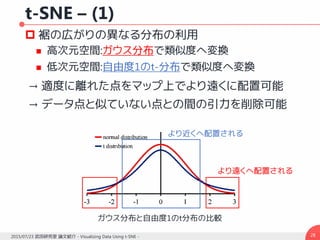
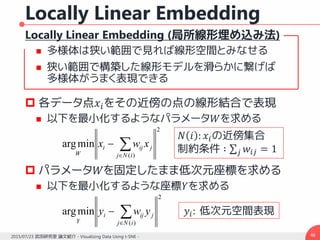
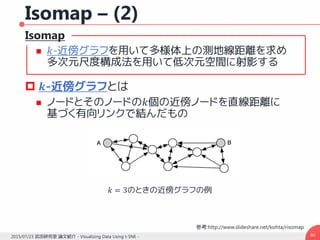
t-SNE – (3)
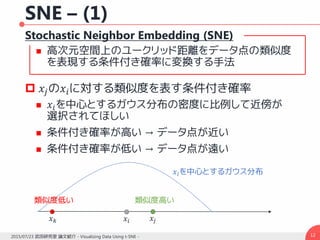
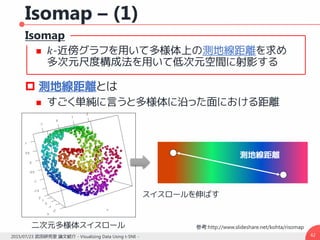
データ点の類似度とマップ点の類似度
この場合の勾配は
302015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
n
pp
p
jiij
ij
2
||
lk
lk
ji
ij
yy
yy
q 12
12
1
1
j
jijiijij
i
yyyyqp
y
C
)13()1)()((4 12
31.
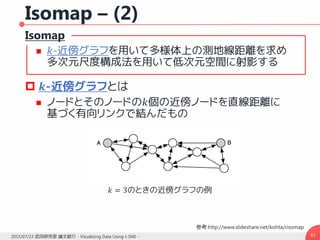
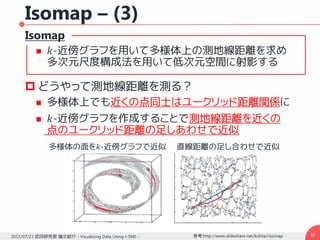
勾配の導出 – (1)
高次元空間上での対称条件付き確率
マップ上での同時確率
KL距離に基づくコスト関数は
計算の簡単化のため2つの補助変数を導入
𝑦𝑖が変化したとき変化するのは𝑑𝑖𝑗, 𝑑𝑗𝑖のみ
312015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
n
pp
p
jiij
ij
2
||
lk
lk
ji
ij
yy
yy
q 12
12
1
1
i
ijijij
j
ij
i j ij
ij
ij
i
qppp
q
p
pQPKLC logloglog)|(
jiij yyd
lk
kldZ 12
)1(
j
ji
ijj
ji
jiiji
yy
d
C
yy
d
C
d
C
y
C
)(2)(
32.
j
jijiijij
i
yyyyqp
y
C 12
)1)()((4
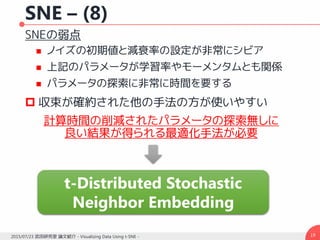
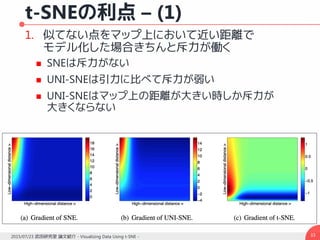
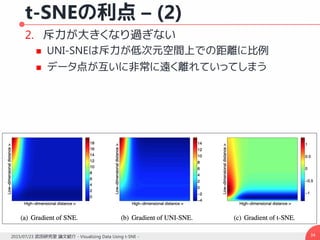
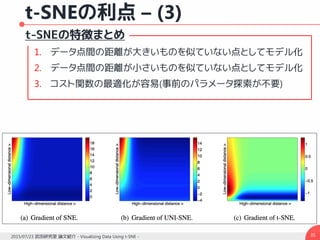
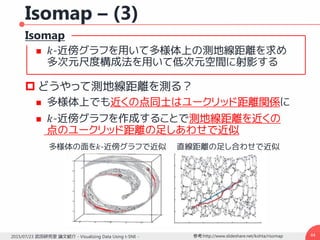
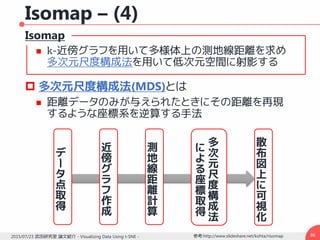
勾配の導出– (2)
コスト関数は
322015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
i
ijijij
j
ij qpppC loglog
12
1212
1222
22
12
)1)((2
)1()1(2)1(2
)0
))1((
(
)1(
2)1(2
1))1((1
)log(log
)(log
)(log
ijijij
lk
klijijijij
lk ij
klij
klij
ij
ij
lk ijij
kl
kl
kl
lk ij
kl
kl
lk ij
kl
kl
i j ij
ij
ij
ij
dqp
pdqdp
d
d
jlikwhen
Z
d
pd
Zq
p
d
Z
Zd
d
Zq
p
d
ZZq
p
d
q
p
d
q
p
d
C




