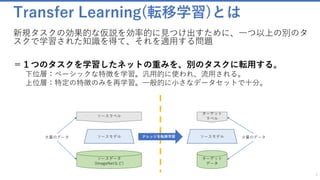
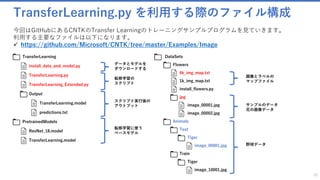
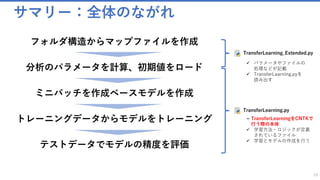
Deep LearningのなかでもTransfer Learning(転移学習)を用いたオリジナル画像認識AIを、アプリケーションに組み込むためのAPI開発と実装方法を解説します。
MicrosoftのMicrosoft Cognitive Toolkit (CNTK)を使い、ソリューションを組み立てましょう。
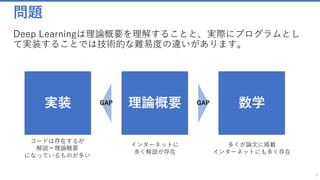
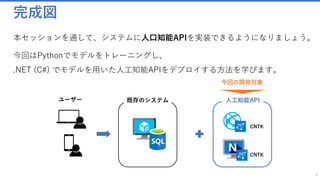
Deep Learningの世界では理論と実装に大きな隔たりがありますが、丁寧に仕組みを追っていけばデータサイエンティストでなくてもAIの技術は使うことが出来ます。本セッションを通して、システムに人口知能APIを実装できるようになりましょう。
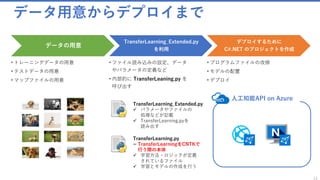
このチュートリアルではPythonでモデルをトレーニングし、C#でWebにそれをデプロイしていきます。












![初期パラメータ
23
ファイルパスの定義
_data_folder os.path.join(base_folder, "..", "DataSets", "Flowers")
_train_map_file os.path.join(_data_folder, "6k_img_map.txt")
_test_map_file os.path.join(_data_folder, "1k_img_map.txt")
_base_model_file os.path.join(base_folder, "..", "PretrainedModels", "ResNet_18.model")
base_folder os.path.dirname(os.path.abspath(__file__))
tl_model_file os.path.join(base_folder, "Output", "TransferLearning.model")
output_file os.path.join(base_folder, "Output", "predOutput.txt")
抽出するモデルの定義に関する設定
_feature_node_name "features"
_last_hidden_node_name "z.x"
_image_height 224
_image_width 224
_num_channels 3
_num_classes 102
ラーニングのパラメータ
max_epochs 20
mb_size 50
lr_per_mb [0.2]*10 + [0.1]
momentum_per_mb 0.9
l2_reg_weight 0.0005
モデルを操作する際の設定
make_mode False
freeze_weights False
features_stream_name 'features'
label_stream_name 'labels'
new_output_node_name "prediction"
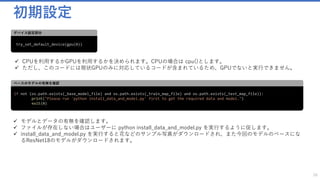
初期パラメータはそれぞれ以下に設定されています。
✓ ファイルパスの定義:データセットやモデルへのパス
✓ モデルを読み込む際の設定:モデルにはパラメータやノードの定義がされています。今回操作する際にどのような処理を
するのか定義しています。
✓ 抽出するモデルの定義に関する設定:インプットデータの次元やクラス数が定義されています。
✓ ラーニングのパラメータ:学習の際の数式に与えるパラメータが定義されています。](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-23-320.jpg)
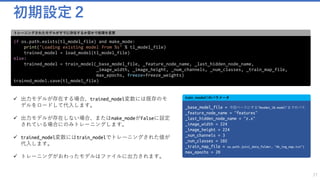
![[参考] 試用する Python のライブラリ
24
ロードするライブラリ
from pprint import pprint
from PIL import Image Pillow は、Python の画像処理ライブラリ
import numpy as np NumPy は Python で多次元配列や行列の計算を高速に行うためのライブラリ。
from cntk.device import try_set_default_device, gpu デバイス関連の情報を扱うGPUやCPUなど
from cntk import load_model, placeholder, Constant モデルをロードするための関数など
from cntk import Trainer, UnitType
from cntk.logging.graph import find_by_name, get_node_outputs モデルファイルから情報を読む
from cntk.io import MinibatchSource, ImageDeserializer, StreamDefs, StreamDef ミニバッチソースを作るために主に使う、イメージをデシリアライズする機能など
import cntk.io.transforms as xforms 行列を操作する
from cntk.layers import Dense 最終密集レイヤの関数
from cntk.learners import momentum_sgd, learning_rate_schedule, momentum_schedule 学習する際のスケジューリングなどの関数
from cntk.ops import input, combine, softmax ソフトマックス計算など
from cntk.ops.functions import CloneMethod ベースモデルを部分的にコピーする際に使う
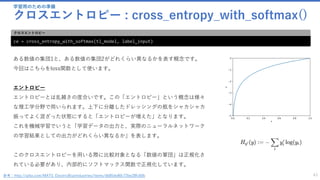
from cntk.losses import cross_entropy_with_softmax クロスエントロピーを正規化(softmax)した形で返す
