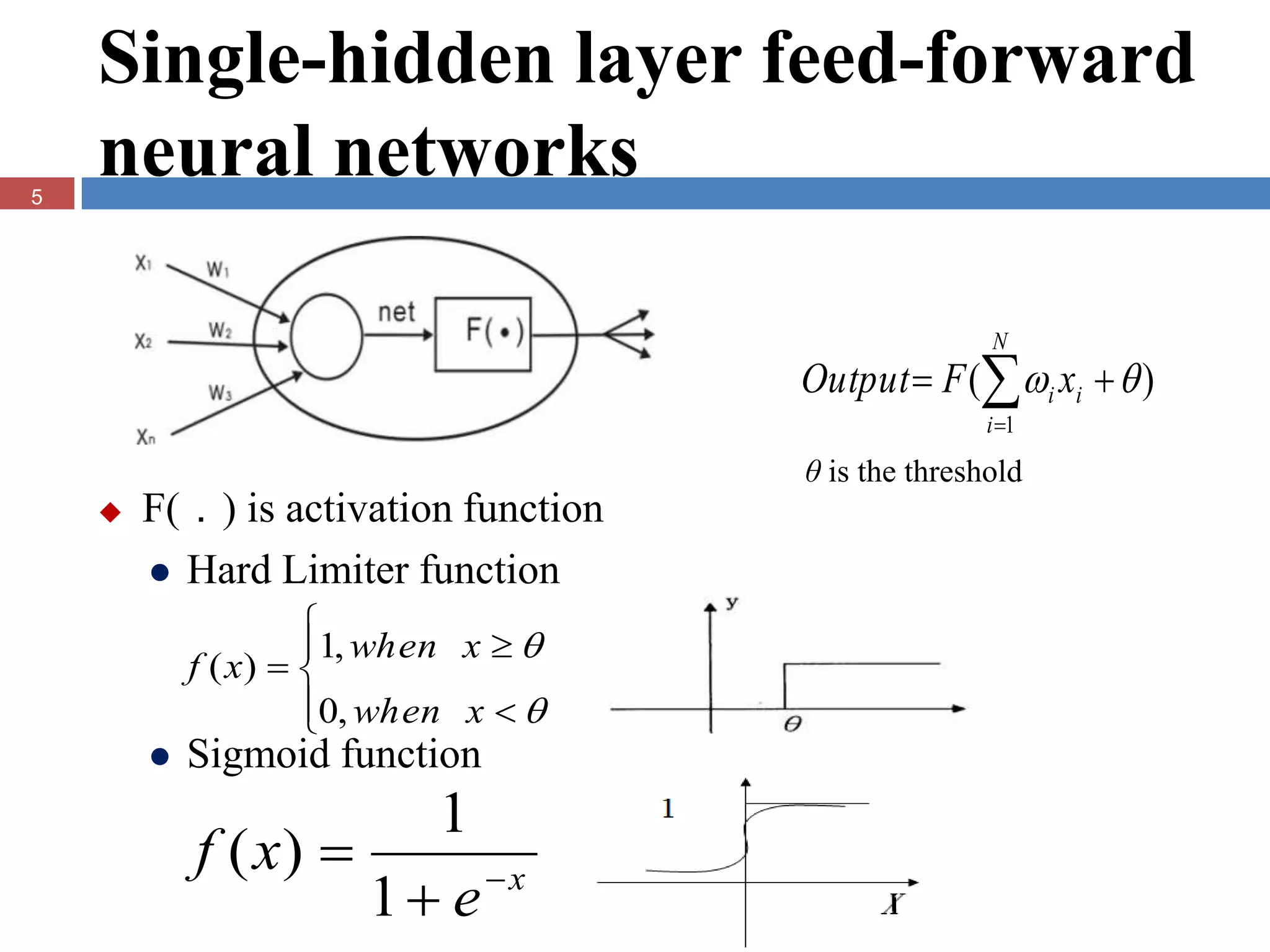
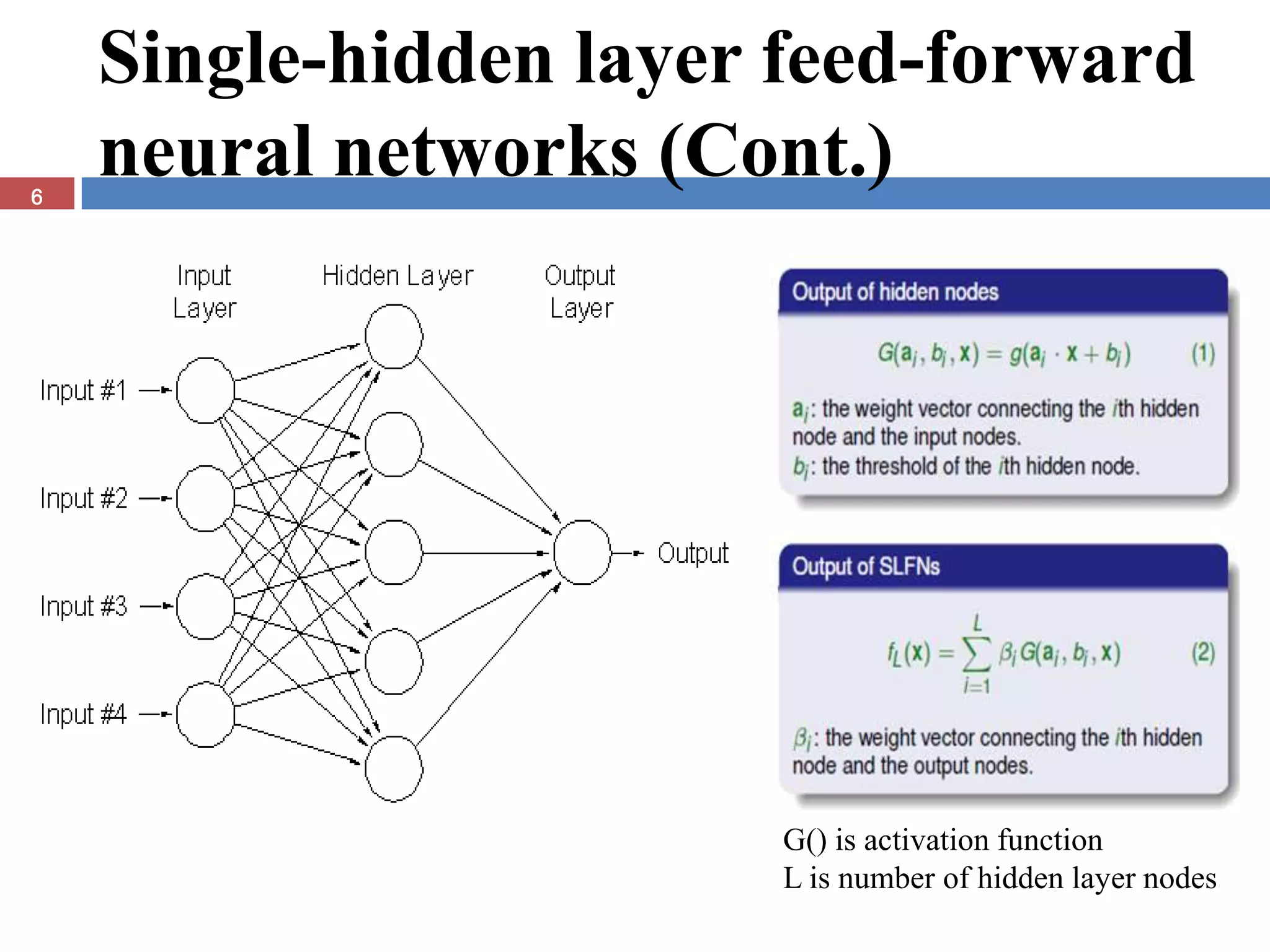
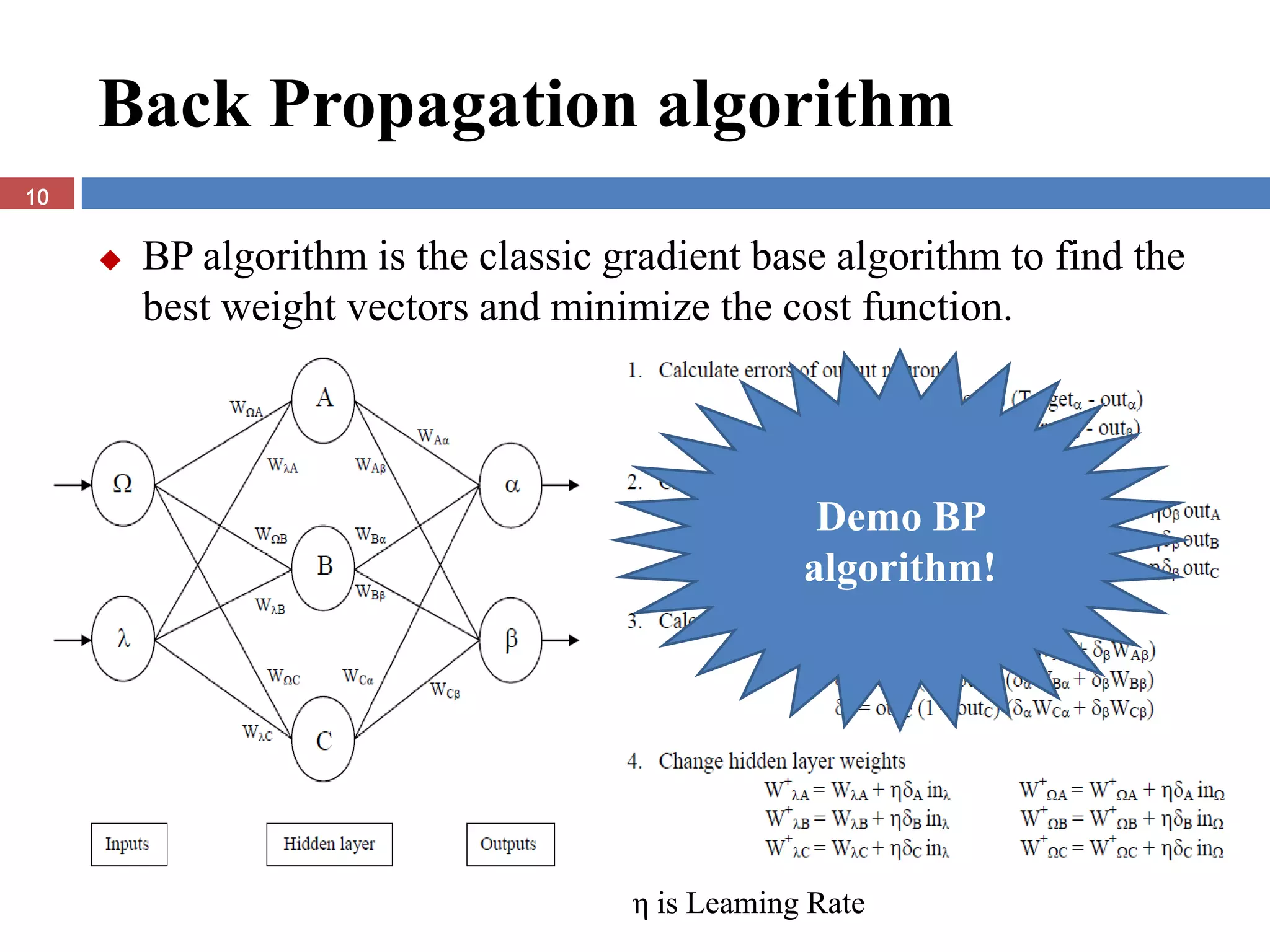