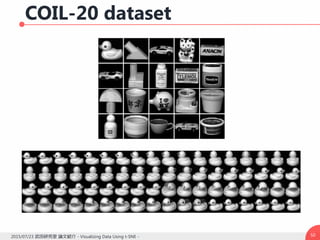
![Introduction
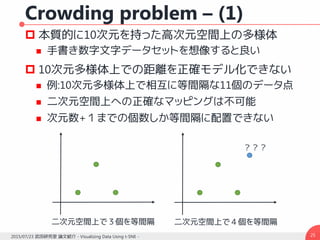
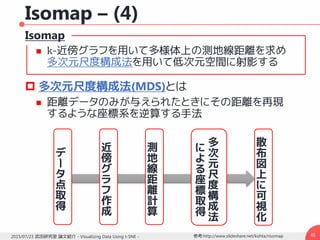
高次元データの可視化は様々な分野で重要な課題
様々な次元数を取り扱う
例:乳がんに関連する細胞核の種類 → 30 種類
例:文書を表現する単語ベクトル → 数千次元
これまで様々な手法が研究されてきた
図像ベースの手法
Chernoff faces [Chernoff, 1973]
Pixel based technique [Keim, 2000]
次元削減手法
Principal Component Analysis [Hotteling, 1993]
Multi Dimensional Scaling [Torgerson, 1952]
42015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-4-320.jpg)
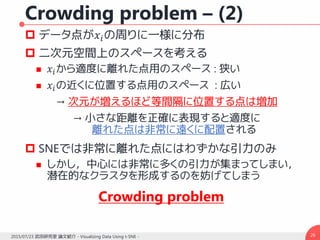
![Introduction
Chernoff Face [Chernoff, 1973]
多次元データを人間の顔で表示する
15種類の顔のパラメータを持つ
52015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
Chernoff faceの例](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-5-320.jpg)
![Introduction
Pixel-based technique [Keim, 2000]
高次元データを色やエッジで表現する(?)
62015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
20年間の日記を可視化した結果](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-6-320.jpg)
















![Crowding problem – (3)
UNI-SNE [Cook et al., 2007]
小さな混同比 𝜌 を持った一様背景分布モデルの導入
すべてのバネに微小な斥力を付加
SNEよりも優れた性能を示すが,最適化が困難
UNI-SNEの最適化
1. 通常のSNEで最適化
2. 混合比をわずかに増加させて最適化
3. クラスタを形成するためのギャップが生成がされる
2つのクラスタが最適化初期で分離された場合
それらを再び引き寄せるための力がなくなる
272015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-27-320.jpg)






