from cntk.metrics import classification_error クラス判別エラーの関数
from cntk.logging import log_number_of_parameters, ProgressPrinter プログレスプリンターなど、主にログの用途で使う
CNTKの機能はそれぞれ以下を使っています。](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-24-320.jpg)

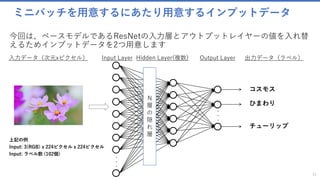
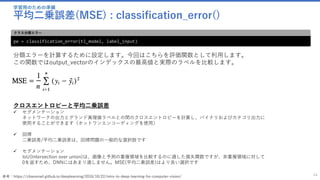
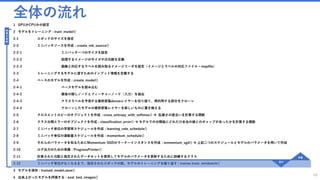
![モデルをトレーニング
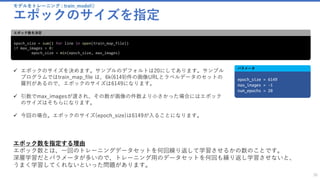
ミニバッチソースを作成 : create_mb_source()
32
minibatch_source = create_mb_source(train_map_file, image_width, image_height, num_channels, num_classes)
image_input = input((num_channels, image_height, image_width))
label_input = input(num_classes)
ミニバッチソースを作成
✓ ミニバッチソースと入力変数を作成します。
✓ このプログラムで行っているのは、確率的勾配降下法(SGD =
Stochastic Gradient Descent) です。この手法では訓練データ
をミニバッチに分割して学習させます。
minibatch_source : ミニバッチのクラスインスタンス
image_input : Input('Input3', [#], [3 x 224 x 224])
label_input : Input('Input4', [#], [102])
各変数の値
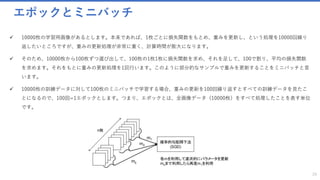
ミニバッチで学習を行う理由
✓ ミニバッチ学習とは、ネットワークのパラメータ学習に対して全学習サンプルを一度に使うのではなく、全学習サンプ
ルから一定数のサンプルを抽出したサブセットを使って誤差計算と重み更新を行う方法です。
✓ ひとつのサンプルごとに重みを更新するオンラインの方法と比較すると高速に処理を行うことができ、バッチと比べて
良い精度を得られることが、ミニバッチの利点です。
✓ ディープラーニングでミニバッチを使用する際には、よくエポックごとにミニバッチの学習サンプルがシャッフルされ、
ランダムに抽出されます。
✓ 勾配降下法では局所解に陥ったら抜け出せませんが、確率的勾配降下法では毎回違う訓練データを使うので局所解から
抜け出せます。またミニバッチ学習では勾配がより安定的になります。(学習が停滞状態に陥ったのを脱出させるため
に、モーメントを使うことができます。)](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-32-320.jpg)
![モデルをトレーニング ミニバッチソースを作成
ミニバッチのイメージリーダを作成
33
def create_mb_source(map_file, image_width, image_height, num_channels, num_classes, randomize=True):
transforms = [xforms.scale(width=image_width, height=image_height, channels=num_channels, interpolations='linear’)]
return MinibatchSource(ImageDeserializer(map_file, StreamDefs(
features = StreamDef(field='image', transforms=transforms),
labels = StreamDef(field='label', shape=num_classes))),
randomize=randomize)
イメージリーダを作成
関数説明
xforms.scale()
✓ データ拡大のため、map_features
に渡すために使用できるオブジェ
クトにスケール変換をします。
✓ 戻り値としてはスケール変換を記
述する辞書のようなオブジェクト
なオブジェクトが返されます。
map_file : イメージのパスとそれぞれのラベルがマップされているファイルへのパス
image_height : 処理の対象になるイメージの高さ。このプログラムのデフォルトでは224
image_width : 処理の対象になるイメージの横の長さ。このプログラムのデフォルトでは224
num_channels : チャネル数。ここではRGBの3色なので3になっている
num_classes : このサンプルではnum_classesには102 が入っています。
randomize : ミニバッチの抽出の仕方の指定、今回はTrue
{
'features': {'defines_mb_size': False, 'is_sparse': False, 'stream_alias': 'image', 'transforms’: [<transformObject>]},
'labels': {'defines_mb_size': False, 'is_sparse': False, 'dim': 102, 'stream_alias': 'label’}
}
各引数の値
StreamDefsの返り値
StreamDef()
ビルトインデシリアライザで使用するストリームの設定をします。
- field : 今回使うImageDeserializerの場合受け入れ可能な名前は”image”または”label”です。
- shape : このストリームの寸法。今回のサンプルデータのケースでは102種類の花の画像があるため102が代入されます
- trasform : デシリアライザによって適用される変換のリスト。現在ImageDeserializerのみが変換をサポートしています
