ドメインのデータ生成分布が似て
いる (負転移が起こりにくい)
• 様々な discrepancy が定義されている
• H∆H divergence [Ben-David+ (2010)]
• Wasserstein distance [Courty+ (2017)]
• source-guided discrepancy [Kuroki+ (2019)]
松井 (名古屋大) 転移学習の基礎 転移学習の基本問題 12 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-15-320.jpg)
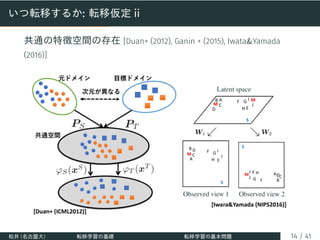
![いつ転移するか: 転移仮定 i
ドメインの分布の違い方に対する仮定 [Quionero-Candela+ (2009)]
• データセットシフト : PS(X, Y) ̸= PT(X, Y)
• 共変量シフト : PS(Y | X) = PT(Y | X), PS(X) ̸= PT(X)
• クラス事前確率シフト (ターゲットシフト) :
PS(X | Y) = PT(X | Y), PS(Y) ̸= PT(Y)
• サンプル選択バイアス :
PS(X, Y) = P(X, Y | v = 1), PT(X, Y) = P(X, Y)
v は (X, Y) が学習データに含まれる (v = 1) か否 (v = 0) か
• クラスバランスシフト [Redko+ (2019)] :
PS = (1 − πS)P0 + πSP1, PT = (1 − πT)P0 + πTP1 (πS ̸= πT)
P0, P1 はクラス 0, 1 に対応する共変量分布
松井 (名古屋大) 転移学習の基礎 転移学習の基本問題 13 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-16-320.jpg)
![いつ転移するか: 転移仮定 iii
共通の生成過程 [Teshima+ (ICML2020)]
• 因果モデルで捉えられるデータ生成過程の知識を転移
松井 (名古屋大) 転移学習の基礎 転移学習の基本問題 15 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-18-320.jpg)


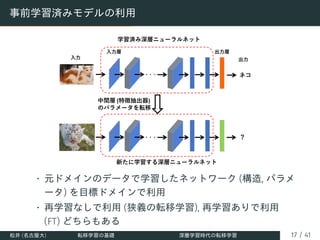
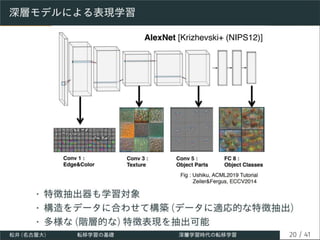
![巨大事前学習済みモデルとファインチューニング
• トランスフォーマー (上図) を用いた巨大な事前学習済み
モデルを FT して利用
• GPT-2 [Radford+ (2019)], GPT-3 [Brown+ (2020)],
DALL-E [Ramesh+ (2021)] (Open-AI)
• スクラッチ学習に膨大なコスト (計算リソースや時間) が
かかるモデルでも FT のみ (相対的に低コスト) で使える
松井 (名古屋大) 転移学習の基礎 深層学習時代の転移学習 18 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-22-320.jpg)
![知識蒸留 [Gou+ (2020)] : 事前学習済みモデルの圧縮
• 学習済みモデルのパラメータではなく, モデルが学習した
暗黙知 (dark knowledge) を転移する
• (猫を犬と間違える確率) ≪ (猫を車と間違える確率)
• 手書き数字の “2” は “7” よりも “3” に似ていやすい
• ネットワークを直接転移しないのでファインチューニング
に比べて転移先のモデルは小さくて済む (モデル圧縮)
松井 (名古屋大) 転移学習の基礎 深層学習時代の転移学習 19 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-23-320.jpg)
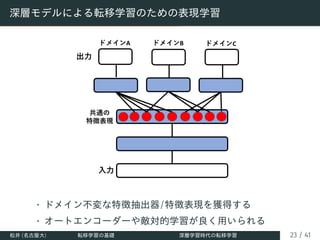
![∗
カーネル法による特徴表現に基づく転移学習
元ドメイン ⽬標ドメイン
次元が異なる
共通空間
[Duan+ (ICML2012)]
``いらいらするほど簡単なDA’’
[Daume III, ACL2007]
ドメイン共通の特徴
ドメイン固有の特徴
min
PS,PT
max
α
1⊤
ns+nt
α −
1
2
(α ◦ y)⊤
KPS,PT
(α ◦ y)
s.t. y⊤
α = 0, 0ns+nt
≤ α ≤ C1ns+nt
∥PS∥2
F ≤ λp, ∥PT∥2
F ≤ λq
松井 (名古屋大) 転移学習の基礎 深層学習時代の転移学習 22 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-26-320.jpg)