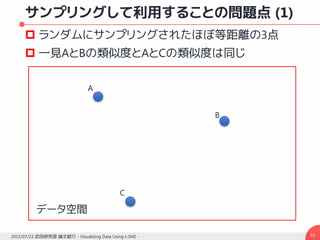
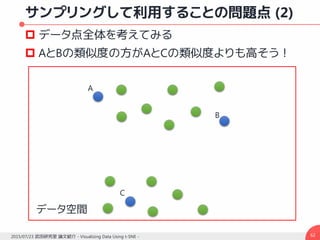

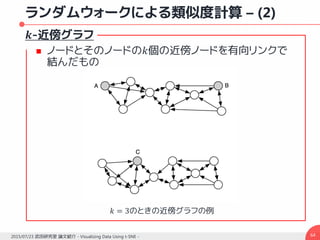
![ランダムウォークによる類似度計算 – (3)
最短パスではなく全体のパスを統合して用いる理由
“Short-circuit”問題の回避 [Lafon and Lee, 2006]
“Short-circuit”問題
データ空間中の2つの領域の間のノイズ点によって
橋が形成されてしまうこと
652015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
ノイズ点
本来のあるべき姿 ノイズ点によって橋が形成](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-65-320.jpg)
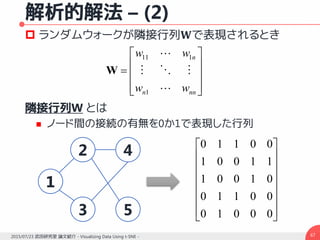
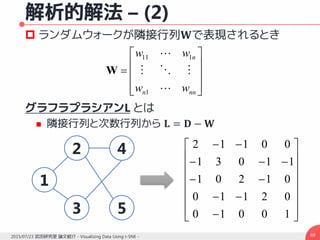
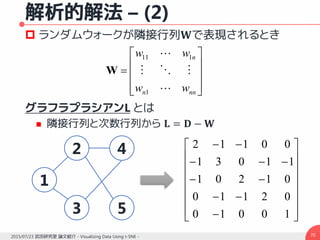
![解析的解法 – (1)
類似度計算のもう一つの方法 [Grady, 2006]
Kakutani, 1945; Doyle and Shel, 1984 曰く
ランドマーク点でない点から初期化されたランダム
ウォークが特定のランドマーク点に最初にたどり着く確率
あるランドマーク点が1に固定され,別のランドマーク点
を0とした場合の,あるランドマーク点の位置を境界条件
とした組み合わせディリクレ問題の解
両者は等しくなる(そうです)
662015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-66-320.jpg)
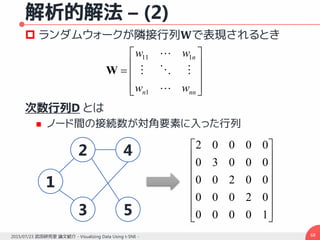
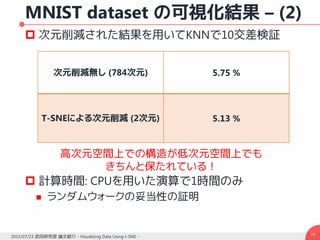
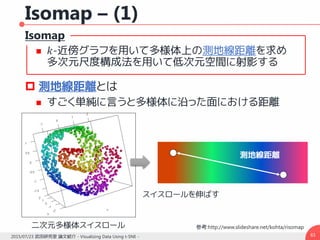
![解析的解法 – (3)
求める解は組み合わせディリクレ積分公式の最小化
一般性を失うことなくランドマーク点が先頭に来る
ように入れ替えを行える
𝑥 𝑁に関して微分し臨界点を求めることは線形
システムを解くことと等価
712015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
)32(
2
1
][ T
LxxxD
)34(2
2
1
)33(
2
1
][ TT
NN
T
NM
TT
NLL
T
L
N
L
N
T
L
NLN
xLxxBxxLx
x
x
LB
BL
xxxD
)35(T
BxL NN ](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-71-320.jpg)










