Downloaded 67 times





![| 6
Transformerって何??
2017年に発表されたモデル。RNNでもCNNでもないモデルで、圧倒的な成果
を上げて話題になった。
図表は[1]から引用
英独・英仏翻訳の結果
トランスフォーマーモデル](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-6-320.jpg)
![| 7
モデルの中身はどうなってるの?
Transformerは4つの要素から成り立つ。Multi-Head Attentionが技術のコア。
Positional Embeddingにも複数のやり方があった
り[16]、Skip ConnectionやFFNも重要だったりと
いう話[15]もあるが今回は割愛する
• Feed Forward (Networks)
• Add & (Layer) Norm
• Multi-Head (Self-)Attention
• Positional Encoding ↑コア技術
図は[1]から引用
この構造をTransformer Encoderと
呼んだりする](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-7-320.jpg)
![| 8
何をしてるの?
各単語(トークン)がどこと相関が強いか計算しながら伝播する。相関の強さ
を可視化することもできる。
“making”をQueryとした場合のAttentionを計算した図。
同じ単語にかかる異なる色は異な
るHeadのAttentionであることを示
す(※後述)
図は[1]から引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-8-320.jpg)
![| 9
Multi-Head Attentionを構成するScaled Dot-Product Attentionとは?
Scaled Dot-Product Attentionは入力を別々に埋め込んだものの内積を使った
Attention。Q,K,Vの埋め込み元が同じだと”Self-Attention”と呼ばれる
Q KT
Heat Map
Q = 𝑥𝑥𝑥𝑥𝑄𝑄, 𝐾𝐾 = 𝑥𝑥𝑥𝑥𝐾𝐾, V = 𝑥𝑥𝑥𝑥𝑉𝑉
1. x (入力文の分散表現 or 隠れ層表現) を得る
Scaled Dot-Product Attention(1ヘッドSelf Attention)
の計算方法
2. 入力xの埋め込み表現を取得
3. QKのヒートマップとVをかける
※1 Maskはdecoderで使う。今回は
Encoderのみ考えるので割愛
1
𝑑𝑑𝑘𝑘
※1
計算のイメージ図
図は[1]から引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-9-320.jpg)
![| 10
Multi-Head Attentionとは?
QKVをさらに別々に埋め込むと、複数のヘッドに拡張可能。多様な表現を
獲得できる
Q1 K1
T
Q2 K2
T
V1
V2
・・・
Q WQ
1 Q1
K WK
1 K1
V WV
1 V1
=
=
=
Q WQ
2 Q2
K WK
2 K2
V WV
2 V2
=
=
=
Head 1 Head 2
・・・
結合
Head 1
Head 2
[1]から引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-10-320.jpg)
![| 11
Transformerの進撃!
TransformerをベースとしたモデルはNLP業界を席巻!事実上の標準モデル
(de facto standard)に!
画像は[2], https://insiderpaper.com/ai-text-generator-gpt-3/ より引用
TransformerをベースにしたNLPの有名モデルBERT, GPT-3](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-11-320.jpg)
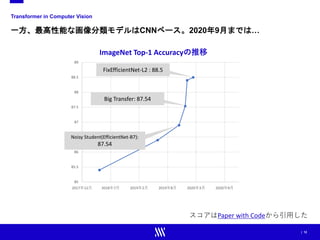
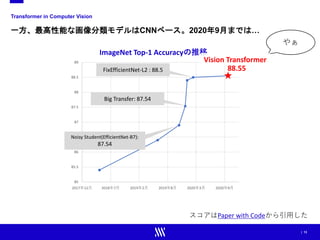
![| 14
Vision Transformer(ViT)の衝撃
Vision Transformer(ViT)は、画像分類タスクで初めてTransformerベースのモ
デルがCNNベースのモデルを凌駕した
画像分類タスクにおける比較
表は[3]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-14-320.jpg)
![| 15
Vision Transformerとは?
画像を16x16サイズのパッチに分割し、Transformer Encoderに入力するモデル。
各パッチをNLPのtoken(単語の
ようなもの)として扱う 画像は[3]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-15-320.jpg)
![| 16
Vision Transformerは何を示したのか?
今までTransformer x Computer Visionの研究はあったが、精度でCNNを超え
られなかった。それはSelf-Attentionの帰納バイアス(モデルが持つデータの
仮定)が小さいことに由来しているとし、データ数の力でそれを突破した[3]。
𝑥𝑥𝑇𝑇
𝑥𝑥𝑇𝑇+1
𝑥𝑥𝑇𝑇−1
CNN RNN Self Attention
局所的に情報が集約され
ているという強い帰納バ
イアスが存在。
1つ前の時刻と強い相関
があるという強い帰納バ
イアスが存在
強い相関
弱い相関
全特徴量同士で相関を
とっているだけなので比
較的帰納バイアスが弱い](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-16-320.jpg)
![| 17
帰納バイアスとデータ量
データが少ないと強い帰納バイアスをもつモデル(CNN)が強い。しかし、デー
タが大量にあると帰納バイアスが小さいモデル(Transformer)の方が強い。
データが中規模しかない領域では、
BiT(CNNベースのモデル、強い帰納
バイアスをもつ)の方が強い
130万画像 3億画像
データが大規模にある領域では、ViT
(弱い帰納バイアスをもつ)の方が
強い
図は[3]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-17-320.jpg)
![| 18
計算効率
CNNと比較して収束も早い
図は[3]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-18-320.jpg)
![| 19
進撃のTransformer
ViT以降様々なCV系タスクにTransformerベースのモデルを使った研究が急増。
一部ではCNNベースのモデルを超える性能を発揮している。
点群 Semantic Segmentation
&物体検知
Point Transformer[4] Swin[5]
深度推定
DPT[6]
図は[4]より引用
図は[5]より引用 図は[6]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-19-320.jpg)
![| 20
CV以外のデータと組み合わせても活躍
多種データを扱うモデルでもTransformerが大活躍
Vision, Text Vision & Languages など複数の
タスクを同時に学習・推論できる
Transformer ベースのモデル Unified
Transformer(UniT)を提案。タスク毎の微
調整は不要で、7つのタスクを同じパラ
メータで実施できる。
UniT[7]
CVタスク+言語タスク
Perceiver[13]
10万以上の特徴量数をもつ高次元入力に対応
でき、動画+音声、画像、点群など多くの
データ形式に対応できるTransformerモデル。
潜在空間からQを取ってくることで、計算量
を削減する。画像、点群で高い性能を発揮し
ただけでなく動画+音声ではSotA性能を獲得
動画・音声・画像・点群
図は[7]より引用
図は[13]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-20-320.jpg)