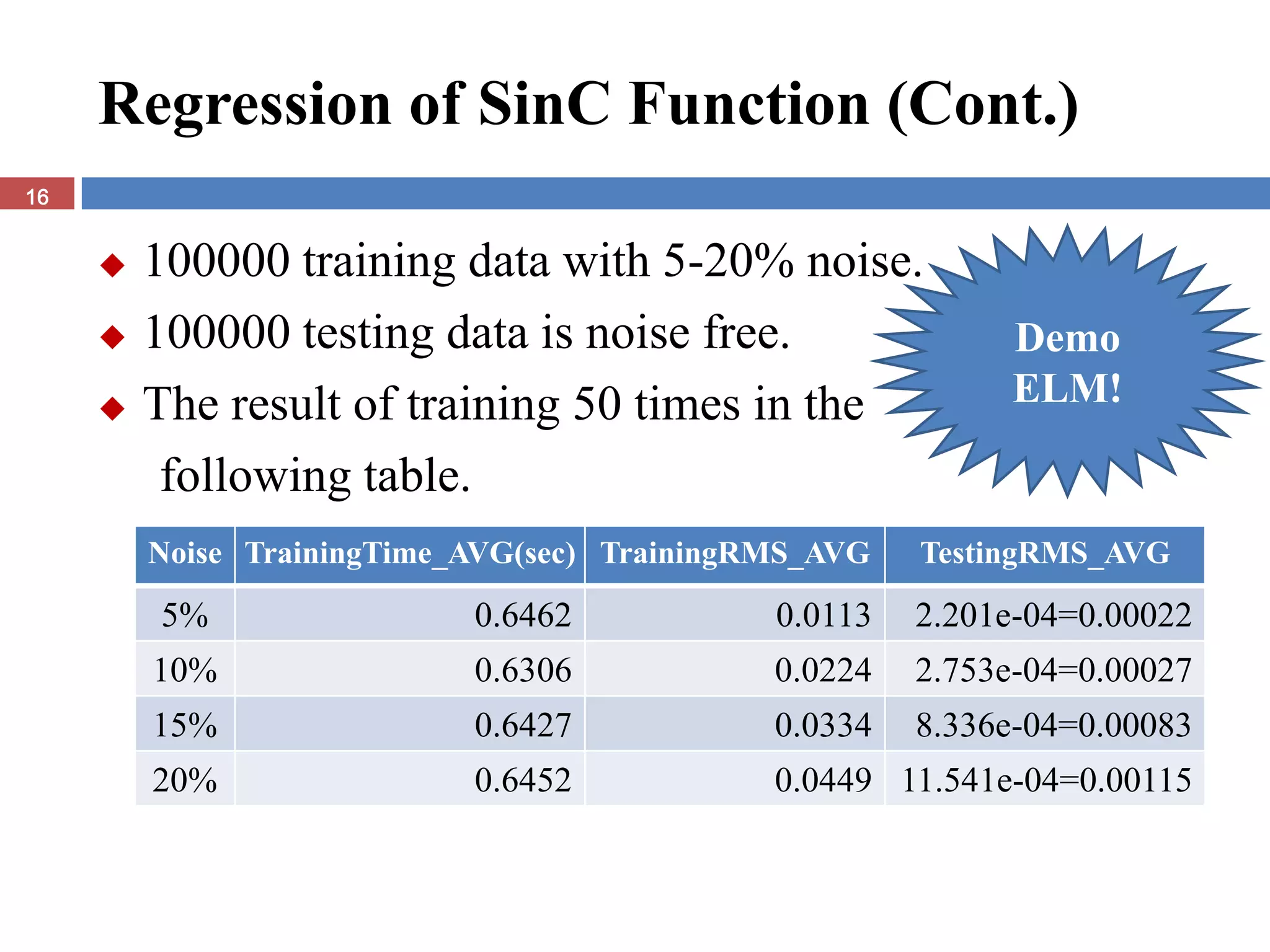
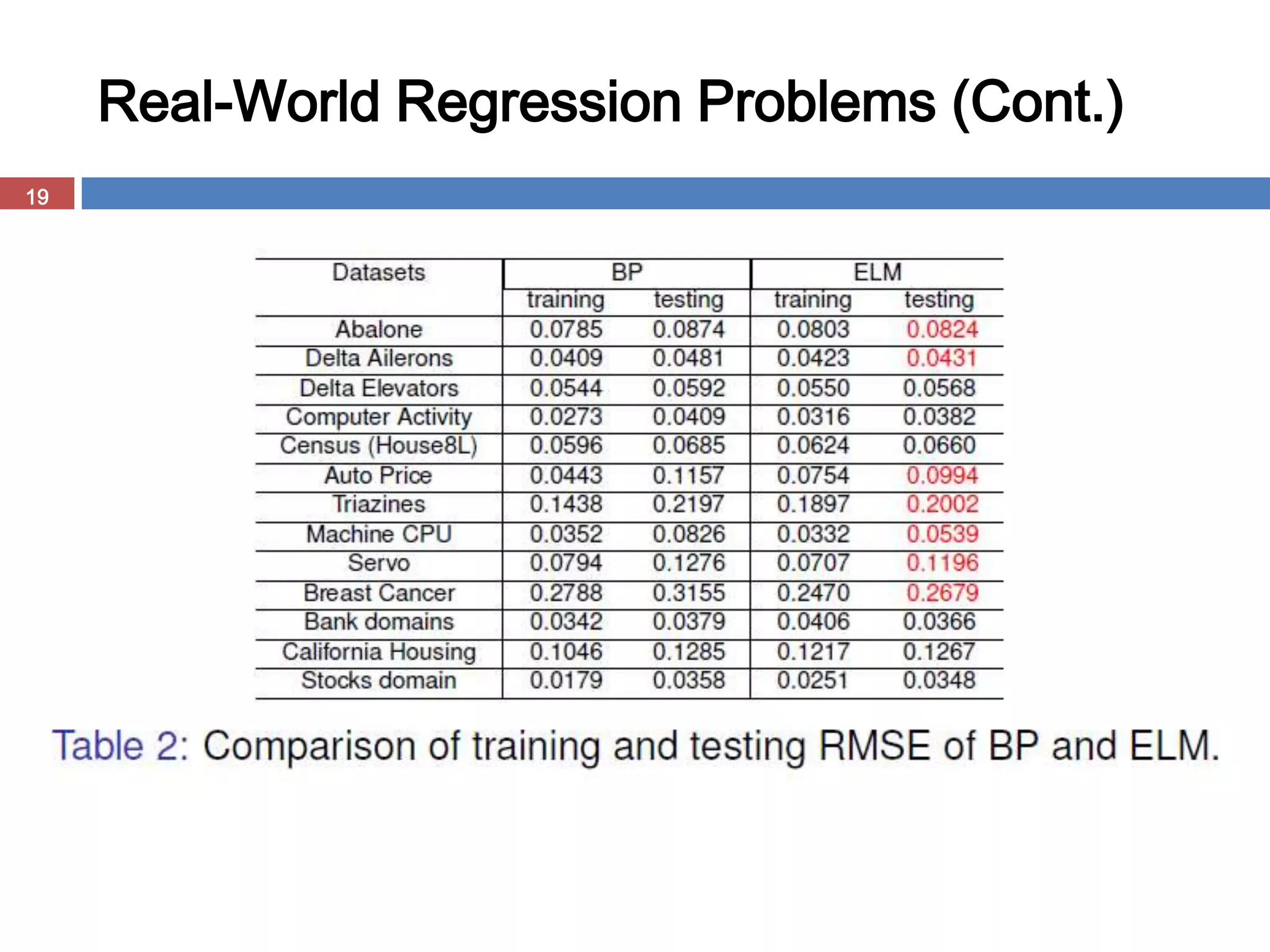
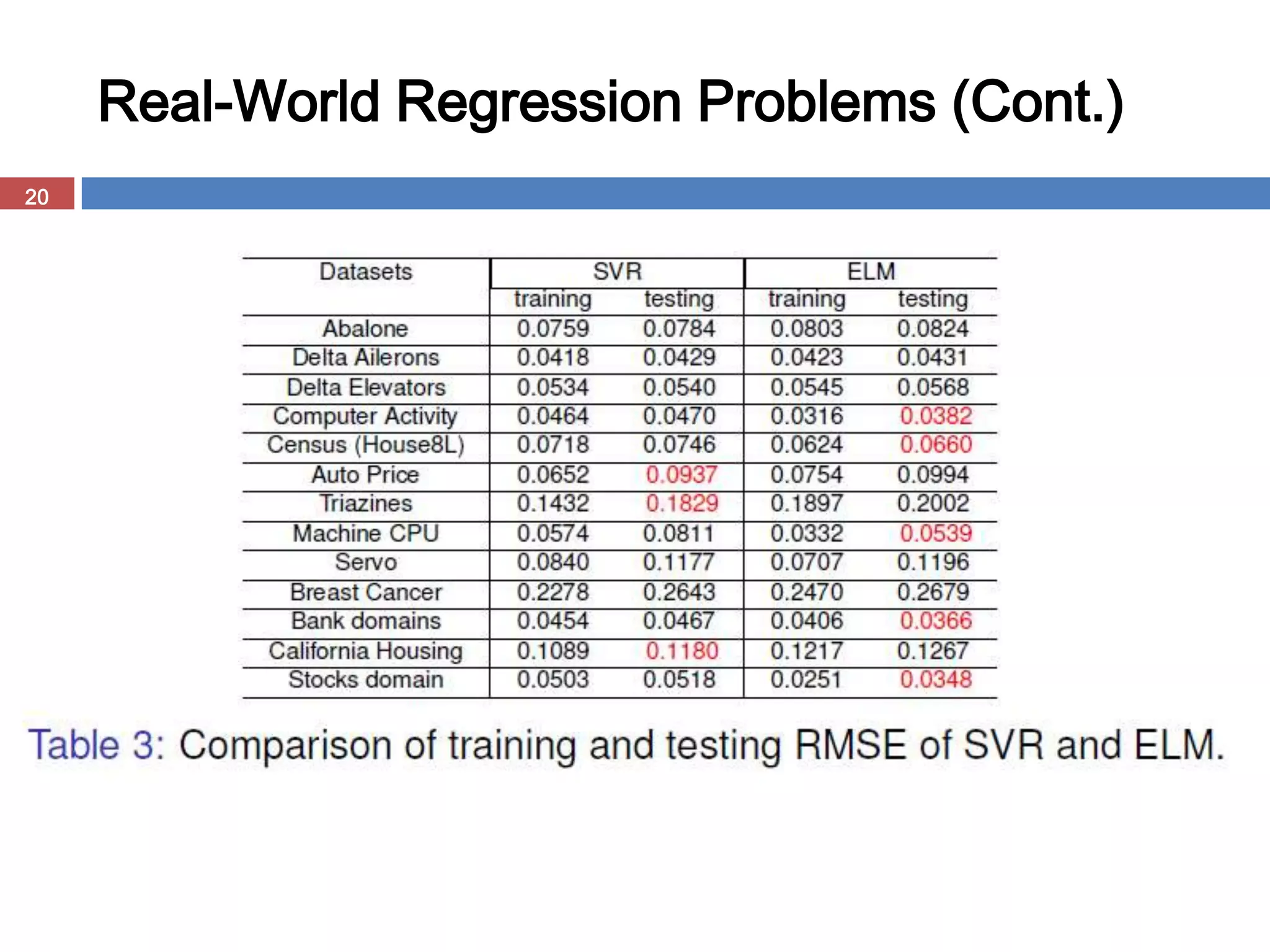
