3/16/2022 3
However, annotatingthem is often expensive and time consuming
=> We should think more about label efficient learning
https://appen.com/blog/data-annotation/
https://medicalxpress.com/news/2017-10-dementia-costly.html
https://www.roastycoffee.com/coffee-makes-me-tired/
Semi-supervised Learning (SSL)
•Problem: Combine labeled and unlabeled data (usually >= 90% of the
data) to train a model
• Assumptions:
• Smoothness Assumption
• Cluster Assumption
• Manifold Assumption
3/16/2022 8
Semi-Supervised Learning, Chapelle et al., 2006
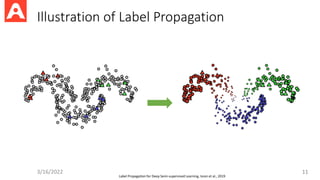
Label Propagation (Zhuand Ghahramani, 2004)
• Assume nonnegative similarity scores between samples
• Construct an undirected graph over all nodes with edges weighted by
similarity scores.
• Perform the following steps until convergence:
• Propagate labels: , where is the transition matrix
• Set the class probability of labeled data to the ground-truth
3/16/2022 10
11.
Illustration of LabelPropagation
3/16/2022 11
Label Propagation for Deep Semi-supervised Learning, Iscen et al., 2019
12.
Convergence of LabelPropagation
• Denote the class probability vectors and transition matrix for all
nodes as follows:
• One step of the algorithm is:
• After an infinite number of steps:
3/16/2022 12
Converge to 0 as t -> ∞
13.
Label Propagation asEnergy Minimization
• The energy function:
where is the graph Laplacian.
3/16/2022 13
smoothness
regularization
label constraint
solution is a harmonic
function satisfying the
Laplace’s equation:
14.
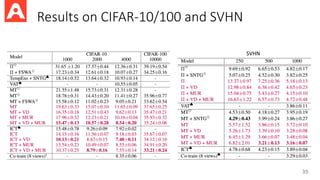
Problems of LabelPropagation (LP)
• LP is transductive, thus, cannot handle new samples.
• LP requires matrix inversion for the exact solution, which is usually
costly in practice.
3/16/2022 14
15.
Label Propagation +Gaussian Mixture Model
• Intuition: GMM provides the local fit to data while LP ensures the
global manifold structure.
3/16/2022 15
Implicitly assume that
#mixtures ≠ #classes
GMM
GMM Training andLabel Inference
• We can train the GMM via the EM algorithm
• After EM converges, we can predict the label as:
3/16/2022 17
18.
Label Smoothness Regularization
Usethe predicted class probability for unlabeled data in the energy
where
Finetune by maximizing the following objective:
3/16/2022 18
ELBO
19.
Training Procedure forLP+GMM
• Train all parameters of p(m), p(x|m), p(y|m) by maximizing via the
standard EM algorithm.
• Fix p(m), p(x|m) and train p(y|m) by maximizing .
3/16/2022 19
Problems of LP+ GMM
• EM algorithm is not applicable to high dimensional data like images.
• This method still requires full batch updates.
3/16/2022 21
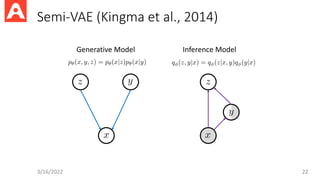
Training Objective forSemi-VAE
• ELBO on labeled data:
• ELBO on unlabeled data:
• Final objective:
3/16/2022 23
Weight the NLL by soft-label Avoid over-confident predictions
Both y and z are used to predict x
Problems of Semi-VAE
•It is a generative model while the classification problem is
discriminative.
• => It may be better to perform SSL with discriminative model only
• It has no mechanism to ensure that the decoder must use both y and
z to reconstruct x. If z is a big vector, the decoder may just use z.
• => A possible solution is making y and z independent: I(y, z) = 0
3/16/2022 25
Disentanglement
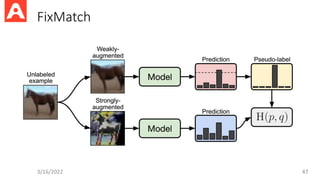
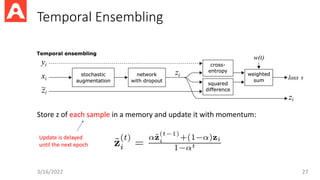
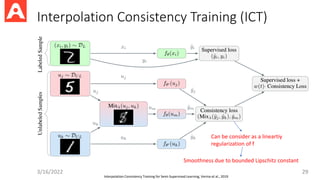
Interpolation Consistency Training(ICT)
3/16/2022 29
Can be consider as a lineartiy
regularization of f
Smoothness due to bounded Lipschitz constant
Interpolation Consistency Training for Semi-Supervised Learning, Verma et al., 2019
30.
