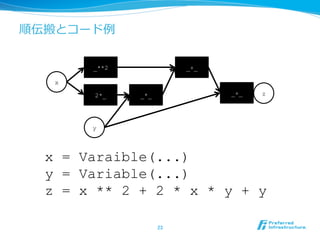
word2vec
class ContinuousBoW(chainer.Chain):
def __init__(self,n_vocab, n_units, loss_func):
super(ContinuousBoW, self).__init__(
embed=F.EmbedID(n_vocab, args.unit),
loss_func=loss_func)
def __call__(self, x, context):
h = None
for c in context:
e = self.embed(c)
h = h + e if h is not None else e
return self.loss_func(h, x)
45
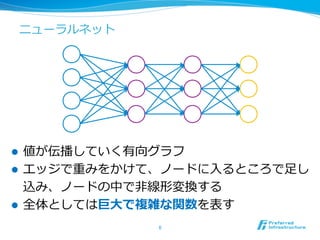
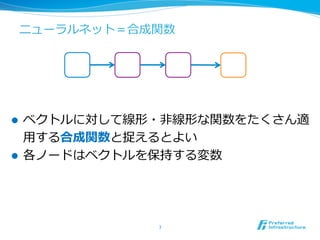
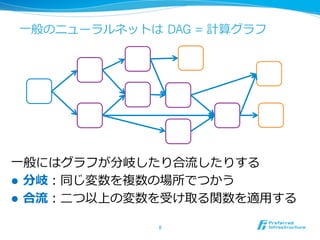
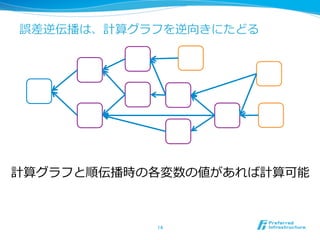
コンテキストの平均を取って出
⼒力力に投げるだけ
埋め込みベクトル




































![Recursive Netで構⽂文⽊木をたどる
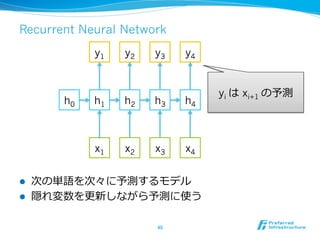
def traverse(model, node):
if isinstance(node['node'], int): # leaf node
word = xp.array([node['node']], np.int32)
loss = 0
x = chainer.Variable(word)
v = model.leaf(x)
else: # internal node
left_node, right_node = node['node']
left_loss, left = traverse(model, left_node)
right_loss, right = traverse(model, right_node)
v = model.node(left, right)
loss = left_loss + right_loss
48](https://image.slidesharecdn.com/20151125webdbchainer-151125072125-lva1-app6892/85/Chainer-48-320.jpg)










































![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)








































