Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takahiro Kubo
PDF, PPTX
30,196 views
機械学習で泣かないためのコード設計 2018
機械学習モデルを作成する際のコード設計についての解説
Data & Analytics
◦
Read more
79
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 52
2
/ 52
Most read
3
/ 52
4
/ 52
5
/ 52
6
/ 52
Most read
7
/ 52
8
/ 52
9
/ 52
10
/ 52
11
/ 52
12
/ 52
13
/ 52
14
/ 52
15
/ 52
16
/ 52
17
/ 52
18
/ 52
19
/ 52
20
/ 52
21
/ 52
22
/ 52
23
/ 52
24
/ 52
25
/ 52
Most read
26
/ 52
27
/ 52
28
/ 52
29
/ 52
30
/ 52
31
/ 52
32
/ 52
33
/ 52
34
/ 52
35
/ 52
36
/ 52
37
/ 52
38
/ 52
39
/ 52
40
/ 52
41
/ 52
42
/ 52
43
/ 52
44
/ 52
45
/ 52
46
/ 52
47
/ 52
48
/ 52
49
/ 52
50
/ 52
51
/ 52
52
/ 52
More Related Content
PDF
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
PDF
生成AIの回答内容の修正を課題としたレポートについて:お茶の水女子大学「授業・研究における生成系AIの活用事例」での講演資料
by
Takayuki Itoh
PDF
楽しい研究のために今からできること 〜新しく研究を始める皆さんへ〜
by
諒介 荒木
PPTX
劣モジュラ最適化と機械学習 3章
by
Hakky St
PPTX
論文の書き方・読み方
by
Satoshi Miura
PDF
プレゼン・ポスターで自分の研究を「伝える」 (How to do technical oral/poster presentation)
by
Toshihiko Yamasaki
PDF
ブレインパッドにおける機械学習プロジェクトの進め方
by
BrainPad Inc.
PPTX
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
by
Tenki Lee
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
生成AIの回答内容の修正を課題としたレポートについて:お茶の水女子大学「授業・研究における生成系AIの活用事例」での講演資料
by
Takayuki Itoh
楽しい研究のために今からできること 〜新しく研究を始める皆さんへ〜
by
諒介 荒木
劣モジュラ最適化と機械学習 3章
by
Hakky St
論文の書き方・読み方
by
Satoshi Miura
プレゼン・ポスターで自分の研究を「伝える」 (How to do technical oral/poster presentation)
by
Toshihiko Yamasaki
ブレインパッドにおける機械学習プロジェクトの進め方
by
BrainPad Inc.
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
by
Tenki Lee
What's hot
PDF
(修正)機械学習デザインパターン(ML Design Patterns)の解説
by
Hironori Washizaki
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
by
SSII
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PPTX
学習時に使ってはいないデータの混入「リーケージを避ける」
by
西岡 賢一郎
PDF
機械学習で泣かないためのコード設計
by
Takahiro Kubo
PDF
最適化超入門
by
Takami Sato
PDF
AHC-Lab M1勉強会 論文の読み方・書き方
by
Shinagawa Seitaro
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PDF
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PDF
全力解説!Transformer
by
Arithmer Inc.
PDF
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
PDF
研究発表を準備する(2022年版)
by
Takayuki Itoh
(修正)機械学習デザインパターン(ML Design Patterns)の解説
by
Hironori Washizaki
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
by
SSII
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
学習時に使ってはいないデータの混入「リーケージを避ける」
by
西岡 賢一郎
機械学習で泣かないためのコード設計
by
Takahiro Kubo
最適化超入門
by
Takami Sato
AHC-Lab M1勉強会 論文の読み方・書き方
by
Shinagawa Seitaro
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
Optimizer入門&最新動向
by
Motokawa Tetsuya
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
全力解説!Transformer
by
Arithmer Inc.
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
研究発表を準備する(2022年版)
by
Takayuki Itoh
Similar to 機械学習で泣かないためのコード設計 2018
PPTX
「機械学習:技術的負債の高利子クレジットカード」のまとめ
by
Recruit Technologies
PDF
機械学習の力を引き出すための依存性管理
by
Takahiro Kubo
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PPTX
Deep learningの世界に飛び込む前の命綱
by
Junya Kamura
PPTX
機械学習を活用するための、3本の柱~教育型の機械学習ツールの必要性~
by
Takahiro Kubo
PPTX
Hidden technical debt in machine learning systems(日本語資料)
by
Ogushi Masaya
PPTX
全脳関西編(松尾)
by
Yutaka Matsuo
PPTX
Machine Learning Fundamentals IEEE
by
Antonio Tejero de Pablos
PPTX
機械学習の基礎
by
Ken Kumagai
PPTX
Machine learning
by
Masafumi Noda
PPTX
[輪講] 第1章
by
Takenobu Sasatani
PDF
Deep learning勉強会20121214ochi
by
Ohsawa Goodfellow
PDF
スタートアップが提案する2030年の材料開発 - 2022/11/11 QPARC講演
by
Preferred Networks
PPTX
20171015 mosa machine learning
by
Muneyoshi Benzaki
PDF
機械学習デザインパターン Machine Learning Design Patterns
by
Hironori Washizaki
PDF
Ml system in_python
by
yusuke shibui
PDF
Machine learning CI/CD with OSS
by
yusuke shibui
PDF
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
PDF
[RIT]MLmodeling service
by
RIT
PDF
第1回 Jubatusハンズオン
by
JubatusOfficial
「機械学習:技術的負債の高利子クレジットカード」のまとめ
by
Recruit Technologies
機械学習の力を引き出すための依存性管理
by
Takahiro Kubo
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
Deep learningの世界に飛び込む前の命綱
by
Junya Kamura
機械学習を活用するための、3本の柱~教育型の機械学習ツールの必要性~
by
Takahiro Kubo
Hidden technical debt in machine learning systems(日本語資料)
by
Ogushi Masaya
全脳関西編(松尾)
by
Yutaka Matsuo
Machine Learning Fundamentals IEEE
by
Antonio Tejero de Pablos
機械学習の基礎
by
Ken Kumagai
Machine learning
by
Masafumi Noda
[輪講] 第1章
by
Takenobu Sasatani
Deep learning勉強会20121214ochi
by
Ohsawa Goodfellow
スタートアップが提案する2030年の材料開発 - 2022/11/11 QPARC講演
by
Preferred Networks
20171015 mosa machine learning
by
Muneyoshi Benzaki
機械学習デザインパターン Machine Learning Design Patterns
by
Hironori Washizaki
Ml system in_python
by
yusuke shibui
Machine learning CI/CD with OSS
by
yusuke shibui
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
[RIT]MLmodeling service
by
RIT
第1回 Jubatusハンズオン
by
JubatusOfficial
More from Takahiro Kubo
PDF
自然言語処理による企業の気候変動対策分析
by
Takahiro Kubo
PDF
国際会計基準(IFRS)適用企業の財務評価方法
by
Takahiro Kubo
PDF
自然言語処理で新型コロナウィルスに立ち向かう
by
Takahiro Kubo
PDF
財務・非財務一体型の企業分析に向けて
by
Takahiro Kubo
PDF
自然言語処理で読み解く金融文書
by
Takahiro Kubo
PDF
arXivTimes Review: 2019年前半で印象に残った論文を振り返る
by
Takahiro Kubo
PPTX
ESG評価を支える自然言語処理基盤の構築
by
Takahiro Kubo
PDF
Expressing Visual Relationships via Language: 自然言語による画像編集を目指して
by
Takahiro Kubo
PDF
Reinforcement Learning Inside Business
by
Takahiro Kubo
PDF
あるべきESG投資の評価に向けた、自然言語処理の活用
by
Takahiro Kubo
PDF
nlpaper.challenge NLP/CV交流勉強会 画像認識 7章
by
Takahiro Kubo
PDF
Curiosity may drives your output routine.
