Download as PDF, PPTX














![Datasets and DataFrames
In 2015, we added DataFrames & Datasets as structured data APIs
• DataFrames are collections of rows with a schema
• Datasets add static types,e.g. Dataset[Person]
• Both run on Tungsten
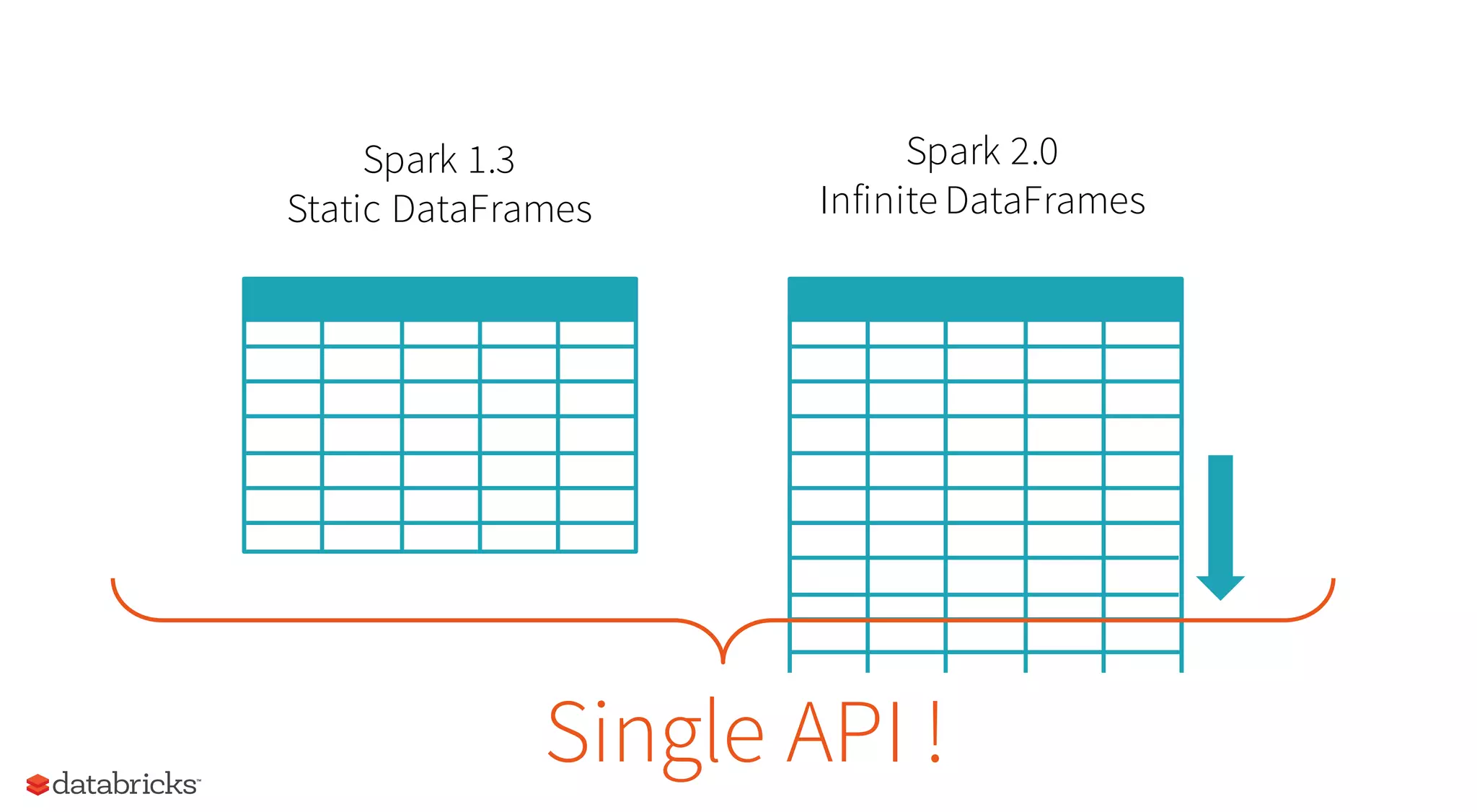
Spark 2.0 will merge these APIs: DataFrame = Dataset[Row]](https://image.slidesharecdn.com/alookaheadatspark2-160401163047/75/A-look-ahead-at-spark-2-0-17-2048.jpg)
![Example
case class User(name: String, id: Int)
case class Message(user: User, text: String)