![例: 深層オートエンコーダーによるドメイン不変表現学習
Transfer Learning with Deep Autoencoders [Zhuang+ (2015)]
• オートエンコーダーによる教師付き表現学習
min Err(x, x̂)
| {z }
reconstruction error
+α (KL(PS||PT) + KL(PT||PS))
| {z }
discrepancy
+β ℓ(yS; θ, ξS)
| {z }
softmax loss
+γReg
• 元ドメインと目標ドメインで符号化と復号化の重みを共有
松井 (名古屋大) 転移学習の基礎 深層学習時代の転移学習 26 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-30-320.jpg)
![例: 敵対的学習によるドメイン不変表現学習
Domain Adversarial Training [Ganin+ (2015)]
• 特徴抽出器がドメイン不変な特徴を抽出
• ドメイン識別器の学習は gradient に負定数をかけ逆伝播
する勾配反転層を導入することで実現
松井 (名古屋大) 転移学習の基礎 深層学習時代の転移学習 27 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-31-320.jpg)

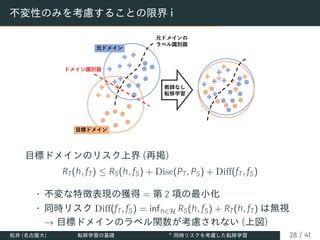
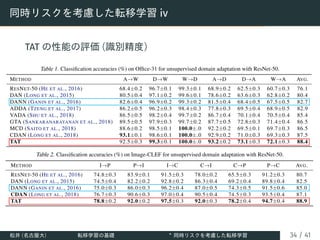
![不変性のみを考慮することの限界 ii
• 実験的な同時リスクの検証 [Liu+ (2019)]
• DANN のようなドメイン不変な表現学習のみを行う手法で
は同時リスク RS(h) + RT(h) が大きくなるような仮説が学
習されてしまう
松井 (名古屋大) 転移学習の基礎 ∗
同時リスクを考慮した転移学習 29 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-34-320.jpg)
![不変性と同時リスクの関係
同時リスクの下界 [Zhao+ (2019)]
RS(h ◦ g) + RT(h ◦ g)
≥
1
2
dJS(PT
(Y), PS
(Y)) − dJS(PT
(Z), PS
(Z))
2
• g : 特徴抽出器
• h : ラベル識別器
• dJS : JS ダイバージェンスの平方根
• Z : g によって抽出された特徴量
• ドメイン不変な表現学習に基づく転移学習が成功するため
の必要条件
• 右辺第 1 項 (ラベル分布の不一致度) が大きいとき, 右辺第
2 項の最小化 (不変表現学習) は RT(h ◦ g) を悪化させる
松井 (名古屋大) 転移学習の基礎 ∗
同時リスクを考慮した転移学習 30 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-35-320.jpg)
![同時リスクを考慮した転移学習 i
Transferable Adversarial Training (TAT) [Liu+ (2019)]
• 元ドメインと目標ドメインのギャップを埋めるような疑似
データ (転移可能事例) を生成
• 転移可能事例を含めてラベル識別器を訓練
→ ドメイン不変な表現学習を経由せずに目標ドメインで
汎化するモデルを学習可能
松井 (名古屋大) 転移学習の基礎 ∗
同時リスクを考慮した転移学習 31 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-36-320.jpg)