by
Takahiro Kubo
PDF
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
PDF
EMNLP2018 Overview
by
Takahiro Kubo
PPTX
2018年12月4日までに『呪術廻戦』を読む理由
by
Takahiro Kubo
PDF
Graph Attention Network
by
Takahiro Kubo
PDF
ACL2018の歩き方
by
Takahiro Kubo
PDF
TISにおける、研究開発の方針とメソッド 2018
by
Takahiro Kubo
PDF
感情の出どころを探る、一歩進んだ感情解析
by
Takahiro Kubo
PDF
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio...
by
Takahiro Kubo
自然言語処理による企業の気候変動対策分析
by
Takahiro Kubo
国際会計基準(IFRS)適用企業の財務評価方法
by
Takahiro Kubo
自然言語処理で新型コロナウィルスに立ち向かう
by
Takahiro Kubo
財務・非財務一体型の企業分析に向けて
by
Takahiro Kubo
自然言語処理で読み解く金融文書
by
Takahiro Kubo
arXivTimes Review: 2019年前半で印象に残った論文を振り返る
by
Takahiro Kubo
ESG評価を支える自然言語処理基盤の構築
by
Takahiro Kubo
Expressing Visual Relationships via Language: 自然言語による画像編集を目指して
by
Takahiro Kubo
Reinforcement Learning Inside Business
by
Takahiro Kubo
あるべきESG投資の評価に向けた、自然言語処理の活用
by
Takahiro Kubo
nlpaper.challenge NLP/CV交流勉強会 画像認識 7章
by
Takahiro Kubo
Curiosity may drives your output routine.
by
Takahiro Kubo
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
EMNLP2018 Overview
by
Takahiro Kubo
2018年12月4日までに『呪術廻戦』を読む理由
by
Takahiro Kubo
Graph Attention Network
by
Takahiro Kubo
ACL2018の歩き方
by
Takahiro Kubo
TISにおける、研究開発の方針とメソッド 2018
by
Takahiro Kubo
感情の出どころを探る、一歩進んだ感情解析
by
Takahiro Kubo
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio...
by
Takahiro Kubo
機械学習で泣かないためのコード設計 2018
1.
Copyright © TIS
Inc. All rights reserved. 機械学習で泣かないためのコード設計 2018 戦略技術センター 久保隆宏 Don't cry anymore when creating machine learning model
2.
Copyright © TIS
Inc. All rights reserved. 2 ◼ はじめに ◼ 機械学習モデルの開発における問題点 ◼ 原因の特定が難しい ◼ コード上で管理できない依存が発生する ◼ 処理に必要な静的ファイルが多い ◼ 設計による問題の解決 ◼ 機械学習モデル開発におけるモジュール構成 ◼ 構成のポイント ◼ vs問題の切り分けが難しい ◼ vsコード上で管理できない依存が発生する ◼ vs処理に必要な静的ファイルが多い ◼ おわりに 目次
3.
Copyright © TIS
Inc. All rights reserved. 3 本資料では機械学習モデルの開発における問題点を整理し、それを設計に より解決するための方法について提案します。 ◼ 要件定義については触れていません。要件に沿っていないモデルはど れだけうまく設計しても効果が出ないため、注意してください。 ◼ 設計だけでなく、運用により問題解決を行う方法もあります(特に機械 学習モデルのホスティングサービスの活用など)。これについては、簡 単に触れます。 はじめに
4.
Copyright © TIS
Inc. All rights reserved. 4 久保隆宏 TIS株式会社 戦略技術センター ◼ 化学系メーカーの業務コンサルタント出身 ◼ 既存の技術では業務改善を行える範囲に限界があるとの実感から、戦 略技術センターへと異動 ◼ 現在は機械学習や自然言語処理の研究・それらを用いたシステムのプ ロトタイピングを行う 自己紹介 kintoneアプリ内にたまった データを簡単に学習・活用 (@Cybozu Days 2016) チュートリアル講演:深層学習 の判断根拠を理解するための研 究とその意義(@PRMU 2017) 機械学習をシステムに組み込む 際の依存性管理について (@MANABIYA 2018)
5.
Copyright © TIS
Inc. All rights reserved. 5 chakkiのミッション Summarize data for human あらゆるデータを、人間にとってわかりやすく要約 することを目指します。 chakkiが目指す機能: ◼ 要約の観点を、なるべく少ないデータで学習する ◼ 自然言語以外の、画像や数値データの要約も扱う ◼ 図や表といった表現形態にも挑戦する この機能の実現を通じ、最終的にはいつでもティー タイム(15:00)に帰れる(=茶帰)社会を目指します。 2018年度より具体化
6.
Copyright © TIS
Inc. All rights reserved. 6 観点を指定した自然言語処理 観点単位にまとめることで、情報の欠落を 防ぐと共に図表化を行いやすくする。 モデルにお任せで「こんなん出ました」で なく、利用者が出力をコントロールする。 ex: 観点要約 ペンギンのサイズは小さくて、手触りは冷たい。 ◼ 「サイズ」は「小さく」 ◼ 「手触り」は「冷たい」 サイズ 手触り ペンギン 小さい 冷たい ライオン 大きい 温かい ウサギ 中くらい 温かい 業務要件により観点は異なる。そして、観点の学習データは少ない。 ⇒自然言語処理における転移学習に注力し、「少ないデータでカスタマ イズ可能な分類/生成器の作成」を目指している。 (2/3)
7.
Copyright © TIS
Inc. All rights reserved. 7 (3/3) ◼ 研究開発活動は基本オープンに行っている(GitHub★総計 800以上)。 ◼ 研究に関することであれば、個人のブログ/リポジトリも評価される。 機械学習関連の論文のまとめをGitHubのIssueを使って行っ ています。月一での輪講も開催中です。
8.
機械学習モデルの開発における問題点
9.
Copyright © TIS
Inc. All rights reserved. 9 機械学習の開発におけるプロセスは、以下のように図式化できる。 今回扱う問題は、この各プロセスで発生するものとなっている。 機械学習モデルの開発における問題点(1/3) モデル定義コード パラメーター設定 予測 学習用コード 予測(API用)コード 開発 学習 配置(デプロイ) 学習データ モデルファイル学習
10.