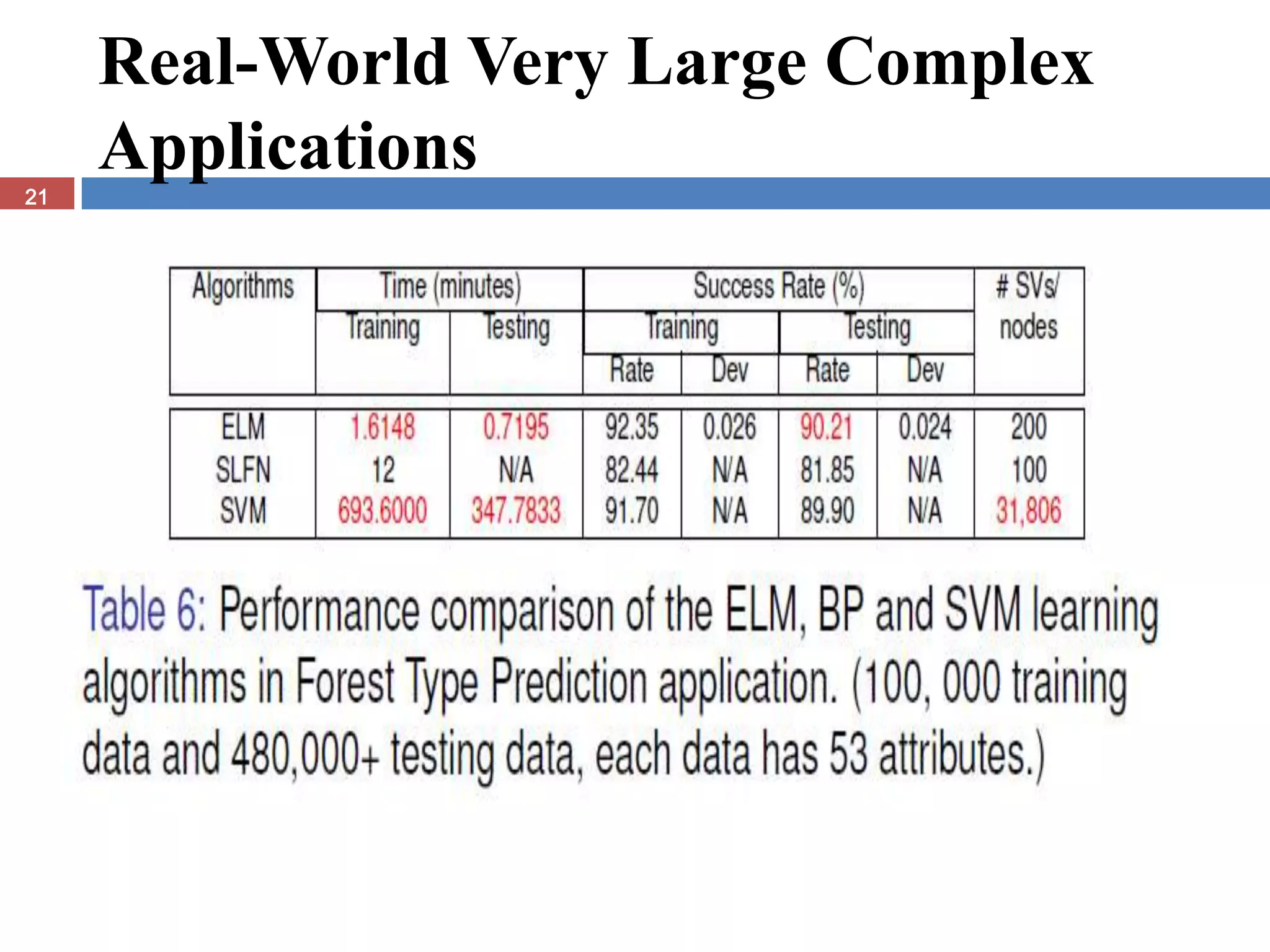
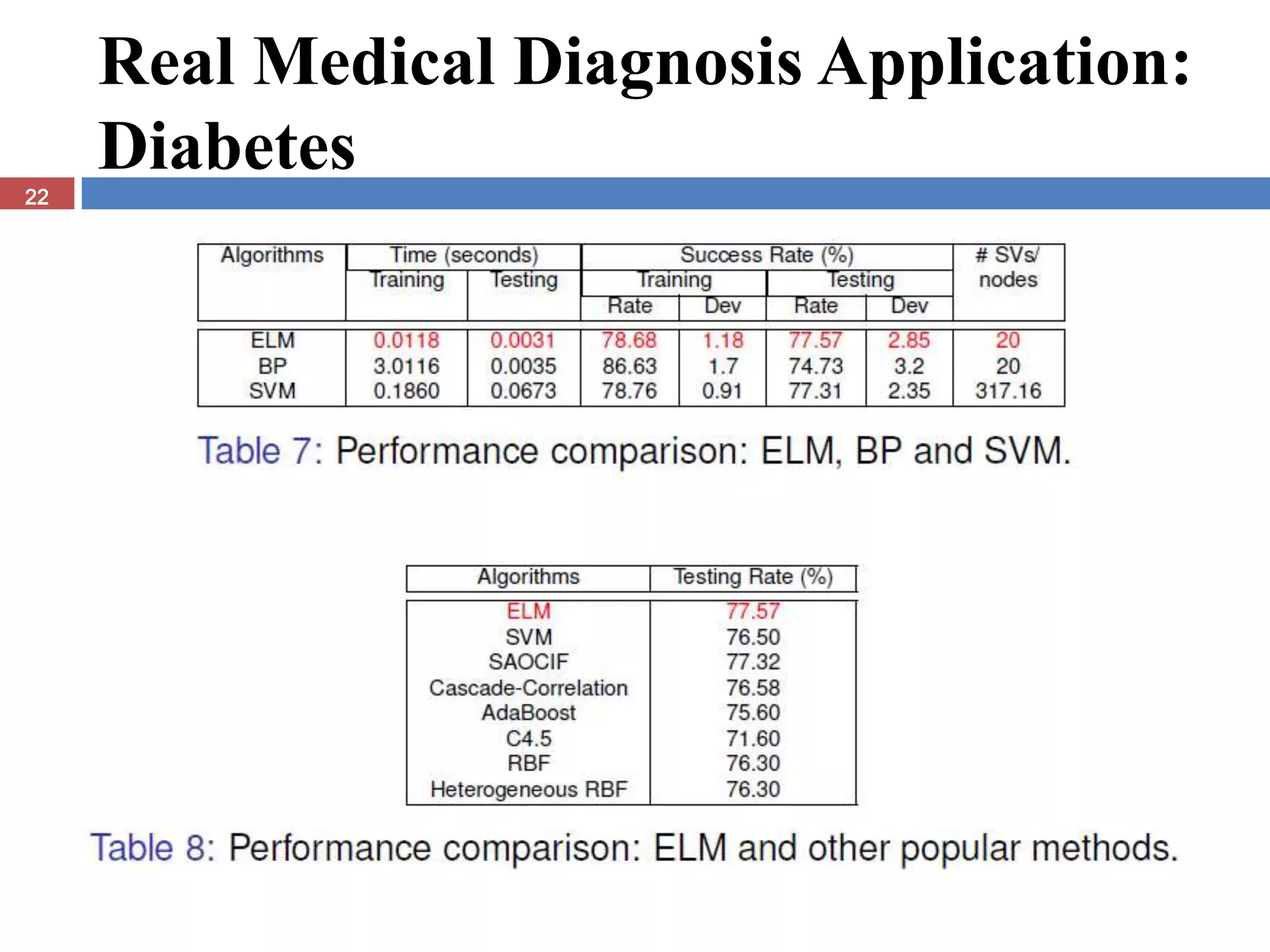
The document presents the extreme learning machine (ELM) theory and algorithm. ELM is a learning algorithm for single-hidden layer feedforward neural networks. Unlike traditional algorithms, ELM assigns input weights and hidden biases randomly and computes output weights through Moore-Penrose generalized inverse, making it faster than backpropagation. The paper evaluates ELM on regression and classification tasks, finding it achieves comparable or better performance than other algorithms while requiring less training time.
































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)