StreamDefs() : StreamDef() をまとめたディクショナリを作成します。
ImageDeserializer() : ファイルから画像と対応するラベルを読み取るイメージリーダを設定します。](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-33-320.jpg)
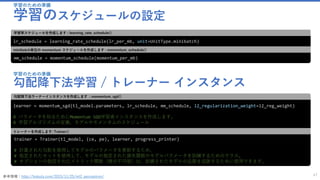
![モデルをトレーニング
ネットワーク入力へのマッピングを定義する
34
input_map = {
image_input: minibatch_source[features_stream_name],
label_input: minibatch_source[label_stream_name]
}
リーダーストリームからネットワーク入力へのマッピングを定義する
リーダーストリームからネットワーク入力へのマッピングを定義します。
minibatch_sourceのクラスインスタンスには "features" と "labels" の値が存在するので、その値を指定し、
create_mb_source()で作成したクラスの中から、以下を抽出します。
✓ “features”という入力の定義がされている部分
✓ labelsというラベルの定義がされている部分
[参考]こちらは、トレーニングの際に、入力値のマップ情報として渡されます。
data = minibatch_source.next_minibatch(min(mb_size, epoch_size-sample_count), input_map=input_map)
参考:input_mapの渡され方
ここまでで下準備は完了です。イメージのファイルを抽出する際の定義などが完了しました。](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-34-320.jpg)

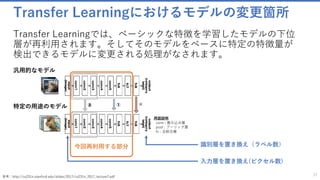
![ベースのモデルを作成
転移学習のネットワークモデルを作成
36
tl_model = create_model(base_model_file, feature_node_name, last_hidden_node_name, num_classes, image_input, freeze)
def create_model(base_model_file, feature_node_name, last_hidden_node_name, num_classes, input_features, freeze=False):
base_model = load_model(base_model_file)
feature_node = find_by_name(base_model, feature_node_name)
last_node = find_by_name(base_model, last_hidden_node_name)
転移学習のネットワークモデルを作成
base_model_file : ベースモデル“ResNet_18.model” へのパス
feature_node_name : "features"
last_hidden_node_name : "z.x"
num_classes : 102 (サンプルでは102種類の花の画像のデータ
セットが含まれるため)
image_input : こちらは、イメージのサイズなどが書かれた定
義が入っています。Input('Input3', [#], [3 x 224 x 224])
Freeze : False (サンプルのデフォルト値)
各引数の値
事前にトレーニングされた分類ネットをロードし、それを元に転移学習のネットワー
クモデルを作成します。今回のベースモデルは”ResNet_18.model” です。
”.model”拡張子のファイルの実態は、ノードの情報、インプット/アウトプットの情報、
各特徴量の重みなど、学習済みのパラメータが定義されているバイナリファイルです。
✓ load_model()を利用し、ResNetのモデルをロードしプログラムから利用できるよ
うにします。
✓ find_by_name() はノードを名前から見つける関数です。ロードしたモデルから、
フィーチャーノード、ラストノードの値を変数に代入しています。
- feature_node : フィーチャーは入力ノードを表します。
- last_node : 最後の隠しノードの名前が設定されています。
参考資料
ResNetに関する参考PDF(英語):http://image-net.org/challenges/talks/ilsvrc2015_deep_residual_learning_kaiminghe.pdf
フィーチャーノードの考え方に関する参考ページ(BrainScript):https://msdn.microsoft.com/ja-jp/magazine/mt791798.aspx](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-36-320.jpg)
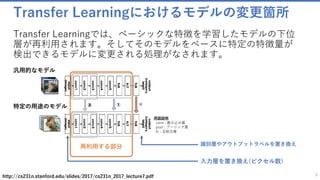
![ベースのモデルを作成
ベースモデルから、再利用する部分を抽出する
38
cloned_layers = combine([last_node.owner]).clone(
CloneMethod.freeze if freeze else CloneMethod.clone,
{feature_node: placeholder(name='features')})
ベースモデルから、再利用する部分を抽出する
combine()
✓ ノードが記述されている関数インスタンスを作成します。
✓ ccombine([last_node.owner]) を実行すると Input(‘features’, [#, ], [3 x 224 x 224]) -> Output(‘z.x’, [#, ], [512 x 1 x 1]) の値が返っ
てきますが、それが今回の複製対象となります。
clone()
✓ 関数をクローンし、パラメータを新しい値で置き換え初期化します。しかしこの段階ではまだパラメータは入れ替えません。