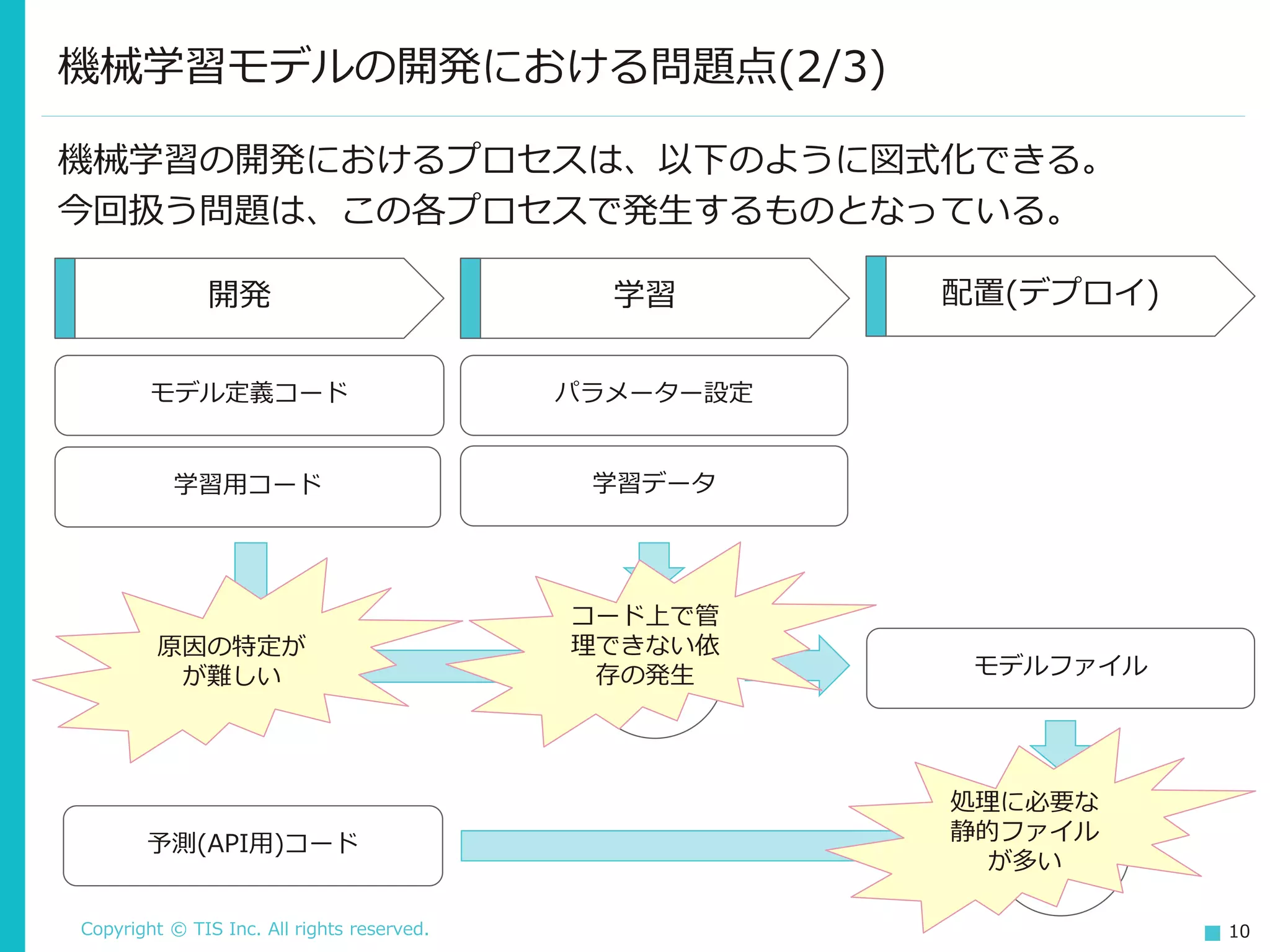
Copyright © TIS
Inc. All rights reserved. 10 機械学習の開発におけるプロセスは、以下のように図式化できる。 今回扱う問題は、この各プロセスで発生するものとなっている。 機械学習モデルの開発における問題点(2/3) 開発 学習 配置(デプロイ) モデル定義コード パラメーター設定 予測 学習用コード 予測(API用)コード 学習データ モデルファイル学習 原因の特定が が難しい コード上で管 理できない依 存の発生 処理に必要な 静的ファイル が多い
11.
Copyright © TIS
Inc. All rights reserved. 11 機械学習モデルの開発における問題点(3/3) 今回扱う課題は、以下の3つとなる。 ◼ 開発時: 原因の特定が難しい ◼ 学習がうまくいかないなどの問題が発生した際に、その原因を特定 するのが難しい ◼ 学習時: コード上で管理できない依存が発生する ◼ 学習させる時だけ指定するパラメーターが数多くあり、それらが (モデルの再現に必要な情報にもかかわらず)どこにも残らない。 ◼ 配置時: 処理に必要な静的ファイルが多い ◼ 予測処理を行う際、機械学習モデルだけでなく前処理のパラメー ターを保存したファイルや入力/出力を変換するための辞書など、 多くのファイルに依存する。
12.
Copyright © TIS
Inc. All rights reserved. 12 原因の特定が難しい(1/6) ◼ 開発時: 原因の特定が難しい ◼ 学習時: コード上で管理できない依存が発生する ◼ 配置時: 処理に必要な静的ファイルが多い
13.
Copyright © TIS
Inc. All rights reserved. 13 原因の特定が難しい(2/6) 機械学習モデルの開発では、うまく動かない際にその原因として考えられ る要素が数多くある。 ◼ モデルに原因がある ◼ 選択したモデルが問題に適していない ◼ モデルの構成(レイヤ構成など)に問題がある ◼ データに原因がある ◼ データの量、あるいは質に問題がある ◼ 前処理に問題がある ◼ 学習方法に原因がある ◼ 目的関数、初期化方法、学習率、オプティマイザとその設定etc ◼ 辛抱が足りない(明日になれば学習が進んでいるかも) ◼ 蜃気楼の学習結果(あの時はたまたま収束した) ◼ その他 ◼ 実装に使っているフレームワークの差異
14.
Copyright © TIS
Inc. All rights reserved. 14 原因の特定が難しい: 実例(3/6) 前処理に問題があった例 (from OpenAI Baselines: DQN) ゲームの学習を行う際、前処理として画像をグレースケールにしたら敵 キャラのアイコンも消えてしまった。
15.
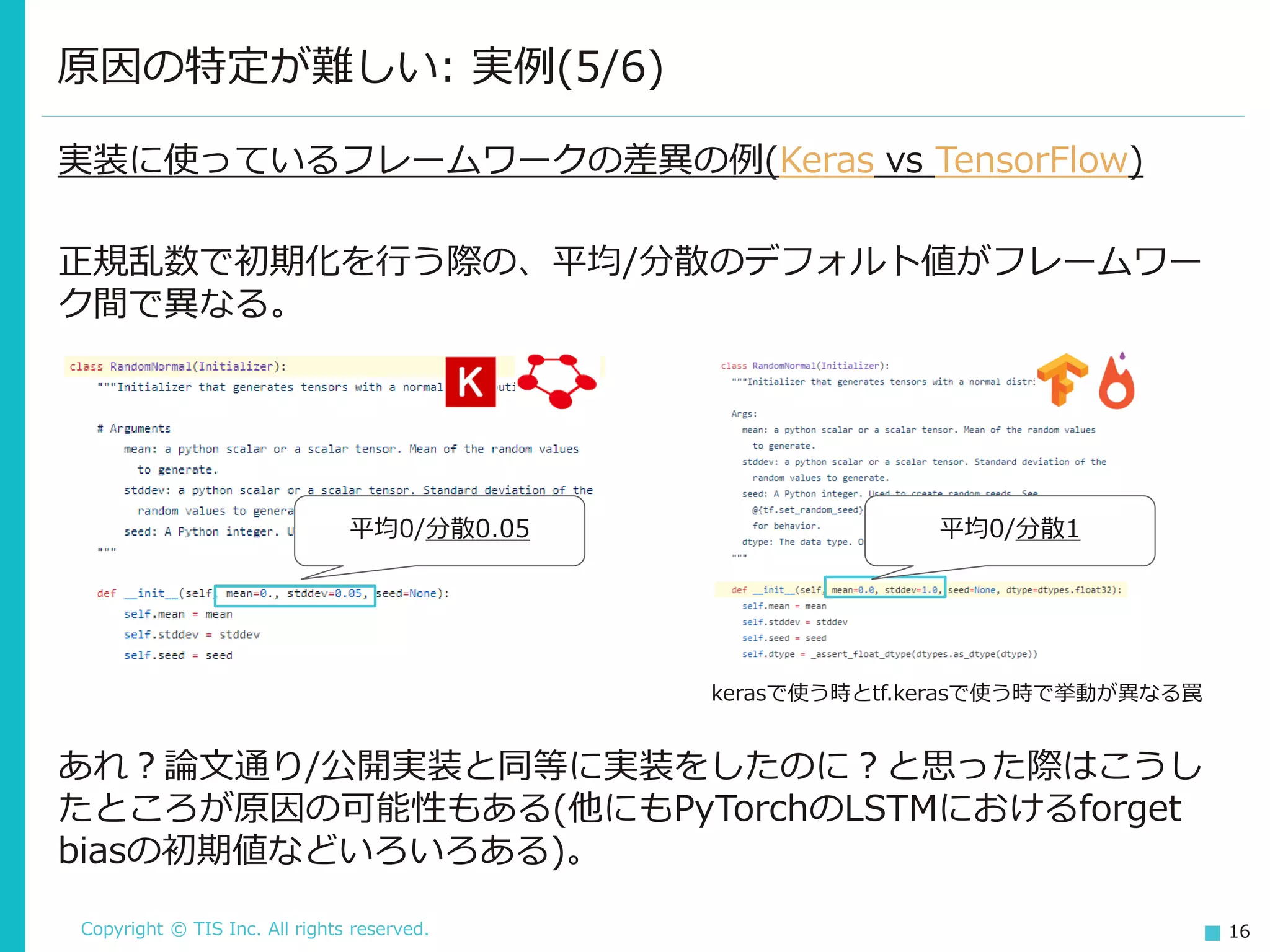
Copyright © TIS
Inc. All rights reserved. 15 原因の特定が難しい: 実例(4/6) 蜃気楼の学習結果の例 (from Deep Reinforcement Learning that Matters) 同じハイパーパラメーターでも、乱数のシードで結果に差が出る。 調子がいい時のスコア 調子が悪い時のスコア ※強化学習で顕著な例で、画像や自然言語処理など他ではここまでひどく はない(体感的に)。
16.
