Download as PDF, PPTX



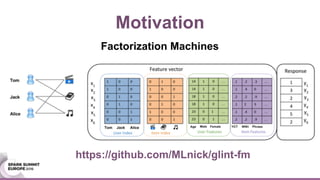

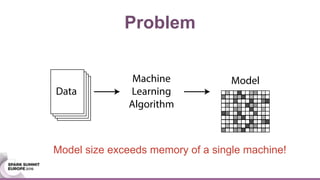

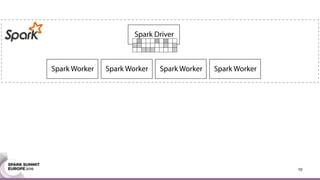
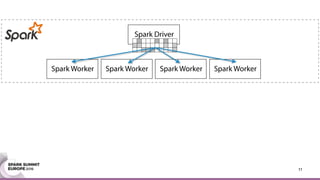
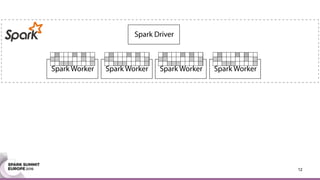
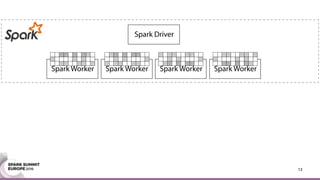
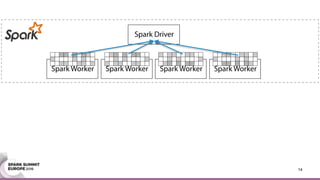
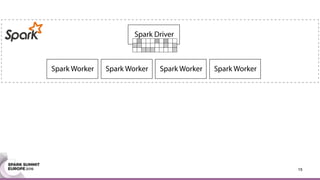



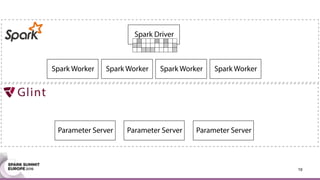
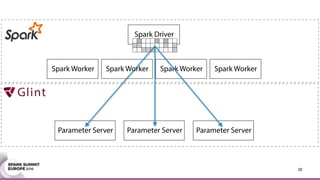
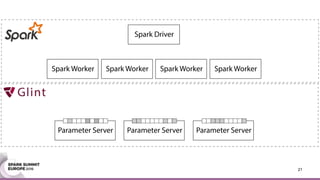
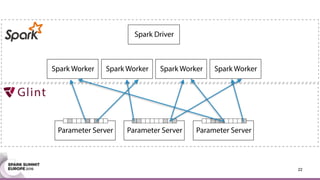
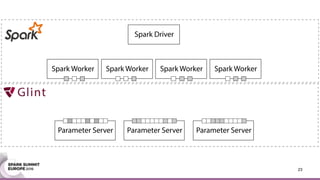
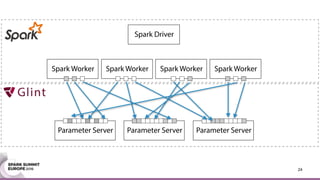
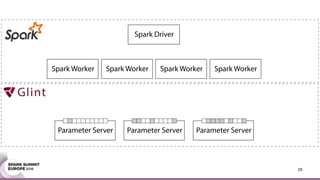





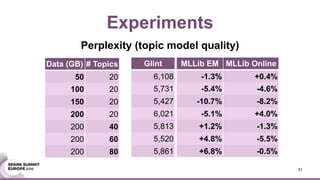
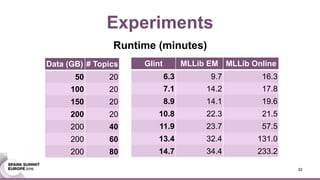
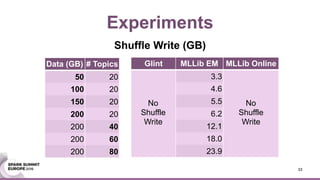

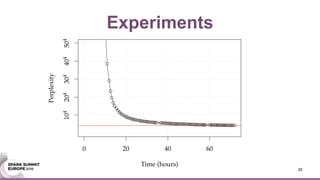




This document discusses an asynchronous parameter server called Glint for Spark. It was created to address the problem of machine learning models exceeding the memory of a single machine. Glint distributes models over multiple machines and allows two operations - pulling and pushing model parameters. It was tested on topic modeling of a 27TB dataset using 1,000 topics, significantly outperforming MLLib in terms of quality, runtime, and scalability. Future work may include improved fault tolerance, custom aggregation functions, and implementing additional algorithms like deep learning.









































































