![| 24
必要データ量
帰納バイアスが小さいため、モデルを高性能にするためには莫大なデータ量を
必要とする
130万画像 3億画像。そして非公開
130万画像程度では、CNNの方が高性能になる
論文中では、130万画像を含むImageNetを”medium size”と言っている…
図は[3]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-24-320.jpg)
![| 25
モデルサイズ
モデルが大きくるほど精度が良い傾向になっており、最大モデルは気軽に使え
る大きさではない。
GPT-2(1542M)の4割程度
EfficientNet-B7(66M)の9.6倍程度のパラメーター数
表は[3]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-25-320.jpg)
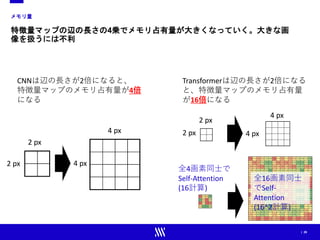


![| 29
CNNモデルによる蒸留
CNNの知識を使うことで、精度を向上できる
RegNet(CNN)
教師モデル
Transformer
生徒モデル
CNNを使った知識蒸留
CNNモデルから知識蒸留を行えば
ImageNetの学習でも高精度になる
DeiT[10]
知識蒸留
(Knowledge Distillation)](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-29-320.jpg)
![| 30
CNNと併用させる
CNNは帰納バイアスのおかげで局所情報に強い。その力を借りるとImageNet
でもViTを超えられる
最初の埋め込みに畳み込みを使う
CeiT[8]
CvT[9]
Transformer EncoderにCNNを使う
CeiT[8]
ViT
CNN
CNN
ViTはパッチ化したものを埋め込み表現と
してTransformerに入れるが、CNNによる畳
み込みを使って抽象化した埋め込み表現
を使う
CNNをTransformerの内部に入れ込むことで、
局所特徴量取得に強くさせる
図は[8]より引用
図は[8]より引用
図は[9]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-30-320.jpg)
![| 31
CNNの発展で得られた知見を使う
階層構造を持たせることで、計算量削減と複数スケールの対応を行う
解像度を徐々に下げていくことで…
1. 大きさの違いに頑健になる
2. 高解像度画像の情報を使いながらメモ
リを削減できる
解像度が固定かつ小さい
CNNと同じように局所
Attentionで徐々に視野
を広げていく[5]
解像度を段階的に下げる
ことで、初期層は高解像
度画像を扱える[11]
16x16サイズをパッチ化
し、その解像度のまま
伝播させる
図は[5]より引用
図は[5]より引用
図は[11]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-31-320.jpg)
![| 32
Transformerにおける改善
もちろんCNNと関係なくTransformer単体でも改善が進んでいる
Attentionを取るグループを層毎に変える[5]
全域Attentionを使うViTと異なり、赤枠内で局所
Attentionをとるが、層毎にAttentionをとるグループを
変えながら伝播させる
画像埋め込みの改善[12]
ViTにおける画像のtoken化(埋め込
み)が単純すぎると考え、重複を
許して周りのtokenを混ぜ合わせ
て再token化するT2Tモジュールを
提案
追加の学習パラメーターで深層化の恩恵を
うけやすくする[14]
異なるHeadのAttentionを混ぜる学習パラメータの導
入により、Attentionの多様性を向上させる。似た
Attentionの生成を防いで深層化で精度を向上させる
図は[5]より引用
図は[12]より引用
式は[14]より引用](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-32-320.jpg)
![| 33
しかし…
未だ必要とされる計算資源は大きい(※)。実応用上の観点ではCNNはまだ
駆逐されなさそう
Models are trained on 8 GPUs with 2 images per GPU
for 160K iterations.
Swin Transformer[5]
All models are trained for 300 epochs from scratch on 8 V100 GPUs.
Pyramid Vision Transformer(PVT)[11]
We used a small batch size of 64 across 32 TPUs to make sure all models fit
comfortably … Perceiver[13]
※ EfficientNet-B7のパラメータ数が66Mに対し、Swin, PVTの最大モデルのサイズは
197M,61.4M。モデルサイズもそこそこに大きいが、大きな画像を入れたときのメモリ占
有量が大きいため、これだけの計算資源を使っていると予想](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-33-320.jpg)


