Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
KS
Uploaded by
Kosuke Shinoda
PPTX, PDF
3,712 views
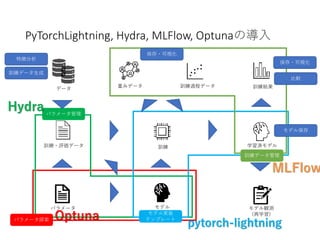
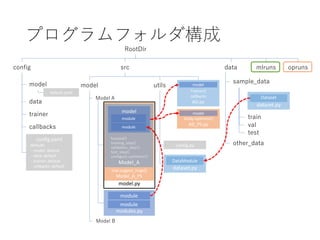
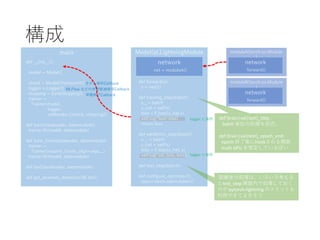
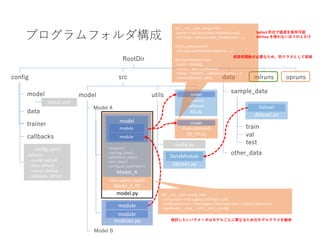
PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築
python PyTorchLightning Hydrea MLFlow Optuna MLOps
Science
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 19
2
/ 19
3
/ 19
4
/ 19
Most read
5
/ 19
6
/ 19
7
/ 19
8
/ 19
Most read
9
/ 19
10
/ 19
11
/ 19
12
/ 19
13
/ 19
14
/ 19
15
/ 19
16
/ 19
17
/ 19
Most read
18
/ 19
19
/ 19
More Related Content
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
PDF
最適輸送入門
by
joisino
PPTX
モデル高速化百選
by
Yusuke Uchida
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
最適輸送入門
by
joisino
モデル高速化百選
by
Yusuke Uchida
GAN(と強化学習との関係)
by
Masahiro Suzuki
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
What's hot
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PDF
研究分野をサーベイする
by
Takayuki Itoh
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PDF
【DL輪読会】Code as Policies: Language Model Programs for Embodied Control
by
Deep Learning JP
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
全力解説!Transformer
by
Arithmer Inc.
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PPTX
TabNetの論文紹介
by
西岡 賢一郎
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
PPTX
Semi supervised, weakly-supervised, unsupervised, and active learning
by
Yusuke Uchida
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
【DL輪読会】Implicit Behavioral Cloning
by
Deep Learning JP
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
研究分野をサーベイする
by
Takayuki Itoh
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
【DL輪読会】Code as Policies: Language Model Programs for Embodied Control
by
Deep Learning JP
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
全力解説!Transformer
by
Arithmer Inc.
Optimizer入門&最新動向
by
Motokawa Tetsuya
TabNetの論文紹介
by
西岡 賢一郎
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
Semi supervised, weakly-supervised, unsupervised, and active learning
by
Yusuke Uchida
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
【DL輪読会】Implicit Behavioral Cloning
by
Deep Learning JP
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
More from Kosuke Shinoda
PDF
エゴセントリックネットワークを用いた同義語・類義語の判別の検討
by
Kosuke Shinoda
PDF
人狼知能セミナー資料案20170624
by
Kosuke Shinoda
DOCX
社会と人工知能特集「仮想化する社会」
by
Kosuke Shinoda
PDF
「人狼知能」没原稿 社会的知能を目指して
by
Kosuke Shinoda
PDF
大規模ネットワーク分析 篠田
by
Kosuke Shinoda
PDF
人狼知能プログラミング演習資料2015
by
Kosuke Shinoda
エゴセントリックネットワークを用いた同義語・類義語の判別の検討
by
Kosuke Shinoda
人狼知能セミナー資料案20170624
by
Kosuke Shinoda
社会と人工知能特集「仮想化する社会」
by
Kosuke Shinoda
「人狼知能」没原稿 社会的知能を目指して
by
Kosuke Shinoda
大規模ネットワーク分析 篠田
by
Kosuke Shinoda
人狼知能プログラミング演習資料2015
by
Kosuke Shinoda
Download



















![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)