Training Procedure ofICT
3/16/2022 30
Mixup as
consistency loss
Like mean teacher
These samples from the teacher model
Train student model
31.
Intuitions
• Intuitions:
• Learna smooth input-output manifold by forcing the classifier to give
consistent predictions for inputs under simple perturbations.
• Can we have better data and weight perturbations?
3/16/2022 31
32.
Maximum Uncertainty Regularization(MUR)
• Under weak data perturbation, is often close to .
The classifier can only learn a locally smooth mapping from to .
• We want to be: i) not too close to , and ii) difficult for the
classifier to predict correctly.
• We choose to be a maximum uncertain (w.r.t. ) virtual point:
32
3/16/2022 Semi-Supervised Learning with Variational Bayesian Inference and Maximum Uncertainty Regularization, Do et al., 2020
33.
Approximating
• Recall thatdefined as follows:
• We can quickly approximate by maximizing the first-order Taylor
expansion of , which leads to the solution:
where is the gradient of at .
33
3/16/2022
34.
Approximating (cont.)
• Wecan also approximate using projected gradient descent. The
update formula at step t+1 is given by:
• Solving the above equations give us:
34
3/16/2022
35.
Bayesian Learning asnatural Weight Perturbation
• Weights of a classifier is assumed to be random variables with prior
distribution
• Using Bayes’ rule, we can infer the posterior distribution of after
observe the training data:
• Since the posterior distribution usually does not have analytical form,
we approximate it using variational method.
3/16/2022 35
36.
Variational Bayesian Inference(VBI)
3/16/2022 36
Control the model’s complexity
Control the data misfit
Like ensemble methods
Use Variational Dropout to
facilitate this sampling
Note: p(w) is chosen to be the log-uniform distribution by Kingma et al., 2014 and it was shown to be pathological by many
works. However, it cannot be easily replaced [1] and still work well in practice. For a better alternative, please check [2].
[1]: Variational Bayesian dropout: pitfalls and fixes, Hron et al., 2018
[2]: Structured Dropout Variational Inference for Bayesian Neural Networks, Nguyen et al., 2021
37.
Consistency under WeightPerturbation (CWP)
• The consistency loss under weight perturbation is given below:
where is the mean of .
37
3/16/2022 Semi-Supervised Learning with Variational Bayesian Inference and Maximum Uncertainty Regularization, Do et al., 2020
38.
Final Objective
The finalobjective when combining weight perturbation (via VBI) and
data perturbation (via MUR) is given by:
where can be an arbitrary consistency-regularization-based
method like Pi-model, Mean Teacher or ICT.
38
3/16/2022
Semi-Supervised Learning with Variational Bayesian Inference and Maximum Uncertainty Regularization, Do et al., 2020
or Variational Dropout (VD)
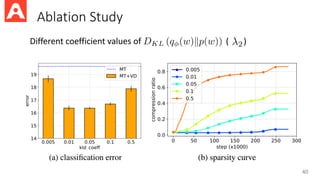
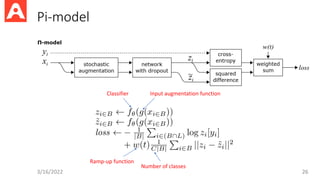
Importance of DataAugmentation in SSL
• Consistency-Regularization-based methods like Pi-model, Mean
Teacher, ICT, MixMatch use only simple (weak) data augmentation.
• MUR can provide some help but still cannot replace good data
augmentation.
3/16/2022 44
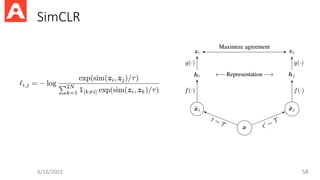
NCE
• We wantto estimate/model the distribution
• Assume we have a noise distribution as reference
=> Transforming into binary classification
3/16/2022 53
P(C=0)/P(C=1)
Noise Constrastive Estimation, Ke Tran
Results with differentdata augmentations
3/16/2022 59
SimCLR significantly
depends on data
augmentation
60.
Results with differentbatch size
3/16/2022 60
SimCLR significantly
depends on batch size
61.
Advantages and Drawbacksof SimCLR
• Advantages:
• Simple to implement and use
• Drawbacks:
• Requires large batch size
• Memory intensive <= Addressed by MoCo
3/16/2022 61
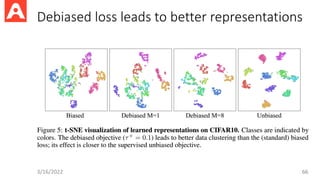
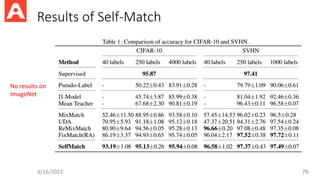
Debiased Contrastive Learning
•Sampling bias of standard contrastive loss: Negative samples can be
drawn from the same class as positive samples
3/16/2022 63
Negative distribution Weighting parameter
64.
