Download as PDF, PPTX




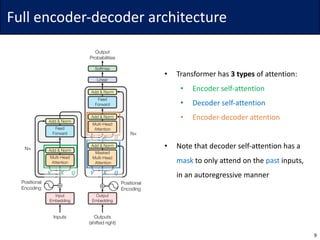



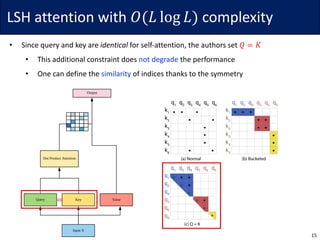
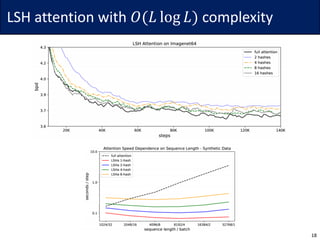
![LSH attention with 𝑂(𝐿 log 𝐿) complexity
16
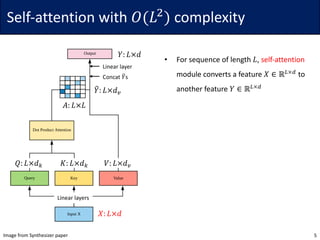
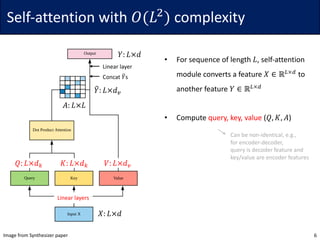
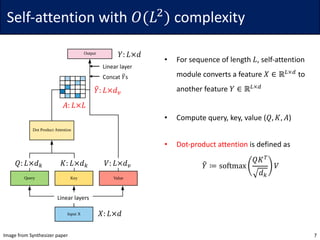
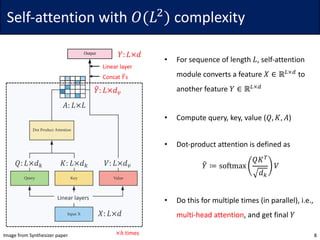
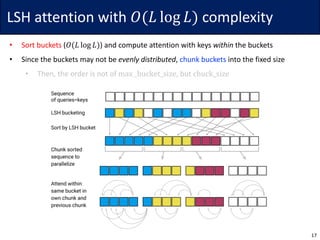
• Idea: For each query 𝑞G, consider only the closest subset of keys
• Since softmax is dominated by the largest elements, it may be sufficient
• To find the nearest neighbors, the authors use locally sensitive hashing (LSH)
• The hash function ℎ maps similar vector 𝑥 to similar bucket ℎ 𝑥 ∈ {0, … , 𝑏 − 1}
• The vectors should be evenly distributed, i.e., the size of buckets should be similar
• Define ℎ 𝑥 = arg max([𝑥𝑅; −𝑥𝑅]) for a (fixed) random matrix 𝑅 ∈ ℝ7V×W/$
Andoni et al. Practical and optimal LSH for angular distance. NeurIPS 2015.](https://image.slidesharecdn.com/200624linformer-200624160338/85/Self-Attention-with-Linear-Complexity-16-320.jpg)
















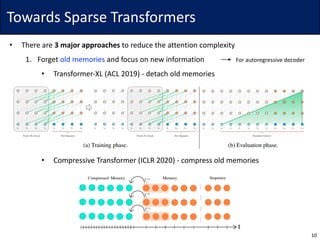
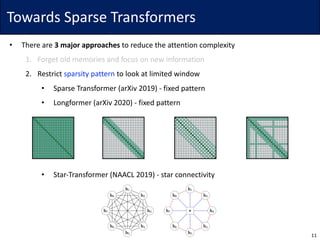
![Universal approx. for sparse Transformers
• Definition. Let {𝒜.
“
} be a sparsity pattern of 𝑘-th token for 𝑙 ∈ 𝑝 ≔ {1,2, … , 𝑝}
• Dense Transformer: 𝑝 = 1, 𝒜.
}
= [𝑛] for all 𝑘 ∈ [𝑛]
• Theorem 3. If sparsity pattern satisfies the following:
• it can approximate any continuous seq2seq function (in compact domain)
• Proof sketch:
• Due to the assumption, every index
can be connected as the layer goes
39](https://image.slidesharecdn.com/200624linformer-200624160338/85/Self-Attention-with-Linear-Complexity-39-320.jpg)




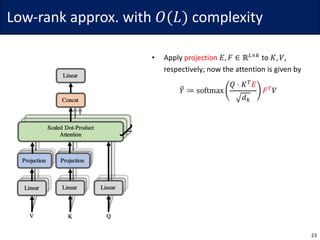
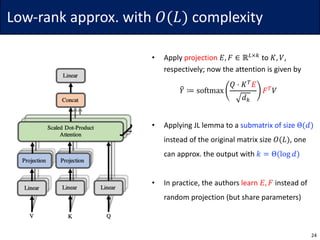
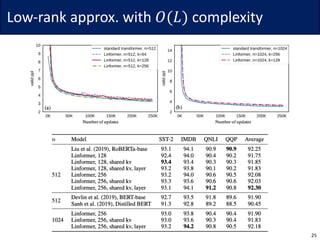
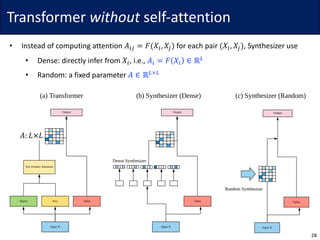
This document summarizes research on reducing the computational complexity of self-attention in Transformer models from O(L2) to O(L log L) or O(L). It describes the Reformer model which uses locality-sensitive hashing to achieve O(L log L) complexity, the Linformer model which uses low-rank approximations and random projections to achieve O(L) complexity, and the Synthesizer model which replaces self-attention with dense or random attention. It also briefly discusses the expressive power of sparse Transformer models.







![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Dl輪読会]dl hacks輪読](https://cdn.slidesharecdn.com/ss_thumbnails/dldlhacks-161125051944-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)










![240318_JW_labseminar[Attention Is All You Need].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240318jwlabseminartransformer-240409103857-bb3838b7-thumbnail.jpg?width=640&height=640&fit=bounds)

















