Copyright © TIS
Inc. All rights reserved. 16 原因の特定が難しい: 実例(5/6) 実装に使っているフレームワークの差異の例(Keras vs TensorFlow) 正規乱数で初期化を行う際の、平均/分散のデフォルト値がフレームワー ク間で異なる。 kerasで使う時とtf.kerasで使う時で挙動が異なる罠 あれ?論文通り/公開実装と同等に実装をしたのに?と思った際はこうし たところが原因の可能性もある(他にもPyTorchのLSTMにおけるforget biasの初期値などいろいろある)。 平均0/分散0.05 平均0/分散1
17.
Copyright © TIS
Inc. All rights reserved. 17 原因の特定が難しい(6/6) 機械学習がうまくいかない=モデルの問題と思いがちだが、実際はあらゆ る箇所に落とし穴がある。 穴の数が多く、回避方法(調整するパラメーターの数と値の範囲)も多く、 結果を確認するのにも時間がかかるため、原因の特定が難しい。
18.
Copyright © TIS
Inc. All rights reserved. 18 コード上で管理できない依存が発生する(1/3) ◼ 開発時: 原因の特定が難しい ◼ 学習時: コード上で管理できない依存が発生する ◼ 配置時: 処理に必要な静的ファイルが多い
19.
Copyright © TIS
Inc. All rights reserved. 19 コード上で管理できない依存が発生する(2/3) 学習の結果生成される「機械学習モデル」は、ソースコード以外の要素へ の依存を内包することになる。 ◼ 学習に使ったデータ ◼ 学習時のハイパーパラメーター つまり、コードがあるからといって機械学習モデルが再現できるとは限ら ない。同じコード(モデル)でも、実行条件により精度は大きく異なる。 > model.train --dataset=./data/faces/20180101 --epoch 25 -- lr=0.0002 --batch_size=64
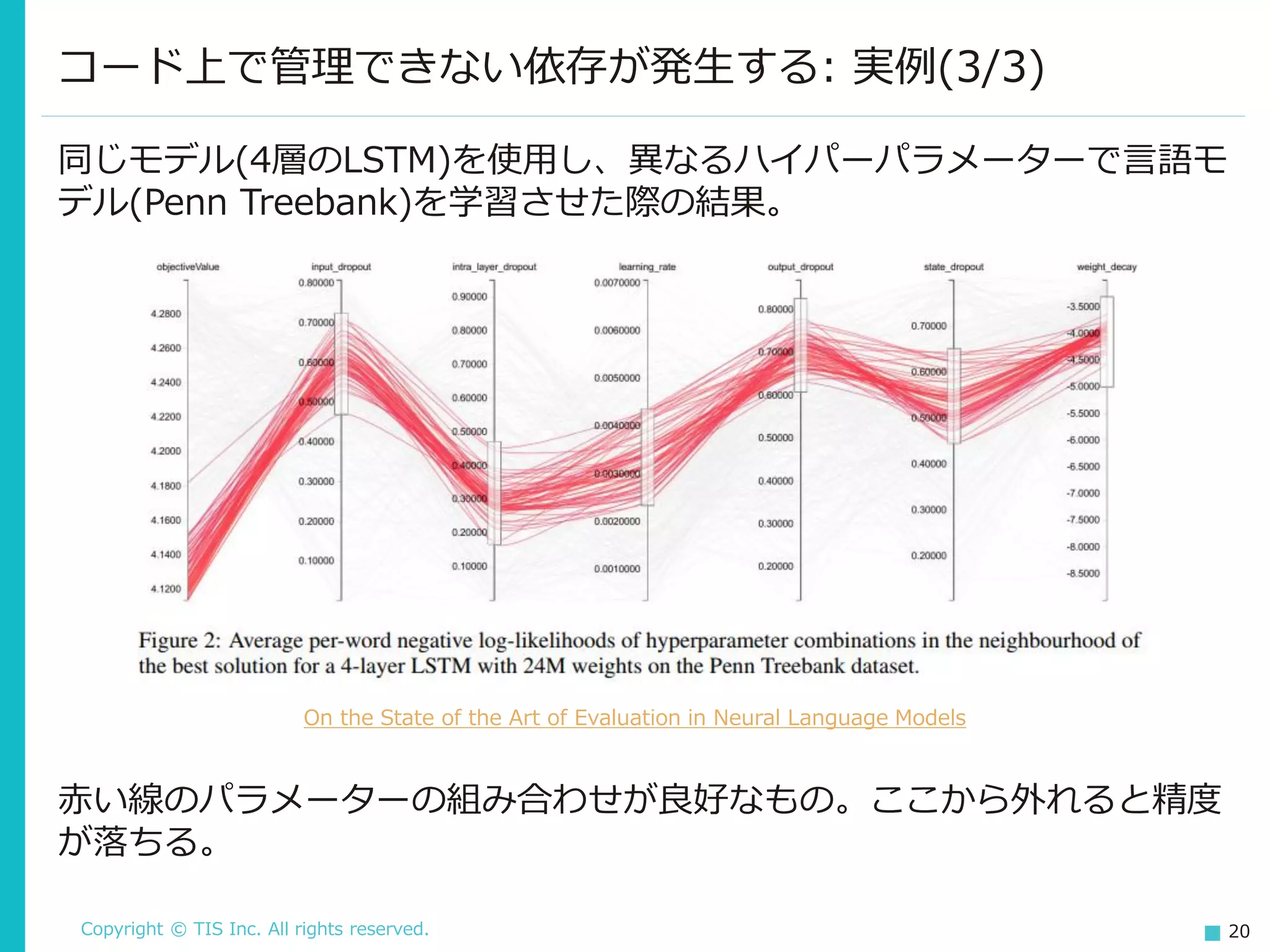
20.
Copyright © TIS
Inc. All rights reserved. 20 コード上で管理できない依存が発生する: 実例(3/3) 同じモデル(4層のLSTM)を使用し、異なるハイパーパラメーターで言語モ デル(Penn Treebank)を学習させた際の結果。 On the State of the Art of Evaluation in Neural Language Models 赤い線のパラメーターの組み合わせが良好なもの。ここから外れると精度 が落ちる。
21.
Copyright © TIS
Inc. All rights reserved. 21 処理に必要な静的ファイルが多い(1/2) ◼ 開発時: 原因の特定が難しい ◼ 学習時: コード上で管理できない依存が発生する ◼ 配置時: 処理に必要な静的ファイルが多い
22.
Copyright © TIS
Inc. All rights reserved. 22 処理に必要な静的ファイルが多い(2/2) 機械学習モデルを利用して予測を行う際は、多くの静的ファイルに依存す る。 ◼ モデルファイル ◼ 学習の結果生成されたモデルファイル ◼ 前処理のパラメーター(データの平均/分散など) ◼ 学習時に前処理をしていれば、予測時も前処理が必要。 ◼ 入力/予測結果を変換するための辞書 ◼ モデルへの入力/モデルからの出力は数値(0,1,2...)なので、数値が 表す意味を変換する辞書(0=>猫、1=>犬など)が必要。 これらの静的ファイルはサイズが非常に大きい場合もあり(数Gなど)、 ソースコードと同じリポジトリに含めて管理することが難しい。
23.
Copyright © TIS
Inc. All rights reserved. 23 機械学習モデルの開発における問題点 機械学習モデルの開発における問題点を解決するには、「学習」はもちろ んそれに使用されるデータやパラメーターなど、機械学習を取り巻く要素 を含めて設計を行う必要がある。 機械学習は「機械」だけで完結しない 機械=モデルを定義したソースコード、モデルファイル
24.
