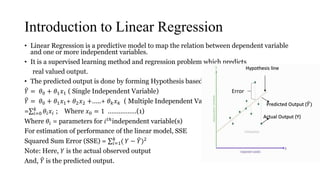
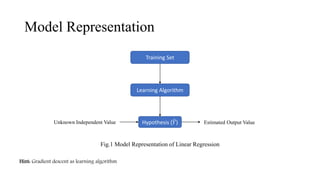
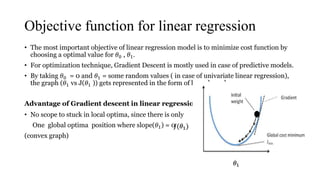
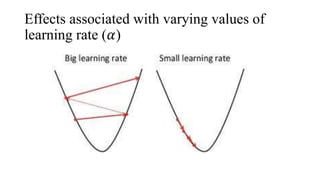
The document provides an overview of linear regression as a predictive model that establishes relationships between dependent and independent variables using cost functions and gradient descent for optimization. It explains concepts such as hypothesis representation, error calculation, maximum likelihood estimation for mean and variance, and the workings of gradient descent, including steps to adjust parameter values. The conclusion emphasizes that linear regression's cost function is convex, ensuring convergence to a global optimum without local optima.