Download as PDF, PPTX




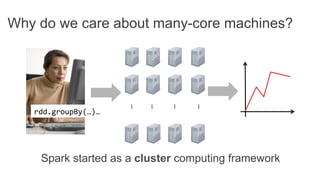





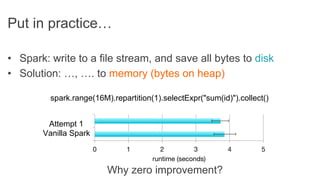
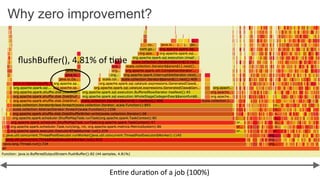

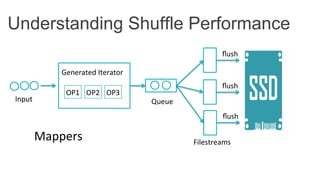
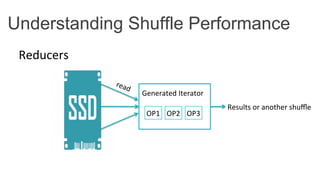


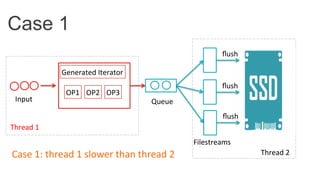
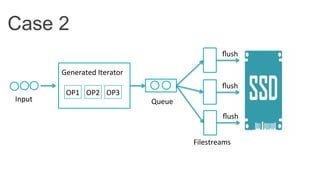
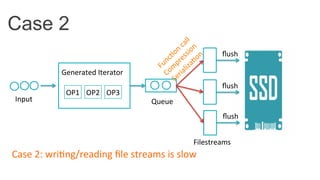
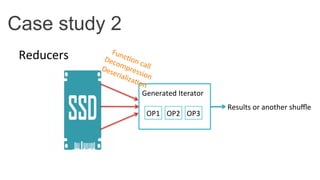


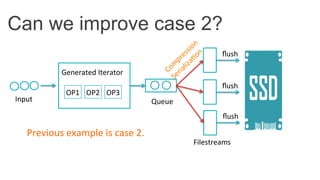

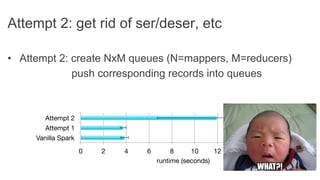
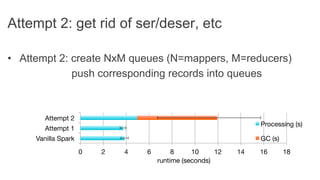

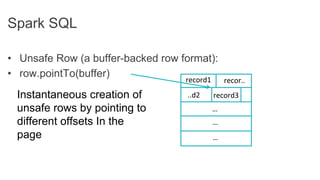

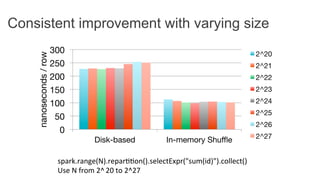


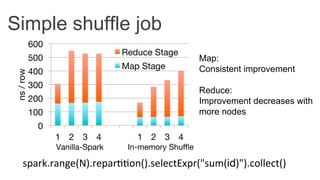
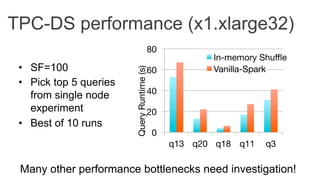



This document discusses improving Spark performance on many-core machines by implementing an in-memory shuffle. It finds that Spark's disk-based shuffle is inefficient on such hardware due to serialization, I/O contention, and garbage collection overhead. An in-memory shuffle avoids these issues by copying data directly between memory pages. This results in a 31% median performance improvement on TPC-DS queries compared to the default Spark shuffle. However, more work is needed to address other performance bottlenecks and extend the in-memory shuffle to multi-node clusters.











































































