設計による問題の解決
25.
Copyright © TIS
Inc. All rights reserved. 25 構成(2018年版) Storage Dataset Model train Transform er fit load save save load feed transform batch Trainer Experiment ModelAPI Model Transform er data transform predict ■Dataset データセットの取得を行う ■Transformer 前処理/後処理を行う ■Trainer モデルの学習を行う ■Model 機械学習モデルを定義する ■ModelAPI モデルによる予測を行う ■Experiment 学習条件を記述する ■Storage ファイルの配置を管理する
26.
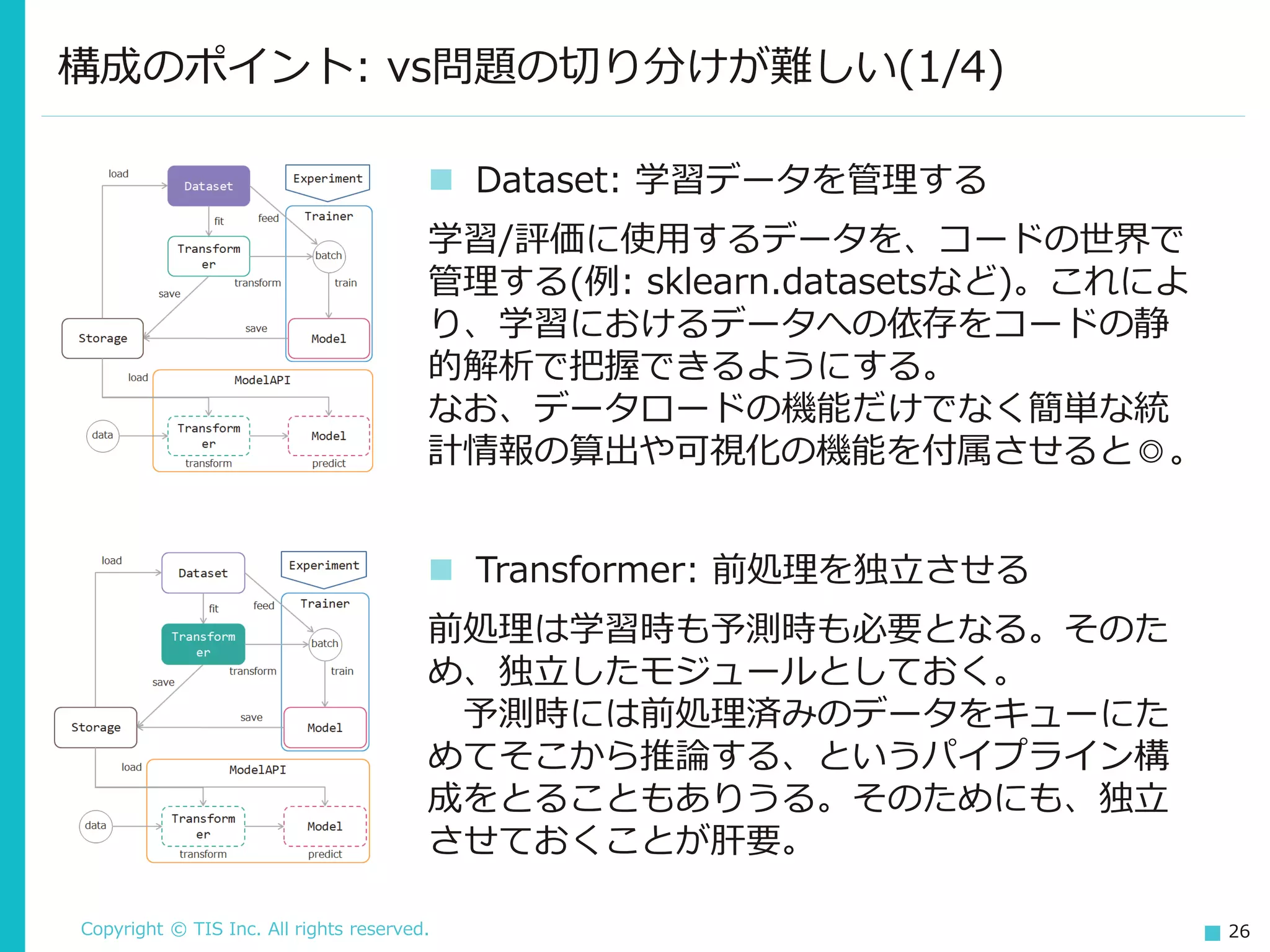
Copyright © TIS
Inc. All rights reserved. 26 ◼ Transformer: 前処理を独立させる 前処理は学習時も予測時も必要となる。そのた め、独立したモジュールとしておく。 予測時には前処理済みのデータをキューにた めてそこから推論する、というパイプライン構 成をとることもありうる。そのためにも、独立 させておくことが肝要。 構成のポイント: vs問題の切り分けが難しい(1/4) ◼ Dataset: 学習データを管理する 学習/評価に使用するデータを、コードの世界で 管理する(例: sklearn.datasetsなど)。これによ り、学習におけるデータへの依存をコードの静 的解析で把握できるようにする。 なお、データロードの機能だけでなく簡単な統 計情報の算出や可視化の機能を付属させると◎。
27.
Copyright © TIS
Inc. All rights reserved. 27 ◼ ModelAPI: 利用側からモデルを隠ぺいする 生のModelは実装に利用したフレームワークで 書かれており、予測を行う際もそのフレーム ワークの作法に則る必要がある(特に TensorFlowの場合のsess.runなど)。 利用する側への負担を少なくするため、利用側 は一般的な変数から利用できるようにする。 REST API化なども選択肢になる。 構成のポイント: vs問題の切り分けが難しい(2/4) ◼ Trainer: 学習とモデル定義を分離する 最終的にモデルを利用する際は予測だけできれ ば良いので、モデルの定義に学習のための要素 (具体的には目的関数やオプティマイザの定義、 ましてや学習のためのハイパーパラメーター)を 含めてしまうと、予測の際もそれらが付随して しまう。
28.
Copyright © TIS
Inc. All rights reserved. 28 構成のポイント: vs問題の切り分けが難しい(3/4) モジュールを分割することで、責任範囲を明確にすることができる。 ◼ モデルに原因がある ◼ Modelの確認 ◼ データに原因がある ◼ Datasetを通じたデータの分析 ◼ Transformerの単体テストによる動作チェック ◼ 学習方法に原因がある ◼ Trainerの確認 ◼ Experimentsの実行(次スライド) ◼ その他: API経由で利用するとうまく動かない ◼ Model APIの確認 特に、「データに原因がある」ケースについてはDataset/Transformerの チェックにより事前に洗い出すことが可能。
29.