✓ 今回のサンプルにおける、インプットの値(feature)は [3x224x224] ですが、このインプットは変わるかもしれません。
✓ そのためこの段階ではクローン方法とインプットの値のハコを定義します。
クローン方法
✓ CNTKでは以下の方法で複製できます。
clone : 新しい学習可能パラメータは、複製される関数の対応するパラメータの現在の値で作成および初期化されます
freeze : パラメータは複製され、イミュータブルになります。新しいクローン内の定数(例えば、固定された特徴抽出器として使用するため)
share : パラメータは、クローンされるファンクションと新しいクローンとの間で共有されます。
インプットの値のハコを定義:placeholder()
✓ プレースホルダーはデータが格納される予定地です。インプットの値はTrainingをするときにまとめて実行関数に渡されますが、その時
にインプットの値をこのモデルに反映できるように、外からアクセス(代入)できる’feature’というハコを用意しておきます
last_node.owner : Output('z.x.x.r', [#, ], [512 x 7 x 7]) -> Output('z.x', [#, ], [512 x 1 x 1])](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-38-320.jpg)
![ベースのモデルを作成
最終密集レイヤーを新しいものに置き換える
39
feat_norm = input_features - Constant(114)
cloned_out = cloned_layers(feat_norm)
z = Dense(num_classes, activation=None, name=new_output_node_name) (cloned_out)
return z
一定の重みで目的のレイヤーを複製する
cloned_layers(feat_norm)
✓ ノードが記述されている関数インスタンスを作成します。
✓ cfeat_norm には Composite(Minus): Input(‘Input3’, [#], [3 x 224 x 224]) -> Output(‘Minus914_Output_0’, [#], [3 x 224 x 224]) の
値が入っています。
✓ この処理で、先ほど作成したcloned_layerから “Input3”のフィーチャーノード(インプット)を取り除く処理をしています。この”Input3”
は最後に処理を走らせる段階で新しいものが定義され、先ほど定義した “features”のプレースホルダーに挿入されます。
Dense()
✓ Denseはニューラルネットワークの全結合層を表す機能です。
✓ ここでは、クラスラベルを予測する最終密集(dense)レイヤーを切り捨て、新しいnum_classesサイズのDenseを接続する処理をしていま
す。
複製箇所
クラスに合致するように
置き換え
プレースホルダーを設置
後から挿入](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-39-320.jpg)


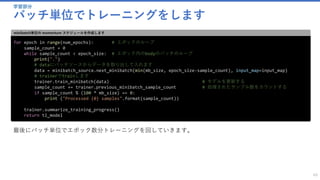



![TransferLearning.py をもっと便利に使う
初期パラメータを確認します
54
base_folder = os.path.dirname(os.path.abspath(__file__))
base_model_file = os.path.join(base_folder, "..", "PretrainedModels", "ResNet_18.model")
feature_node_name = "features"
last_hidden_node_name = "z.x"
image_height = 224
image_width = 224
num_channels = 3
初期パラメータ
初期値は基本的に変わりません。
# define data location and characteristics
train_image_folder = os.path.join(base_folder, "..", "DataSets", "Animals", "Train")
test_image_folder = os.path.join(base_folder, "..", "DataSets", "Animals", "Test")
file_endings = ['.jpg', '.JPG', '.jpeg', '.JPEG', '.png', '.PNG']
ファイルパスの変更
これらの値を変えましょう。テストデータとトレーニングデータが入っているフォルダーのパスを記載します。](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-53-320.jpg)
![TransferLearning.py をもっと便利に使う
マップファイルを作成します
55
def create_map_file_from_folder(root_folder, class_mapping, include_unknown=False):
map_file_name = os.path.join(root_folder, "map.txt")
lines = []
for class_id in range(0, len(class_mapping)):
folder = os.path.join(root_folder, class_mapping[class_id])
if os.path.exists(folder):
for entry in os.listdir(folder):
filename = os.path.join(folder, entry)
if os.path.isfile(filename) and os.path.splitext(filename)[1] in file_endings:
lines.append("{0}¥t{1}¥n".format(filename, class_id))
if include_unknown:
for entry in os.listdir(root_folder):
filename = os.path.join(root_folder, entry)
if os.path.isfile(filename) and os.path.splitext(filename)[1] in file_endings:
lines.append("{0}¥t-1¥n".format(filename))
lines.sort()
with open(map_file_name , 'w') as map_file:
for line in lines:
map_file.write(line)
return map_file_name
マップファイルをフォルダ名・ファイルパスから作成する。
マップファイルをフォルダ名・ファイルパスから作成します](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-54-320.jpg)
![TransferLearning.py をもっと便利に使う
クラスを作成します
57
def create_class_mapping_from_folder(root_folder):
classes = []
for _, directories, _ in os.walk(root_folder):
for directory in directories:
classes.append(directory)
return np.asarray(classes)
フォルダ名からクラスを作る
フォルダ名からクラスを作ります。
Flower
image_00001.jpg
Test
Cosmos
image_10001.jpg
Sunflower
image_20001.jpg
Turip
3クラス
[“Cosmos”,”Sunflower”,”Turip”]](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-55-320.jpg)
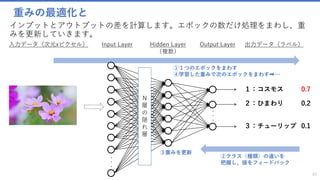
![TransferLearning.py をもっと便利に使う
結果データ(処理のログ)を出力します
58
def format_output_line(img_name, true_class, probs, class_mapping, top_n=3):
class_probs = np.column_stack((probs, class_mapping)).tolist()
class_probs.sort(key=lambda x: float(x[0]), reverse=True)
top_n = min(top_n, len(class_mapping)) if top_n > 0 else len(class_mapping)
global total_correct
true_class_name = class_mapping[true_class] if true_class >= 0 else 'unknown'
line = '[{"class": "%s", "predictions": {' % true_class_name
for i in range(0, top_n):
line = '%s"%s":%.3f, ' % (line, class_probs[i][1], float(class_probs[i][0]))
if (true_class_name == class_probs[0][1]):
total_correct = total_correct + 1
line = '%s}, "image": "%s"}]¥n' % (line[:-2], img_name.replace('¥¥', '/'))
return line
それぞれのトレーニング結果などのデータを出力するための関数
✓それぞれのトレーニング結果などのデータを出力するための関数です。](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-56-320.jpg)
![TransferLearning.py をもっと便利に使う
トレーニング (抜粋)
59
def train_and_eval(_base_model_file, _train_image_folder, _test_image_folder, _results_file, _new_model_file, tes
ting = False):
class_mapping = create_class_mapping_from_folder(_train_image_folder)
train_map_file = create_map_file_from_folder(_train_image_folder, class_mapping)
test_map_file = create_map_file_from_folder(_test_image_folder, class_mapping, include_unknown=True)
# train
trained_model = train_model(_base_model_file, feature_node_name, last_hidden_node_name,
image_width, image_height, num_channels,
len(class_mapping), train_map_file, num_epochs=30, freeze=True)
# evaluate test images
with open(_results_file, 'w') as output_file:
with open(test_map_file, "r") as input_file:
for line in input_file:
tokens = line.rstrip().split('¥t')
img_file = tokens[0]
true_label = int(tokens[1])
probs = eval_single_image(trained_model, img_file, image_width, image_height)