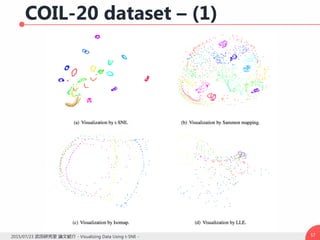
![他のノンパラ手法との比較 – (1)
Classical scaling [Torgerson, 1952]
高次元空間上での距離と低次元空間上での距離の
間の二乗和誤差を最小化するような線形変換
目的関数
Classical scalingの問題点
線形変換ではカーブした多様体をモデル化できない
近くのデータ点よりも遠くのデータ点の距離を保持
することに注目している
この問題を解決しようとした手法がSammon mapping
882015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
ij
ijij ddE
2*
𝑑𝑖𝑗
∗
: 高次元空間上での距離
𝑑𝑖𝑗: 低次元空間上での距離](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-88-320.jpg)






![他のノンパラ手法との比較 – (7)
Diffusion map [Lafon and Lee, 2006]
近傍グラフ上のランダムウォークに基づいた
Diffusion距離と低次元空間上での距離を最小化
Diffusion距離
目的関数
952015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
)15(
)(
),( )0(
)()(
)(
k k
t
jk
t
ik
ji
t
x
pp
xxD
𝑝𝑖𝑘
(𝑡)
∶ 時刻𝑡において粒子が𝑥𝑖から𝑥 𝑘に移動する確率
𝜓 𝑥 𝑘
(0)
: その点の局所的な密度 SNEと同様の考え方
)16(),(
2)(
ji
jiji
t
yyxxDC
𝑦𝑖: 低次元空間上での座標](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-95-320.jpg)
![他のノンパラ手法との比較 – (8)
Diffusion map [Lafon and Lee, 2006]
近傍グラフ上のランダムウォークに基づいた
Diffusion距離と低次元空間上での距離を最小化
目的関数
Diffusion mapの問題点
Classical scalingと同様の問題
遠い距離の点を重視しすぎてしまう
データのLocalな構造の情報が失われる
962015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
)16(),(
2)(
ji
jiji
t
yyxxDC](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-96-320.jpg)


![t-SNEの弱点 – (2)
2. データの本質的な次元の呪いを受ける
t-SNEはデータのLocal構造に基づく
次元の呪いの影響を非常に受けやすい![Bengio, 2007]
以下のような条件で可視化がイマイチに
データの本質的な次元が非常に高い (100次元ほど)
それぞれ潜んでいる多様体が大きく異なっている
多様体上での局所的線形性の仮定が崩れるため
LLEやIsomapも全く同様の問題を持つ
より複雑なデータを可視化したい場合
Auto-encoder [Hinton et al., 2006] を利用
層構造で複雑な非線形関数を表現可能
992015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -
そのような構造を二次元上に可視化することは
そもそも不可能であるということを念頭を置くべき](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-99-320.jpg)
![t-SNEの弱点 – (3)
3. 目的関数の収束が保証されていない
ほとんどの主要な次元削減手法 → 目的関数が凸状
が,t-SNEは目的関数の凸性が保証されていない
可視化結果がいくつかのパラメータに依存
しかしながら
パラメータをランダムに変更
可視化結果自体はそれほど変化しない
t-SNEの利用を拒む理由にはなり得ない!
他の手法も計算量の問題から結局似たような問題に
LLEやLaplacian eigenmapも逐次最適化手法
• Iterative Arnoldi [Arnoldi,1951]
• Jacobi-Davidson [Fokkema et al., 1999]
1002015/07/23 武田研究室 論文紹介 - Visualizing Data Using t-SNE -](https://image.slidesharecdn.com/20150723hayashislide-160107084940/85/Visualizing-Data-Using-t-SNE-100-320.jpg)





![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...](https://cdn.slidesharecdn.com/ss_thumbnails/dp-mrmkimicml2012-120727233419-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)