Copyright © TIS
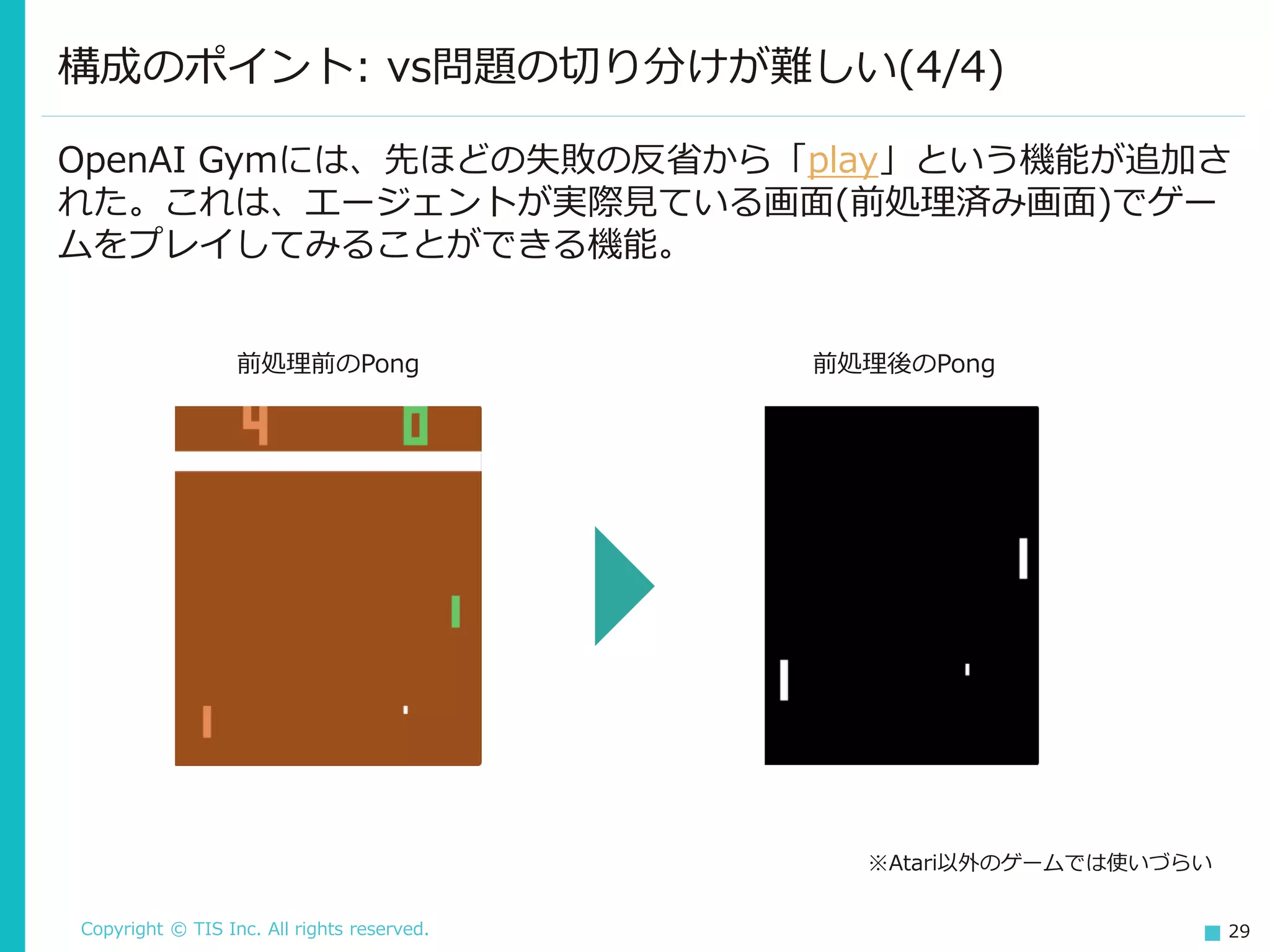
Inc. All rights reserved. 29 構成のポイント: vs問題の切り分けが難しい(4/4) OpenAI Gymには、先ほどの失敗の反省から「play」という機能が追加さ れた。これは、エージェントが実際見ている画面(前処理済み画面)でゲー ムをプレイしてみることができる機能。 前処理前のPong 前処理後のPong ※Atari以外のゲームでは使いづらい
30.
Copyright © TIS
Inc. All rights reserved. 30 構成のポイント: vsコード上で管理できない依存(1/3) ◼ Dataset/Experiment: 学習をコード化する Model/Trainerに対する単体テスト的に、各学 習をExperimentとして実装する。 Datasetとしてサンプルデータを使用し forward/backwardの確認、Modelとしてベー スラインとなるモデルを使用することで結果比 較なども行える。 from datasets import face_image from trainer import Trainer from model import Model data = face_image.load(“v1”) trainer = Trainer(Model()) trainer.train(data=data, epoch=25, lr=0.0002, batch_size=64) experiments_1.py
31.
Copyright © TIS
Inc. All rights reserved. 31 構成のポイント: vsコード上で管理できない依存(2/3) ◼ コマンドライン引数ではだめなのか? 画面はCloud MLのもの ◼ 確実にログを残す方法がない。 ◼ ただ、機械学習のホスティング サービスが提供する機能で賄え るようになる可能性はある。
32.
Copyright © TIS
Inc. All rights reserved. 32 構成のポイント: vsコード上で管理できない依存(3/3) ◼ 指定するハイパーパラメーターのバリエーションは無数にあり、それ 毎にExperimentを用意すると膨大な数になってしまうのでは? ◼ 本当に効くパラメーターの数と範囲はそれほど多くない。 ◼ パラメーターサーチが必要な場合は、パラメーターサーチを行う Experimentを作る。 ◼ 実験をスクリプト化することで、開発者の時間の浪費(ちょっとパ ラメーターを変えてlossを眺める無限ループ)を防ぐことができる。 ◼ ファイルにパラメーターをまとめて読み込ませるのではいけないのか? ◼ ソースコードで記述することで、ソースコードの静的解析により DatasetやModelの使用先(依存関係)を洗い出すことができる。
33.
Copyright © TIS
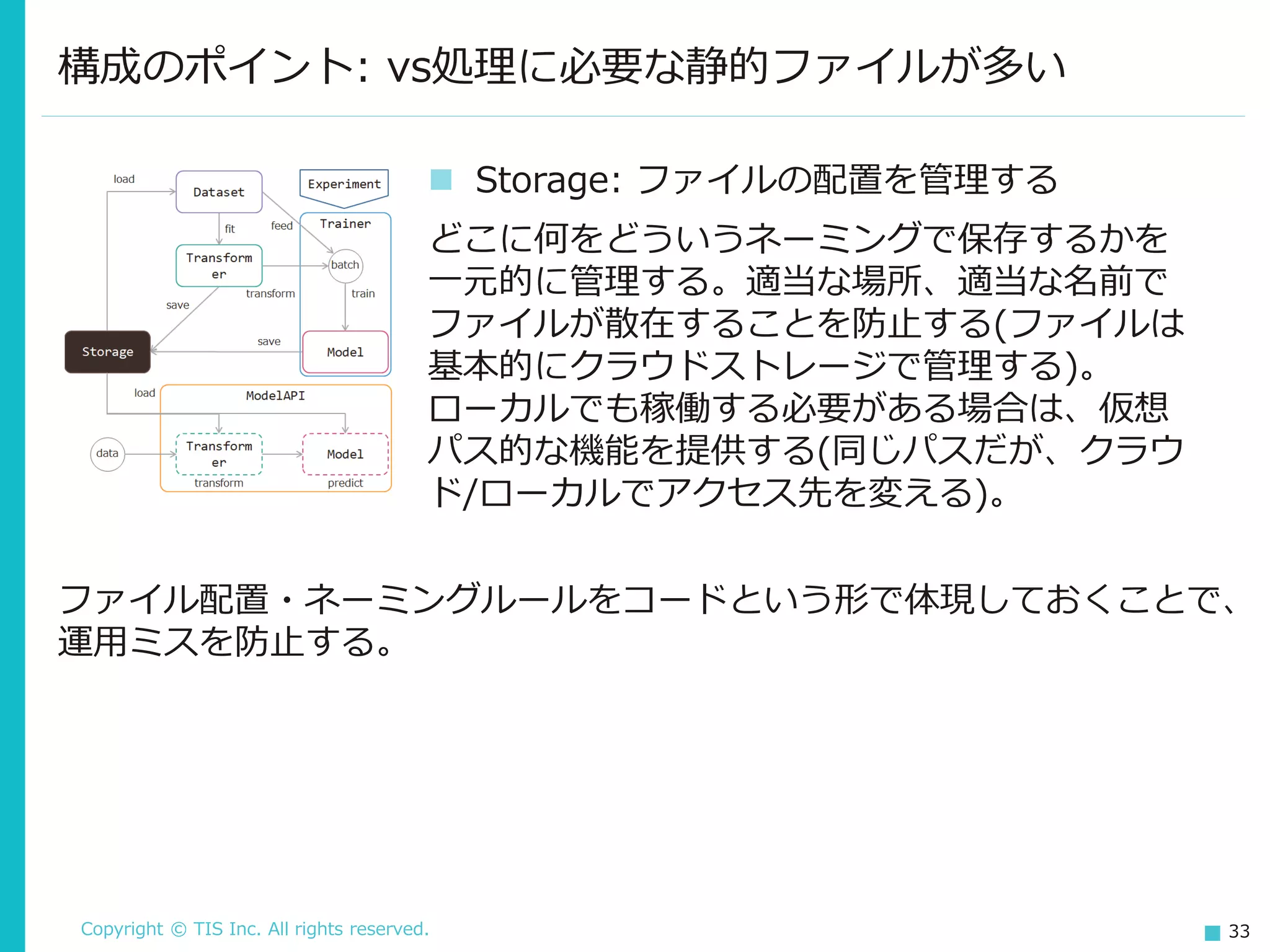
Inc. All rights reserved. 33 構成のポイント: vs処理に必要な静的ファイルが多い ◼ Storage: ファイルの配置を管理する どこに何をどういうネーミングで保存するかを 一元的に管理する。適当な場所、適当な名前で ファイルが散在することを防止する(ファイルは 基本的にクラウドストレージで管理する)。 ローカルでも稼働する必要がある場合は、仮想 パス的な機能を提供する(同じパスだが、クラウ ド/ローカルでアクセス先を変える)。 ファイル配置・ネーミングルールをコードという形で体現しておくことで、 運用ミスを防止する。
34.