formatted_line = format_output_line(img_file, true_label, probs, class_mapping)
output_file.write(formatted_line)
実行部分
✓クラスの配列を取得し、トレーニングとテストそれぞれのマップファイルを作ります。
✓上記をもとにTransferLearning.pyの train_model() 関数を利用し、モデルをトレーニングします。](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-57-320.jpg)


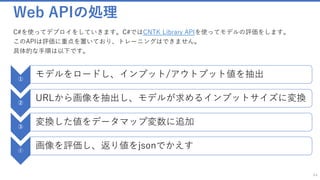
![TransferLearning.model をデプロイ
モデルをロードし、インプット/アウトプット値を抽出
65
DeviceDescriptor device = DeviceDescriptor.CPUDevice;
Function modelFunc = Function.Load(modelFilePath, device);
// Get input variable. The model has only one single input.
// The same way described above for output variable can be used here to get input variable by name.
Variable inputVar = modelFunc.Arguments.Single();
// Get shape data for the input variable
NDShape inputShape = inputVar.Shape;
int imageWidth = inputShape[0];
int imageHeight = inputShape[1];
int imageChannels = inputShape[2];
int imageSize = inputShape.TotalSize;
// The model has only one output.
// If the model have more than one output, use the following way to get output variable by name.
// Variable outputVar = modelFunc.Outputs.Where(variable => string.Equals(variable.Name, outputName)).Single();
Variable outputVar = modelFunc.Output;
var inputDataMap = new Dictionary<Variable, Value>();
var outputDataMap = new Dictionary<Variable, Value>();
実行部分
✓デバイスをGPUかCPUか指定します。
✓Function.load()でモデルを抽出し、配列からモデルが持つインプット値、アウトプット値を取り出します。](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-61-320.jpg)
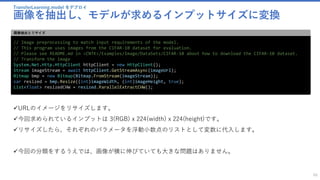
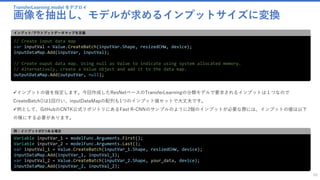
![TransferLearning.model をデプロイ
画像を抽出し、モデルが求めるインプットサイズに変換
69
// Start evaluation on the device
modelFunc.Evaluate(inputDataMap, outputDataMap, device);
// Get evaluate result as dense output
var outputVal = outputDataMap[outputVar];
var outputData = outputVal.GetDenseData<float>(outputVar);
string json = JsonConvert.SerializeObject(outputData);
return json;
評価
✓最後にEvaluate()で関数を評価し、json変換をして値を返します。
デプロイ
このプログラムをデプロイし、
http://localhost:3469/api/values
{“url”:”http://hogehoge.com/hoge.jpg”}
のjsonをPOSTで渡すと配列がレスポンスとして返ってきます。](https://image.slidesharecdn.com/transferlearningapiazure-170705100201/85/Transfer-Learning-API-Azure-65-320.jpg)























![[BA11] Office 365/Dynamics 365 連携だけじゃない! 業務に使うマルチデバイスアプリ作成に向けた PowerApps/Flow...](https://cdn.slidesharecdn.com/ss_thumbnails/ba11-170605021451-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BA06] 50 分で総まとめ! Office 365 開発プラットフォーム最新機能のおさらい](https://cdn.slidesharecdn.com/ss_thumbnails/ba06-170605021434-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[Developers Summit 2018] Microsoft AIプラットフォームによるインテリジェント アプリケーションの構築](https://cdn.slidesharecdn.com/ss_thumbnails/20180215developerssummitmicrosoftaiplatform-180218215607-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)