dataframe = sqlContext.read.json(“log.json”) // DataFrame, i.e. Dataset[Row]
messages = dataframe.as[Message] // Dataset[Message]
users = messages.filter(m => m.text.contains(“Spark”))
.map(m => m.user) // Dataset[User]
pipeline.train(users) // MLlib takes either DataFrames or Datasets](https://image.slidesharecdn.com/alookaheadatspark2-160401163047/75/A-look-ahead-at-spark-2-0-18-2048.jpg)













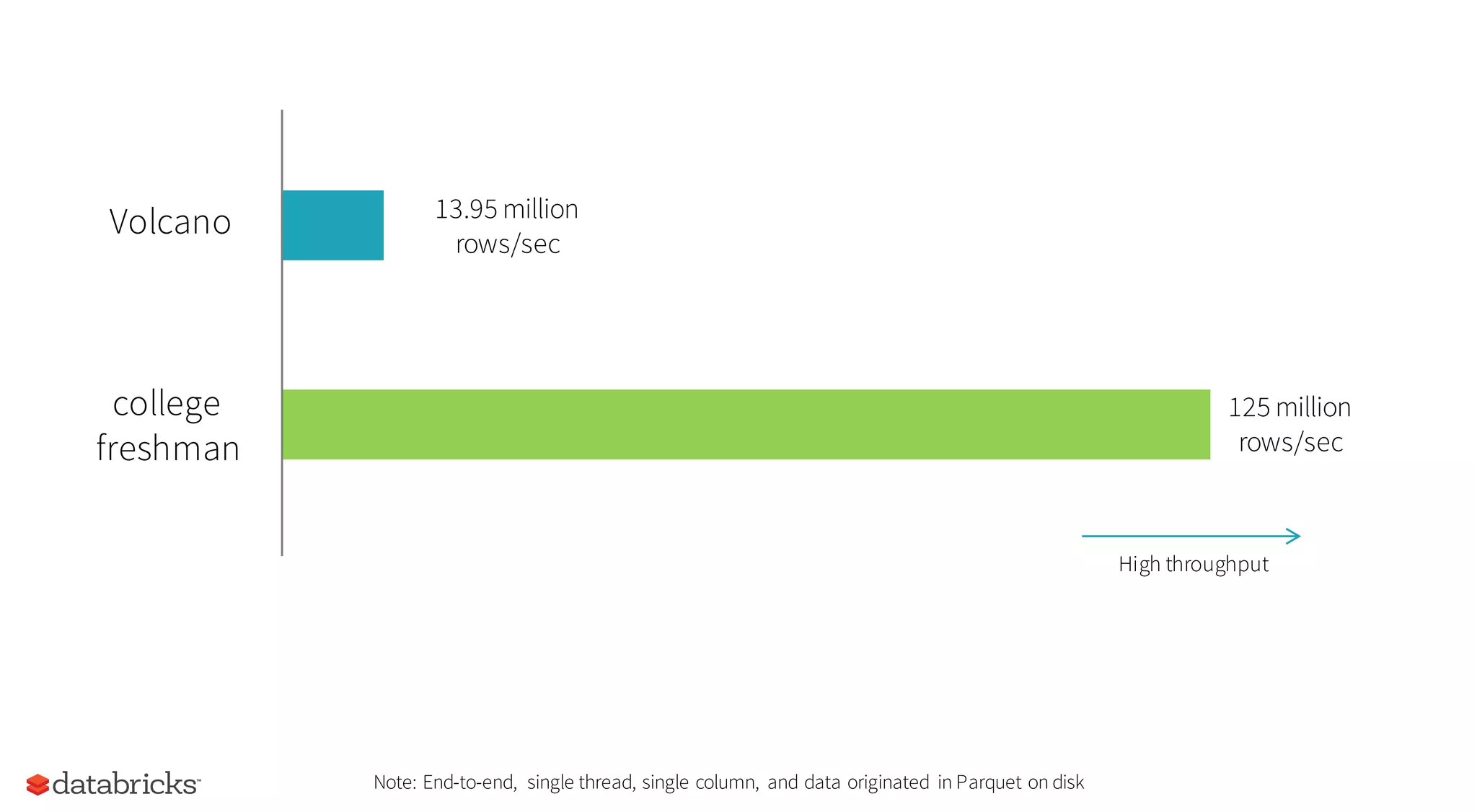
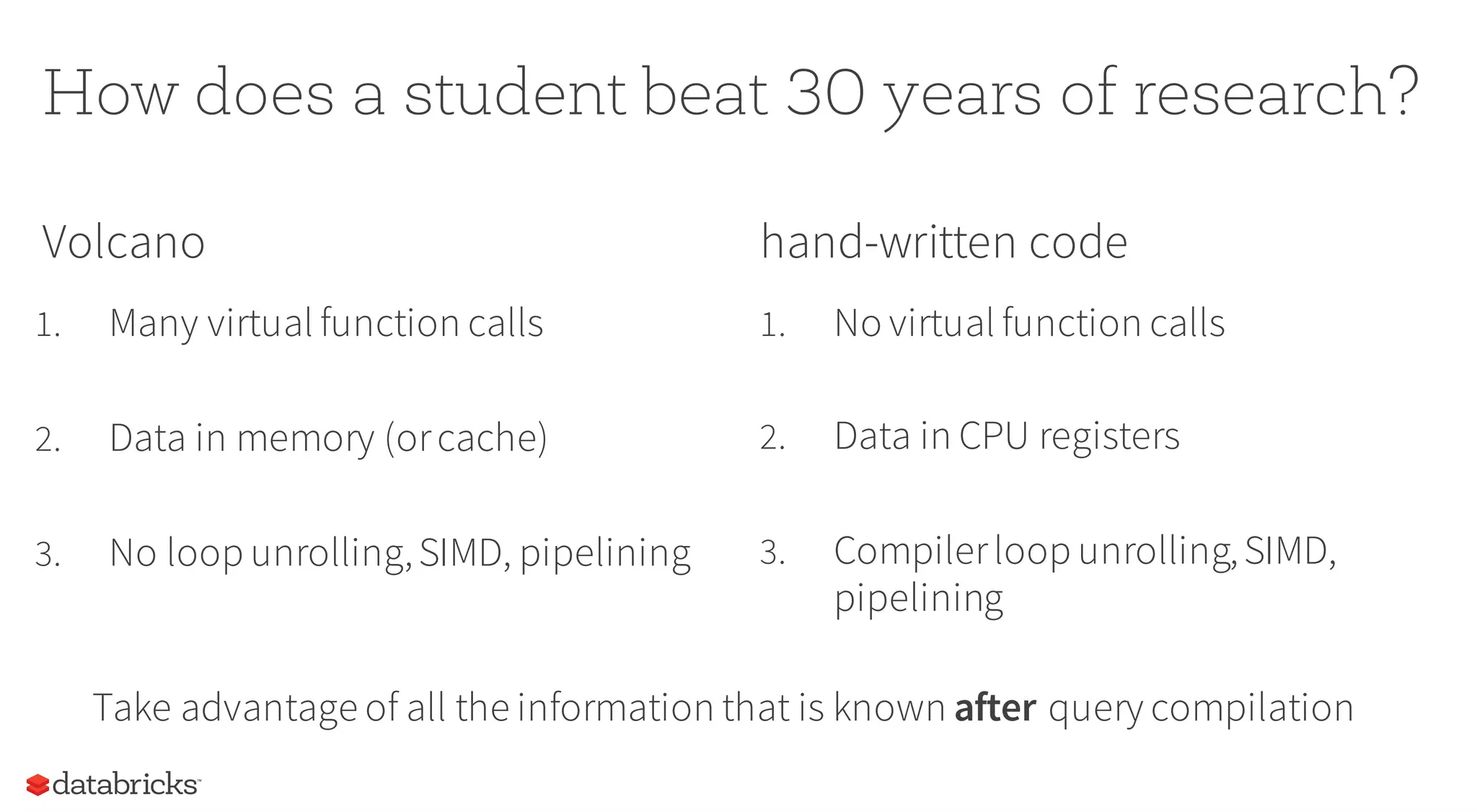






This document summarizes the upcoming features in Spark 2.0, including major performance improvements from Tungsten optimizations, unifying DataFrames and Datasets into a single API, and new capabilities for streaming data with Structured Streaming. Spark 2.0 aims to further simplify programming models while delivering up to 10x speedups for queries through compiler techniques that generate efficient low-level execution plans.










































































































