Downloaded 17 times











![Class Transformers
java.lang.instrument.ClassTransformer
byte[] transform(ClassLoader l, String name, Class<?> cls,
ProtectionDomain pd, byte[] classfileBuffer)
● Inspect and modify class data
○ without recompilation
○ even on-the-fly
● Powerful
○ introduce callbacks
○ patch problematic code
● Not a simple task
○ class data structure
○ constant pool
○ stack frame maps
http://wikipedia.org](https://image.slidesharecdn.com/57afcef1-84a3-45c7-837d-4844ed418ac3-161027152539/85/Extending-Spark-With-Java-Agent-handout-15-320.jpg)







![Transform Classes
def get(blockId: BlockId): Option[BlockResult] = {
val local = getLocal(blockId)
if (local.isDefined) {
logInfo(s"Found block $blockId locally")
return local
}
val remote = getRemote(blockId)
if (remote.isDefined) {
logInfo(s"Found block $blockId remotely")
return remote
}
None
}
def get(blockId: BlockId): Option[BlockResult] = {
AgentRuntime.useBlock(blockId, currentStage)
val local = getLocal(blockId)
if (local.isDefined) {
logInfo(s"Found block $blockId locally")
return local
}
val remote = getRemote(blockId)
...
...
}](https://image.slidesharecdn.com/57afcef1-84a3-45c7-837d-4844ed418ac3-161027152539/85/Extending-Spark-With-Java-Agent-handout-24-320.jpg)


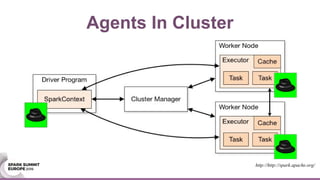







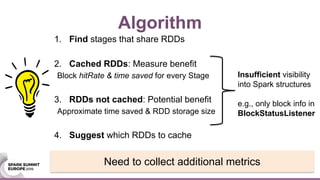
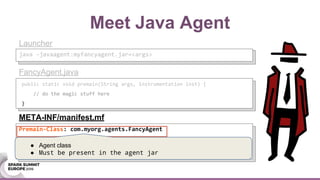
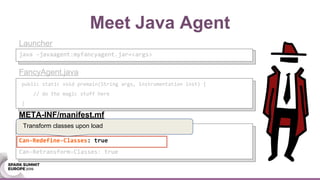
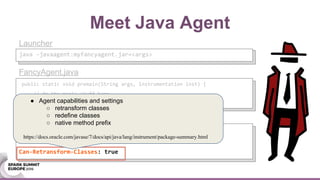
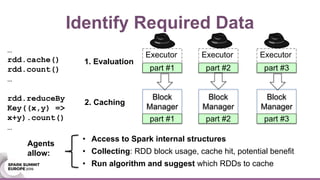
This document discusses using Java agents to extend Spark functionality. Java agents allow instrumentation of JVM applications like Spark at runtime. Specifically, agents could be used to monitor block caching in Spark and make recommendations to improve caching decisions. The document provides examples of how to transform Spark classes at runtime using agents to track block usage and cache hits. Overall, agents provide a powerful way to enhance Spark without requiring code changes.





![[수정본] 우아한 객체지향](https://cdn.slidesharecdn.com/ss_thumbnails/woowahan-oo-190624161343-thumbnail.jpg?width=640&height=640&fit=bounds)




























































