Downloaded 23 times




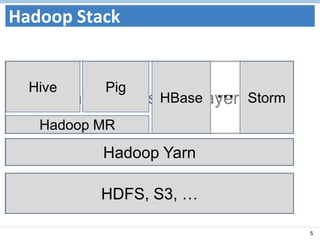

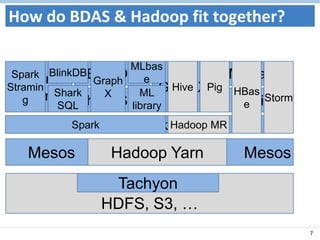










This document discusses the Spark analytics platform and its advantages over existing Hadoop-based platforms. Spark provides a unified data processing engine for batch, interactive, and streaming workloads. It includes components like Spark Core for distributed computing, Spark Streaming for real-time data processing, Shark for SQL and analytics, GraphX for graph processing, and MLlib for machine learning. Spark aims to be up to 100x faster than Hadoop for interactive queries by keeping data in-memory using its Resilient Distributed Datasets (RDDs). It also leverages other projects like Mesos for resource management and Tachyon for a fault-tolerant shared storage layer.



































































