Downloaded 115 times


























![Two views Features can be split into two independence sets(views): The instance space: Each example: A pair of views x 1 , x 2 satisfy view independence just in case: Pr[X 1 =x 1 | X 2 =x 2 , Y=y] = Pr[X 1 =x 1 |Y=y] Pr[X 2 =x 2 | X 1 =x 1 , Y=y] = Pr[X 2 =x 2 |Y=y]](https://image.slidesharecdn.com/c-6-ii-alternativeclassificationtechnologies457808655-100112134138-phpapp01/85/Data-Mining-C-6-II-classification-and-prediction-36-320.jpg)







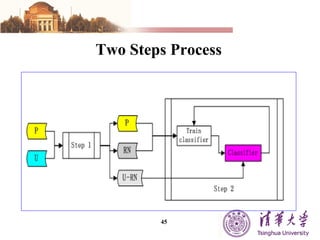
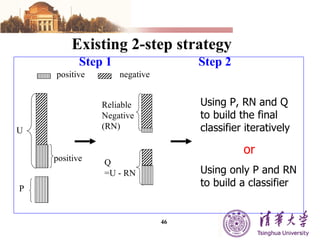





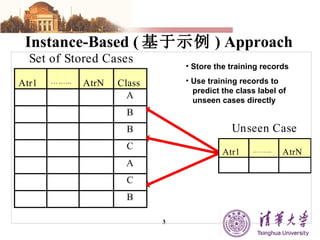
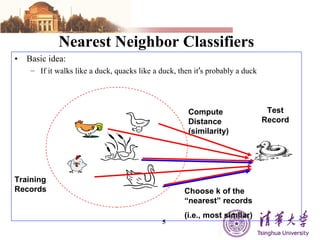
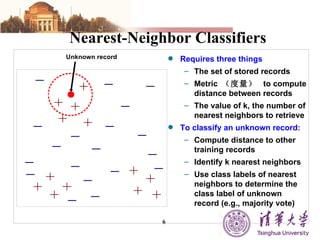
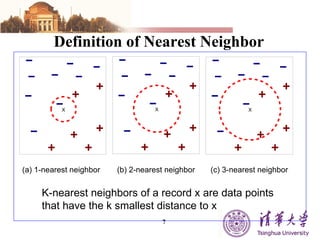
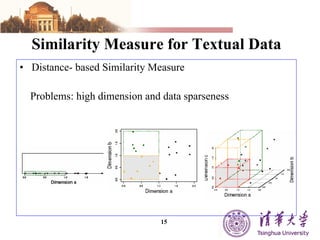
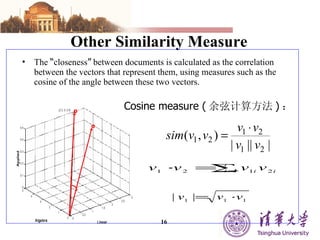
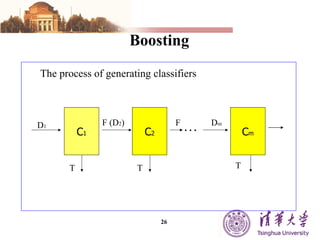
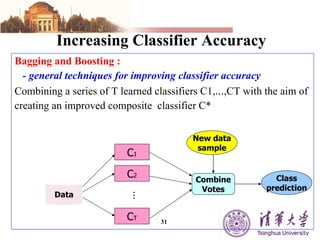
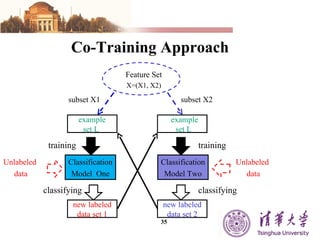
The document summarizes different machine learning classification techniques including instance-based approaches, ensemble approaches, co-training approaches, and partially supervised approaches. It discusses k-nearest neighbor classification and how it works. It also explains bagging, boosting, and AdaBoost ensemble methods. Co-training uses two independent views to label unlabeled data. Partially supervised approaches can build classifiers using only positive and unlabeled data.









































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)