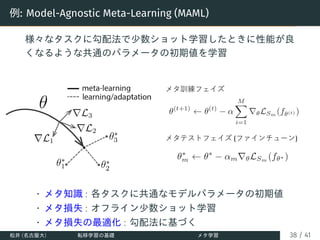
![メタ学習の定式化 [Hospedales+ (2020)]
メタ損失 (⽬的関数)
第mドメインの損失
メタ知識 ω の下での
第mドメインの最適
パラメータ
: 第mドメインの訓練データ, 検証データ
メタ学習の2レベル最適化問題としての定式化
⽬的関数:メタ知識の最適化
制約条件:ドメイン毎のパラメータ学習
松井 (名古屋大) 転移学習の基礎 メタ学習 36 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-42-320.jpg)
![メタ学習の分類
• 何をメタ知識と考えるか
• パラメータの初期値 [Finn+ (2017)]
• 最適化器 [Chen+ (2017)]
• ハイパーパラメータ, ...
• メタ損失をどう設定するか
• 多数ショット (通常の) 学習 [Franceschi+ (2017)] vs 少数シ
ョット学習 [Finn+ (2017)]
• マルチタスク学習 [Li+ (2019)] vs シングルタスク学
習 [Veeriah+ (2019)]
• オンライン学習 [Veeriah+ (2019)] vs オフライン学習 [Finn+
(2017)], ...
• メタ損失をどう最適化するか
• 勾配ベースの最適化 [Finn+ (2017)]
• 強化学習による最適化 [Duan+ (2016)]
• 進化計算による最適化 [Soltoggio+ (2018)], ...
松井 (名古屋大) 転移学習の基礎 メタ学習 37 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-43-320.jpg)


![References
[1] Hal Daumé III. Frustratingly easy domain adaptation. ACL, 2007.
[2] A. Krizhevsky et al. Imagenet classification with deep convolutional neural networks. NeurIPS, 2012.
[3] A. Radford et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
[4] A. Ramesh et al. Zero-shot text-to-image generation. arXiv preprint arXiv:2102.12092, 2021.
[5] A. Soltoggio et al. Born to learn: the inspiration, progress, and future of evolved plastic artificial neural
networks. Neural Networks, 108:48–67, 2018.
[6] B. K. Sriperumbudur et al. On the empirical estimation of integral probability metrics. Electronic Journal of
Statistics, 6:1550–1599, 2012.
[7] C. Finn et al. Model-agnostic meta-learning for fast adaptation of deep networks. ICML, 2017.
[8] F. Zhuang et al. Supervised representation learning: Transfer learning with deep autoencoders. IJCAI, 2015.
[9] H. Liu et al. Transferable adversarial training: A general approach to adapting deep classifiers. ICML, 2019.
[10] H. Zhao et al. On learning invariant representations for domain adaptation, 2019.
[11] I. Redko et al. Optimal transport for multi-source domain adaptation under target shift. AISTATS, 2019.
[12] I. Sato et al. Managing computer-assisted detection system based on transfer learning with negative transfer
inhibition. KDD, 2018.
[13] J. Devlin et al. Bert: Pre-training of deep bidirectional transformers for language understanding. NAACL, 2018.
[14] J. Gou et al. Knowledge distillation: A survey. International Journal of Computer Vision, pages 1–31, 2021.
[15] J. Quionero-Candela et al. Dataset shift in machine learning. The MIT Press, 2009.
[16] L. Duan et al. Learning with augmented features for heterogeneous domain adaptation. ICML, 2012.
[17] L. Franceschi et al. Forward and reverse gradient-based hyperparameter optimization. 2017.
松井 (名古屋大) 転移学習の基礎 まとめ 40 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-47-320.jpg)
![[18] M. Sugiyama et al. Density ratio estimation in machine learning. Cambridge University Press, 2012.
[19] N. Courty et al. Optimal transport for domain adaptation. IEEE transactions on pattern analysis and machine
intelligence, 39(9):1853–1865, 2016.
[20] S. Ben-David et al. A theory of learning from different domains. Machine learning, 79(1):151–175, 2010.
[21] S. Kuroki et al. Unsupervised domain adaptation based on source-guided discrepancy. 2019.
[22] T. Brown et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
[23] T. Teshima et al. Few-shot domain adaptation by causal mechanism transfer. 2020.
[24] V. Veeriah et al. Discovery of useful questions as auxiliary tasks. NeurIPS, 2019.
[25] Y. Chen et al. Learning to learn without gradient descent by gradient descent. 2017.
[26] Y. Duan et al. Rl ˆ2: Fast reinforcement learning via slow reinforcement learning. arXiv preprint
arXiv:1611.02779, 2016.
[27] Y. Ganin et al. Domain-adversarial training of neural networks. JMLR, 17(1):2096–2030, 2016.
[28] Y. Li et al. Feature-critic networks for heterogeneous domain generalization. 2019.
[29] T. Iwata and M. Yamada. Multi-view anomaly detection via robust probabilistic latent variable models.
NeurIPS, 2016.
[30] S. Ravi and H. Larochelle. Optimization as a model for few-shot learning. 2017.
[31] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. 2014.
松井 (名古屋大) 転移学習の基礎 まとめ 41 / 41](https://image.slidesharecdn.com/os2-02final-210610091211/85/SSII2021-OS2-01-48-320.jpg)

SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法 6月10日 (木) 11:00 - 12:30 メイン会場(vimeo + sli.do) 登壇者:松井 孝太 氏(名古屋大学) 概要:転移学習とは、解きたいタスクに対して、それと異なるが似ている他のタスクからの知識(データ、特徴、モデルなど)を利用するための方法を与える機械学習のフレームワークです。深層モデルの学習方法として広く普及している事前学習モデルの利用は、この広義の転移学習の一つの実現形態とみなせます。本発表では、まず何をいつ転移するのか (what/when to transfer) といった転移学習の基本概念と定式化を説明し、具体的な転移学習の主要なアプローチとしてドメイン適応、メタ学習について解説します。

![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning to Generalize: Meta-Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20180208-180209000942-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)













![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-03] スケーラブルなロボット学習システムに向けて](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-03-220607020929-1e2b15e8-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-01] 深層学習のための効率的なデータ収集と活用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-01-220607020740-e80781dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS2-01] イメージング最前線](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os2-1-220607020403-b550c379-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS1-01] AI時代のチームビルディング](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os1-01-220607015404-49188612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS2] Deepfake Generation and Detection – An Overview (ディープフェイクの生成と検出)](https://cdn.slidesharecdn.com/ss_thumbnails/ss2-01-210607043612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS3] 機械学習のアノテーションにおける データ収集 〜 精度向上のための仕組み・倫理や社会性バイアス 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts3-01-210607043121-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-03] 画像と点群を用いた、森林という広域空間のゾーニングと施業管理](https://cdn.slidesharecdn.com/ss_thumbnails/os3-04-210605062524-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-02] BIM/CIMにおいて安価に点群を取得する目的とその利活用](https://cdn.slidesharecdn.com/ss_thumbnails/os3-03-210605062350-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-01] 設備や環境の高品質計測点群取得と自動モデル化技術](https://cdn.slidesharecdn.com/ss_thumbnails/os3-02-210605062048-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3] 広域環境の3D計測と認識 ~ 人が活動する場のセンシングとモデル化 ~(オーガナイザーによる冒頭の導入)](https://cdn.slidesharecdn.com/ss_thumbnails/os3-01-210605061816-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)