![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのComputer Visionにおける躍進と 肥大化する計算資源 〜](https://image.slidesharecdn.com/ss1-01-210607043349/85/SSII2021-SS1-Transformer-x-Computer-Vision-Transformer-Computer-Vision-36-320.jpg)

SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのComputer Visionにおける躍進と 肥大化する計算資源 〜 6/10 (木) 14:00~14:30 講師:藤井 亮宏 氏(株式会社エクサウィザーズ) 概要: Vision Transformer (ViT) が2020年末に発表され、ImageNetの認識精度においてConvolutional Neural Networks (CNN) ベースのモデルをTransformerのみを使ったモデルが凌駕した。それによってTransformerがAlexNet以降画像系タスクを支配していたCNNに取って換わる可能性が高くなったが、ViTでは大量のデータと大規模な計算資源を必要とすることが障壁となっている。本チュートリアル」では、Computer vision (CV) 系のタスクでTransformerの用途とその成果、実活用の視点からCNNとTransformerの比較、今後Transformer x CVの展望、を議論する。 講師による公開場所: https://www.slideshare.net/exwzds/210610-ssiii2021-computer-vision-x-trasnformer




![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)
![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)












![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-01] 設備や環境の高品質計測点群取得と自動モデル化技術](https://cdn.slidesharecdn.com/ss_thumbnails/os3-02-210605062048-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS2-01] イメージング最前線](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os2-1-220607020403-b550c379-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS3] 機械学習のアノテーションにおける データ収集 〜 精度向上のための仕組み・倫理や社会性バイアス 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts3-01-210607043121-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-03] スケーラブルなロボット学習システムに向けて](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-03-220607020929-1e2b15e8-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-01] 深層学習のための効率的なデータ収集と活用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-01-220607020740-e80781dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3] 広域環境の3D計測と認識 ~ 人が活動する場のセンシングとモデル化 ~(オーガナイザーによる冒頭の導入)](https://cdn.slidesharecdn.com/ss_thumbnails/os3-01-210605061816-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS1-01] AI時代のチームビルディング](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os1-01-220607015404-49188612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-03] 画像と点群を用いた、森林という広域空間のゾーニングと施業管理](https://cdn.slidesharecdn.com/ss_thumbnails/os3-04-210605062524-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-02] BIM/CIMにおいて安価に点群を取得する目的とその利活用](https://cdn.slidesharecdn.com/ss_thumbnails/os3-03-210605062350-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS2] Deepfake Generation and Detection – An Overview (ディープフェイクの生成と検出)](https://cdn.slidesharecdn.com/ss_thumbnails/ss2-01-210607043612-thumbnail.jpg?width=640&height=640&fit=bounds)