Copyright © TIS
Inc. All rights reserved. 34 構成のポイント 紹介した構成は、基本的にはソフトウェア設計の基本原則である「単一責 任原則」に則り設計されている。 機械学習モデルの開発もソースコードを通じて行われるものであり、既 存のソフトウェア設計論は十二分に通用する。 むしろ、「機械学習だから」という形で特別扱いしないことが重要。 ◼ 機械学習だから1ファイルに全部処理をまとめていい ◼ 機械学習だからグローバル変数を気軽に使っていい ◼ 機械学習だから単体テストできない ...ということはない。システム開発者として「おかしい」と感じたら、そ れは本当におかしいので、対策を考える。
35.
おわりに
36.
Copyright © TIS
Inc. All rights reserved. 36 おわりに(1/3) はじめにで述べた通り、本資料では「機械学習モデルの開発」における 「設計」にフォーカスしており、前段階である要件定義や後段階である運 用については触れていない。 要件定義が終わった後の「機械学習モデルの開発・運用」という場面にお いて、本資料が触れた範囲はというと・・・
37.
Copyright © TIS
Inc. All rights reserved. 37 おわりに(2/3) 機械学習モデル のスケール 動作環境 プロジェクト 構成 学習基盤 テスト モデルの API化 コード管理 デプロイ パイプライン化 学習データ管理 デプロイ時 テスト パフォーマンス のスケール 耐障害性 のスケール 稼働監視 評価データ管理 バージョン管理 機械学習モデル のリリース 機械学習モデル の作成 コード設計 ここ
38.
Copyright © TIS
Inc. All rights reserved. 38 おわりに(3/3) もちろん、設計は多くの箇所に影響するため部分的に他の箇所の話題につ いても触れてはいる。ただ、それを差し引いてもまだ方法論が確立してい ない箇所は多い。 機械学習工学の道のりは始まったばかりだ!
39.
THANK YOU
40.
Copyright © TIS
Inc. All rights reserved. 40 Appendix1:機械学習モデルの開発/運用に関する課題の整理
41.
Copyright © TIS
Inc. All rights reserved. 41 機械学習モデルの開発/運用に関する課題の整理(1/2) 機械学習モデル のスケール 動作環境 プロジェクト 構成 学習基盤 テスト モデルの API化 コード管理 デプロイ パイプライン化 学習データ管理 デプロイ時 テスト パフォーマンス のスケール 耐障害性 のスケール 稼働監視 評価データ管理 バージョン管理 機械学習モデル のリリース 機械学習モデル の作成 コード設計
42.
Copyright © TIS
Inc. All rights reserved. 42 機械学習モデルの開発/運用に関する課題の整理(2/2) 機械学習モデル のスケール 機械学習モデル のリリース 機械学習モデル の作成 動作環境 プロジェクト 構成 学習基盤 テスト モデルの API化 コード管理 デプロイ パイプライン化 学習データ管理 デプロイ時 テスト パフォーマンス のスケール 耐障害性 のスケール 稼働監視 評価データ管理 バージョン管理 コード設計 やらないと死ぬ やるべき 要件次第
43.
Copyright © TIS
Inc. All rights reserved. 43 1. 機械学習モデルの作成 ◼ 機械学習モデルの開発・学習・評価を行う ◼ 生産性(学習時間・原因の特定)/再現性の高い開発プロセスの構築が課題 コード管理 プロジェクト 構成 動作環境 テスト/ 学習データ モデルのパッ ケージ化 学習基盤 機械学習モデルのソースコードを管理する。 ■ソースコードの共有を可能にしデグレードを防止する 機械学習モデルを開発する際の、プロジェクト構成を統一する。 ■共有のバッチスクリプトなどの開発を行いやすくする。 機械学習モデルを開発する環境を管理する。 ■ある環境で動いて別の環境で動かないという事態を防止する。 機械学習モデルをテストするためのテストケースを管理する。 ■短い時間・コストで動作や精度を評価できるようにすることで、 開発速度を上げる。 機械学習モデルのソース・環境をパッケージ化する ■デプロイや学習環境への配置を行いやすくする 機械学習モデルの学習を行うための高火力環境 ■学習にかかる時間を短縮し、開発速度を上げる コード設計 機械学習モデルの実装を適切なモジュールに分割する。 ■モジュールに分割することで、個別のテストを可能にする。
44.
Copyright © TIS
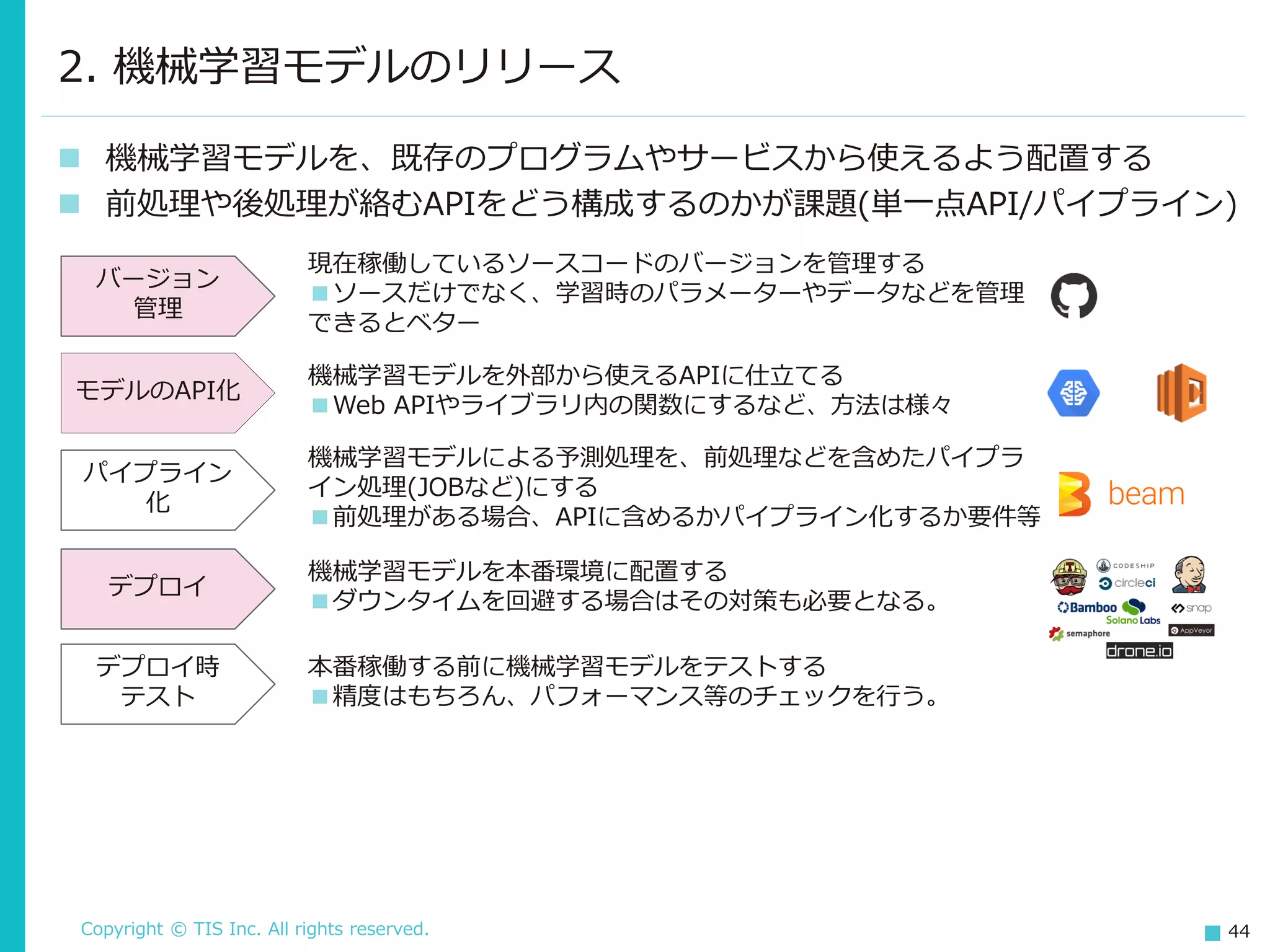
Inc. All rights reserved. 44 2. 機械学習モデルのリリース ◼ 機械学習モデルを、既存のプログラムやサービスから使えるよう配置する ◼ 前処理や後処理が絡むAPIをどう構成するのかが課題(単一点API/パイプライン) バージョン 管理 モデルのAPI化 パイプライン 化 デプロイ デプロイ時 テスト 現在稼働しているソースコードのバージョンを管理する ■ソースだけでなく、学習時のパラメーターやデータなどを管理 できるとベター 機械学習モデルを外部から使えるAPIに仕立てる ■Web APIやライブラリ内の関数にするなど、方法は様々 機械学習モデルによる予測処理を、前処理などを含めたパイプラ イン処理(JOBなど)にする ■前処理がある場合、APIに含めるかパイプライン化するか要件等 機械学習モデルを本番環境に配置する ■ダウンタイムを回避する場合はその対策も必要となる。 本番稼働する前に機械学習モデルをテストする ■精度はもちろん、パフォーマンス等のチェックを行う。
45.
