Download as PDF, PPTX










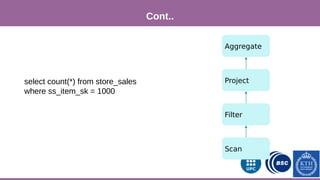


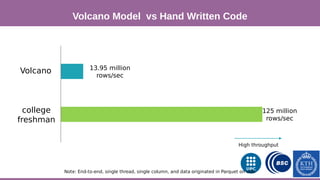


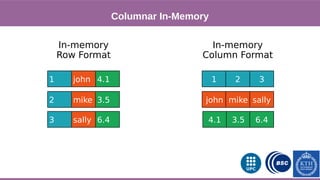


![Phase 1
Spark 1.4 - 1.6
Memory Management
Code Generation
Cache-aware Algorithms
Phase 2
Spark 2.0+
Whole-stage Code Generation
Columnar in Memory Support
Both whole stage codegen [SPARK-12795] and the vectorized
parquet reader [SPARK-12992] are enabled by default in Spark 2.0+](https://image.slidesharecdn.com/boostingsparkperformance-170223131918/85/Boosting-spark-performance-An-Overview-of-Techniques-23-320.jpg)
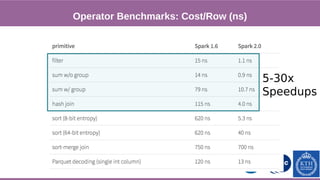

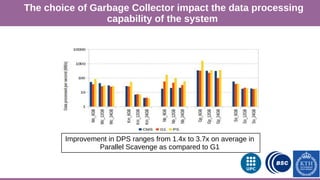
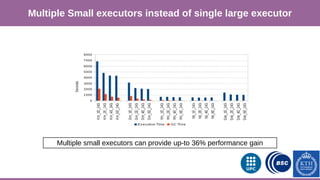
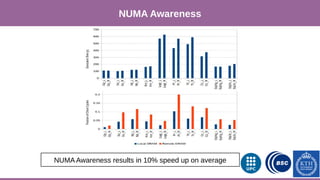
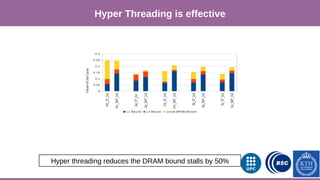




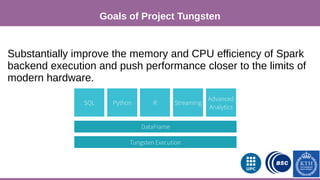
This document provides an overview of techniques to boost Spark performance, including: 1) Phase 1 focused on memory management, code generation, and cache-aware algorithms which provided 5-30x speedups 2) Phase 2 focused on whole-stage code generation and columnar in-memory support which are now enabled by default in Spark 2.0+ 3) Additional techniques discussed include choosing an optimal garbage collector, using multiple small executors, exploiting data locality, disabling hardware prefetchers, and keeping hyper-threading on.
















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)






