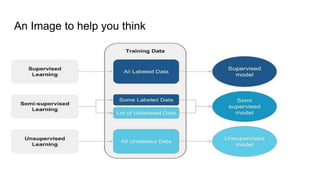
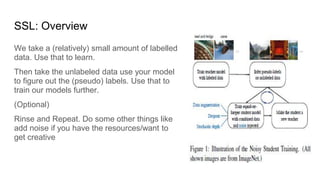
The document discusses semi-supervised learning, which combines labeled and unlabeled data to enhance learning efficiency while minimizing expensive labeling costs. It outlines the key assumptions of semi-supervised learning, including continuity, cluster, and manifold assumptions, and compares the method to human learning processes. The document aims to provide insights into leveraging the strengths of both supervised and unsupervised learning for better model training.


















































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)






