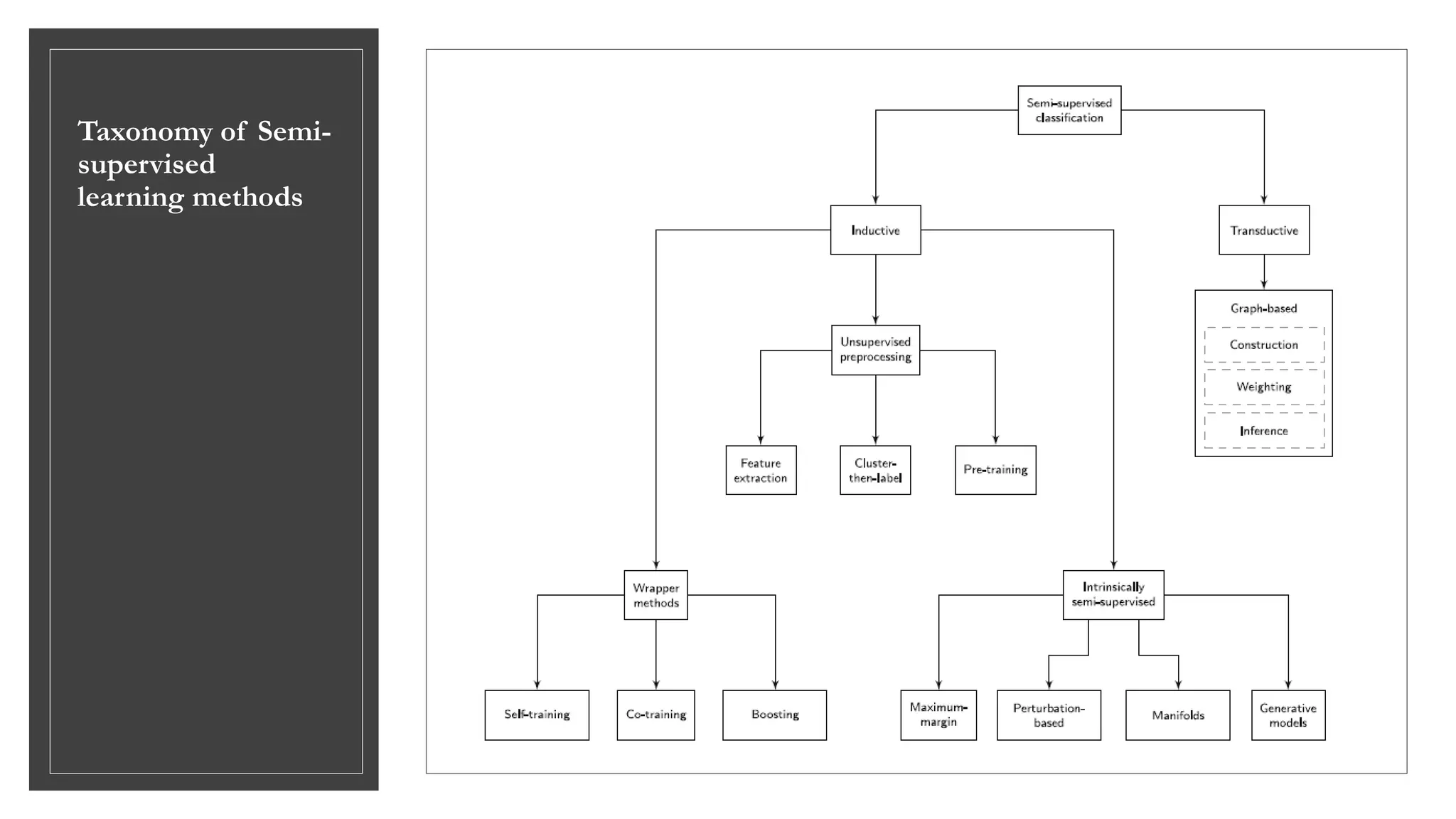
The document is a comprehensive survey on semi-supervised learning, detailing its basic concepts, assumptions, taxonomy of methods, and future research directions. It explains the blend of supervised and unsupervised learning, emphasizing the value of unlabeled data to improve model performance. The paper highlights various inductive and transductive methods while addressing challenges and potential advancements in the field, such as integrating automated machine learning techniques and fostering connections between clustering and classification.