3/16/2022 64
A practicaldebiased form based on the
asymptotic form of unbiased loss when N -> ∞
Debiased Contrastive Loss
Advantages and Drawbacksof BYOL
• Advantages:
• Eliminate the need for negative samples in standard contrastive loss
• Less depends on batch size and data augmentation compared to SimCLR
• Drawbacks:
• Learned representations can be collapsed to the same vector if:
• No prediction network is used
• No gradient stop is enforced on the target (EMA) branch
3/16/2022 69
Computing the codeq
• Assume we have feature vectors and
prototypes
• Compute codes via the optimization below:
where is the transportation
polytope
3/16/2022 71
D x B
D x K
K x B
72.
Computing the codeq (cont.)
• The optimal soft codes Q takes the form of a normalized exponential
matrix:
where and are renormalization vectors in and , respectively.
and are computed using the iterative Sinkhorn-Knopp algorithm.
3/16/2022 72
Advantages and Drawbacksof SwAV
• Advantages:
• Does not require negative samples, thus run faster than other methods
• Drawbacks:
• Requires some tricks to avoid collapse such as class balancing, which can
sometimes be violated in real situation
3/16/2022 76
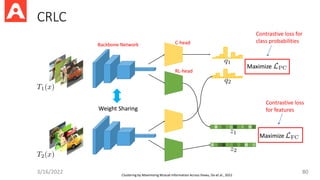
CRLC
3/16/2022 80
Contrastive lossfor
class probabilities
Contrastive loss
for features
Clustering by Maximizing Mutual Information Across Views, Do et al., 2021
81.
Training Objective ofCRLC
3/16/2022 81
People usually choose f
to be a cosine similarity
but is it a good critic?
82.
What is agood critic?
• Recall that the negative contrastive loss is the lower bound of the
mutual information up to a constant.
• Thus, a good critic should make this bound as tight as possible.
• The authors have proven the following result:
3/16/2022 82
p(y) is canceled out by the
numerator and denominator
83.
Choosing optimal critic
•If we assume that is a Gaussian distribution with mean and
a covariance matrix , then the cosine similarity is the optimal critic
3/16/2022 83
Due to the unit norm
84.
Choosing optimal critic(cont.)
• The optimal critic is the log-of-dot-product function:
3/16/2022 84
May not be theoretically
equivalent is a practically
good approximation
SSL Results andResults with different critics
3/16/2022 86
NegJSD and DotPr are bad,
NegL2 is slightly worse
87.
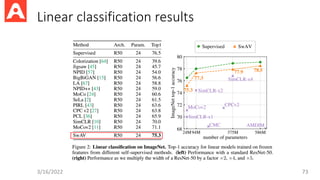
DINO
• Apply contrastivelearning on a Vision Transformer (ViT)
• Verify the importance of momentum encoder, multi-crop training for
contrastive learning
• Achieve 78.3% Top 1 accuracy with the k-NN classifier, and 80.1% Top
1 accuracy with the linear classifier.
3/16/2022 87
Better than supervised learning
with some ResNet architectures
Vision Transformer
3/16/2022 89
AnImage Is Worth 16X16 Words: Transformers for Image Recognition at Scale, Dosovitskiy et al., 2020
An image is
converted into
a sequence of
patches
Simply reuse the
Transformer architecture
Objective
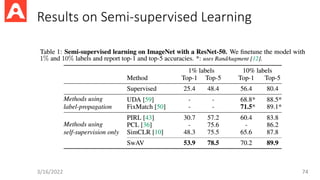
• Assume labeleddata from source domain and unlabeled data from
target domain. Adapt model to the target domain?
3/16/2022 92
Cross domain contrastive loss:
We need pseudo labels
from the target domain
Final objective:
93.
Remaining questions?
• Howto obtain pseudo-labels for data from the target domain?
• What if you don’t have labeled source data but only a model
pretrained on source data?
3/16/2022 93





























![Variational Bayesian Inference (VBI)
3/16/2022 36
Control the model’s complexity
Control the data misfit
Like ensemble methods
Use Variational Dropout to
facilitate this sampling
Note: p(w) is chosen to be the log-uniform distribution by Kingma et al., 2014 and it was shown to be pathological by many
works. However, it cannot be easily replaced [1] and still work well in practice. For a better alternative, please check [2].
[1]: Variational Bayesian dropout: pitfalls and fixes, Hron et al., 2018
[2]: Structured Dropout Variational Inference for Bayesian Neural Networks, Nguyen et al., 2021](https://image.slidesharecdn.com/towardslabelanddataefficientdeeplearning-260111150252-c4bb1ef8/85/Towards-Label-and-Data-Efficient-Deep-Learning-pdf-36-320.jpg)