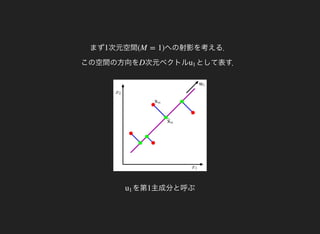
第 主成分を(M +1) とする.uM+1
と,= 1u
T
M+1
uM+1 は既に求めたベクトルuM+1 と直交するという, …,u1 uM つの制約条件の下で,
射影後の分散
2
の最大化を考える.
ラグランジュ乗数を導入すれば,
Su
T
M+1
uM+1
を制約式なしで最大化する問題とみなすことができる.
S + (1 − ) +u
T
M+1
uM+1 λM+1 u
T
M+1
uM+1 ∑M
i=1
ηi u
T
M+1
ui
17.
に関して微分してuM+1 とおけば,0
左から
2S −2 + = 0uM+1 λM+1 uM+1 ∑M
i=1
ηi ui
をかければ,u
T
j
が得られる
したがって,以下の式を得る.
= 0 (j = 1, 2, …, M)ηj
さらに,左から
S =uM+1 λM+1 uM+1
をかければu
T
M+1
が得られる.
以上より,分散を最大にするにはまだ選択されていない固有値の中で
最大のものに属する固有ベクトル
S =u
T
M+1
uM+1 λM+1
であることがわかる.uM+1
18.
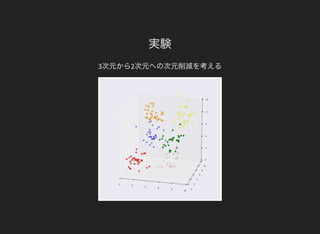
主成分分析
1. データ集合から共分散行列 を求める
2.の固有値問題を解く
3. 大きい順に 個の固有値に対応する固有ベクトルから主成分を求める
4. 各データに対して 個の主成分で基底変換した座標をもとめる
S
Su = λu
M
M
特徴空間における サンプル共分散行列はM ×M
で与えられ,通常の主成分分析と同様に固有方程式は
C = ϕ( )ϕ(
1
N
∑N
n=1
xn xn )
T
に対して,i = 1, …, M
で与えられる.
C =vi λi vi
36.
とC = ϕ()ϕ(
1
N
∑N
n=1
xn xn )
T
から
固有ベクトル
C =vi λi vi
は以下の式を満たす.vi
したがって,
ϕ( ){ϕ( } =
1
N
∑N
n=1
xn xn )
T
vi λi vi
のようにかける.
ただし,
= ϕ( )vi ∑N
n=1
ain xn
= ϕ(ain
1
Nλi
xn )
T
vi
37.
とϕ( ){ϕ( }=
1
N
∑N
n=1
xn xn )
T
vi λi vi より
以下の式が得られる.
= ϕ( )vi ∑N
n=1
ain xn
両辺に
ϕ( )ϕ(x ϕ( ) = ϕ( )
1
N
∑N
n=1
xn )
T
n ∑N
m=1
aim xm λi ∑N
n=1
ain xn
をかければ,ϕ(xl )
T
を用いてk( , ) = ϕ( ϕ( )xn xm xn )
T
xm
とかける.
k( , ) k( , ) = k( , )
1
N
∑N
n=1
xl xn ∑N
m=1
aim xn xm λi ∑N
n=1
ain xl xn
38.
は
行列とベクトルを用いれば以下のようにかける.
k( , )k( , ) = k( , )
1
N
∑N
n=1
xl xn ∑N
m=1
aim xn xm λi ∑N
n=1
ain xl xn
ただし,
= N KK
2
ai λi ai
はai 次元ベクトルでその要素はN に対してn = 1, …, N ain
はK 行i 列に要素j をもつ行列= k( , )Kij xi xj
をグラム行列と呼ぶ.K
39.
に対する解を,次の方程式を解くことにより得られる.ai
また,係数
K = Naiλi ai
に対する規格化条件は以下で得られる.ai
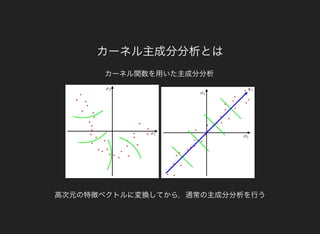
固有値問題を解いたとして,主成分への射影をカーネル関数で表すことができる.
1 = = ϕ( ϕ( ) = K = Nv
T
i
vi ∑N
n=1
∑N
m=1
ain aim xn )
T
xm a
T
i
ai λi a
T
i
ai
で与えられ,カーネル関数だけを通して表されていることがわかる.
(x) = ϕ(x = ϕ(x ϕ(x) = k(x, )yi )
T
vi ∑N
n=1
ain )
T
∑N
n=1
ain xn
40.
K̃
nm = (( )ϕ̃
xn )
T
ϕ̃
xm
= ϕ( ϕ( ) − ϕ( ϕ( ) − ϕ( ϕ( ) + ϕ( ϕ( )xn )
T
xm
1
N ∑
l=1
N
xn )
T
xl
1
N ∑
l=1
N
xl )
T
xm
1
N
2 ∑
j=1
N
∑
l=1
N
xj )
T
xl
= k( , ) − k( , ) − k( , ) + k( , )xn xm
1
N ∑
l=1
N
xl xm
1
N ∑
l=1
N
xn xl
1
N
2 ∑
j=1
N
∑
l=1
N
xj xl
射影されたデータ集合 の平均がϕ( )xn でない場合も考える
射影されたデータ点の中心化された点を
0
で表すと,( )ϕ̃
xn
で与えられ,グラム行列の対応する要素は,
( ) = ϕ( ) − ϕ( )ϕ̃
xn xn
1
N
∑N
l=1
xl
41.
これは行列表記で次のようにかける.
ただし,
= K −K − K + KK̃ 1N 1N 1N 1N
は全ての要素が1N という値をとる1
N
行列である.
したがって,カーネル関数だけを用いて
N × N
を求めることができる.
あとは
K̃
を使って固有値と固有ベクトルを求めれば良い.K̃



























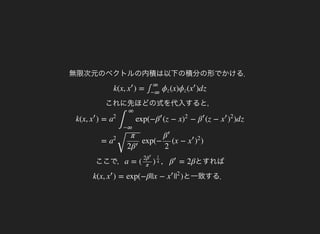






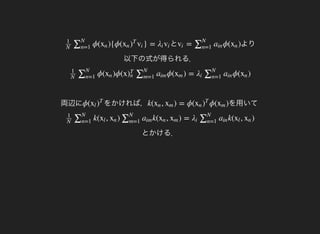







![参考文献
[1] C.M.ビショップ,パターン認識と機械学習下,丸善出版,2006
[2] 赤穂昭太郎,カーネル多変量解析,岩波書店,2008](https://image.slidesharecdn.com/progress4-160910082136/85/slide-46-320.jpg)


![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)













