Copyright © TIS
Inc. All rights reserved. 45 3. 機械学習モデルのスケール ◼ 機械学習による予測をサービスとしてスケールさせる ◼ 高速化や耐障害性の向上、モデル再学習のタイミングの検知などが課題 耐障害性の スケール パフォーマン スのスケール 稼働監視 予測を行うサーバーの耐障害性を高める ■サーバー停止を補い合えるようなインフラを導入する 機械学習モデルによる予測の速度を高める ■分散実行基盤や、オートスケールの導入など 機械学習モデルの稼働状況をチェックする ■特に再学習のタイミングを検知したりするために必要
46.
Copyright © TIS
Inc. All rights reserved. 46 Appendix2:開発をサポートするツール/サービス
47.
Copyright © TIS
Inc. All rights reserved. 47 ◼ CometML ◼ 機械学習モデルの学習ログを記録しておけるサービス(ログ管理の みで、演算機能はなし)。GitHubとの連携機能もあるため、コード と実験結果をひもつけて管理することができる。 ◼ Data Version Control ◼ Gitライクにデータのバージョン管理ができるツール。データはもち ろんクラウドストレージに保管可能。ファイル・コマンドの紐つけ 管理もでき、データと学習コマンドをセットで管理しておくといっ たことが可能。 ◼ Polyaxon ◼ 機械学習モデルの構築、学習、結果監視ができるオープンソースの フレームワーク。Kubernetesベースで、モデルのバージョン管理 や、クラスタ構成を活かした分散学習、ハイパーパラメーター探索 もサポートしている。 開発をサポートするツール/サービス(1/2)
48.
Copyright © TIS
Inc. All rights reserved. 48 ◼ FloydHub ◼ 機械学習におけるHerokuを掲げるサービス。GPUによる計算機能 を提供するほか、β版として機械学習モデルのデプロイ機能を提供 している。 ◼ Algorithmia ◼ 元々は開発した機械学習アルゴリズムを公開できるサービスだった が、そのインフラをプライベートでも使えるよう公開した。 ◼ Google Cloud ML ◼ 学習の実行、作成したモデルの管理機能を提供するサービス。 ◼ Amazon Sage Maker ◼ 同様に、学習の実行、作成したモデルの管理機能を提供するサービ ス。 開発をサポートするツール/サービス(2/2)
49.
Copyright © TIS
Inc. All rights reserved. 49 Appendix3: 各モジュールの基本的なAPI設計 プロジェクトテンプレートを開発中
50.
Copyright © TIS
Inc. All rights reserved. 50 ◼ Dataset ◼ constructor: 接続先のファイルをStorageから取得する ◼ load: 学習データ(データ/ラベル)を取得する ◼ batch_iter: 学習データを指定されたバッチサイズごとに取得するジェネレーター ◼ describe: 基本統計量を出力する(表形式のデータなら、pandasに入れると楽) ◼ Transformer ◼ scikit-learnのBaseEstimator/TransformerMixinを継承して作成することを推奨 (save/loadが楽になるほか、Pipelineで処理できるようになる) ◼ fit: パラメーターの調整を行う ◼ transform: 変換を実施する ◼ inverse_transform: 逆変換を行う 各モジュールの基本的なAPI設計(1/3)
51.
Copyright © TIS
Inc. All rights reserved. 51 ◼ Trainer ◼ constructor: 学習させるモデル、学習に使用するパラメーターを受け取る・宣言す る(メンバ変数として必要なもの)。 ◼ calc_loss: 最適化の対象となる誤差の計算プロセスを定義する ◼ set_updater(compile): calc_lossの最適化プロセスを定義する(lossが複雑でない場 合、calc_lossとまとめる場合も多い) ◼ train: 学習に使用するDatasetを受け取り、batch_iterから取得したデータを Transformerで前処理しcalc_lossの値をupdaterで更新する ◼ (report): 学習の進捗を記録するが、実務上はTensorBoardに書き込むことが多い。 保存先はtrainメソッド実行時に指定する。 ◼ Model ◼ constructor: modelの構築を行う ◼ (forward): modelの伝搬プロセスを定義する(KerasのSequentialのように、定義= 伝搬になる場合も多いため、明示的にメソッドを設けるかは場合による) ◼ predict: modelによる予測を行う 各モジュールの基本的なAPI設計(2/3)
52.
Copyright © TIS
Inc. All rights reserved. 52 ◼ ModelAPI ◼ constructor: Storageから、必要な静的ファイルのパスを取得し内容を変数内(メモ リ)に展開する ◼ predict: 配列などの一般的な変数からモデルによる予測を行う。 ◼ Experiment ◼ constructor: Trainerインスタンスを生成する。 ◼ run: Trainer.trainを実行する。 ◼ Storage ◼ constructor: local/globalの指定を行う(global=クラウドストレージに接続) ◼ experiment_path: overwriteするか否かとExperimentの型を受け取り、実験結果 の保存先を返す ◼ stage: Experimentの型を受け取り、実験で作成されたモデルファイルをステージ ングフォルダにコピーする ◼ deploy: stageされたファイルを、新しいバージョンのモデルとしてデプロイする。 バージョンが指定され、force=Trueの場合、上書きを行う(force=Falseの場合既存 のバージョンがあったら例外を投げる)。 ◼ path: クラスの型とバージョンを引数に、各種ファイルの保存先を返す 各モジュールの基本的なAPI設計(3/3)
Download





































































![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)














![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)







![[RIT]MLmodeling service](https://cdn.slidesharecdn.com/ss_thumbnails/ritmlmodelingservice-210315090130-thumbnail.jpg?width=640&height=640&fit=bounds)




















