Downloaded 60 times





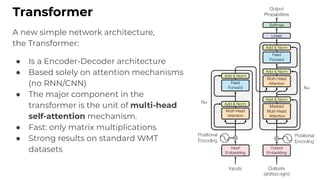
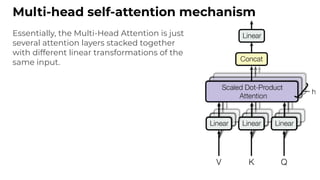
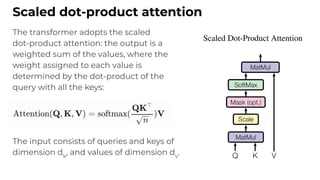
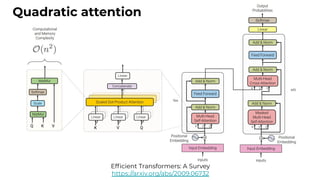




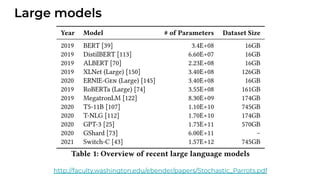

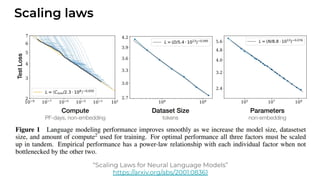











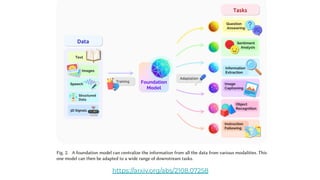



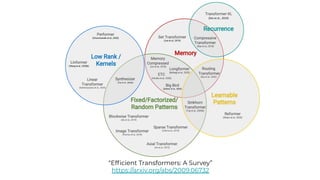

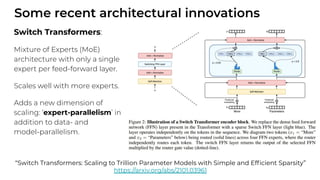
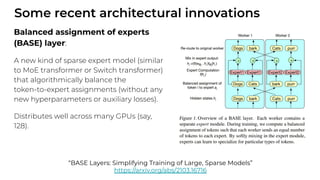
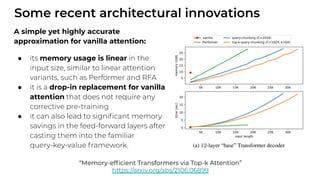
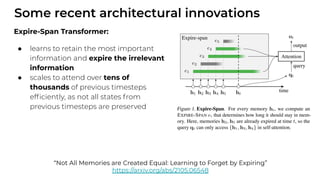


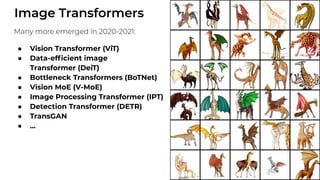
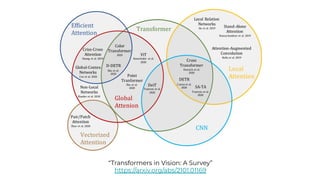
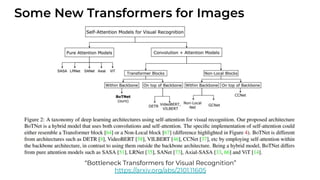
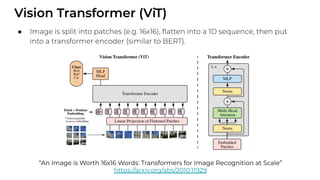
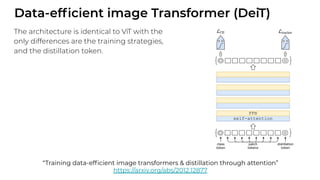
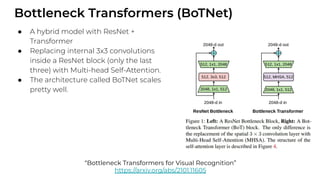
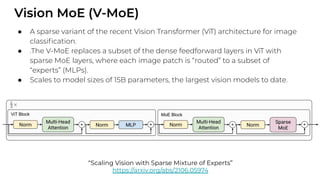

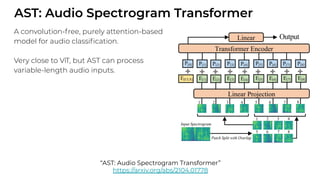

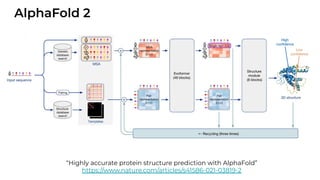
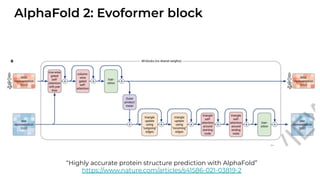

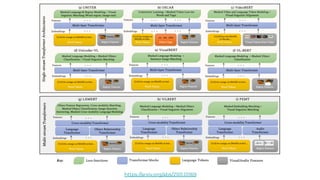

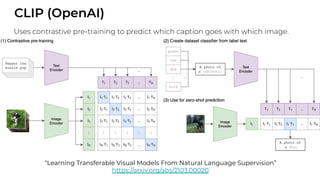
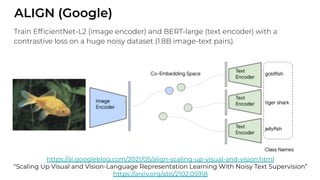

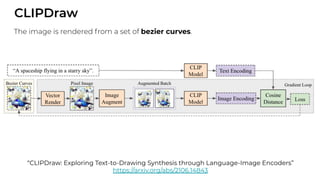


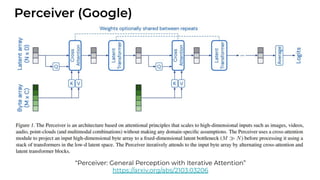
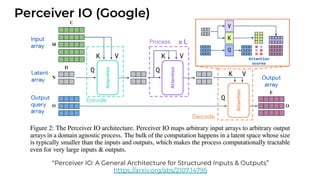


1. The document discusses recent developments in transformer architectures in 2021. It covers large transformers with models of over 100 billion parameters, efficient transformers that aim to address the quadratic attention problem, and new modalities like image, audio and graph transformers. 2. Issues with large models include high costs of training, carbon emissions, potential biases, and static training data not reflecting changing social views. Efficient transformers use techniques like mixture of experts, linear attention approximations, and selective memory to improve scalability. 3. New modalities of transformers in 2021 include vision transformers applied to images and audio transformers for processing sound. Multimodal transformers aim to combine multiple modalities.


















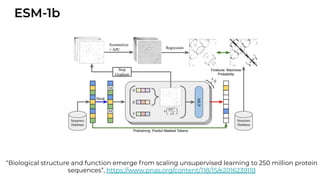
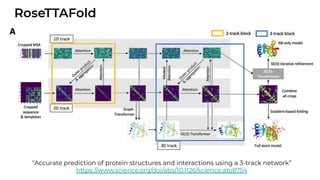
![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)






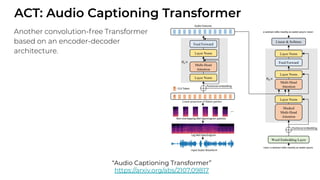
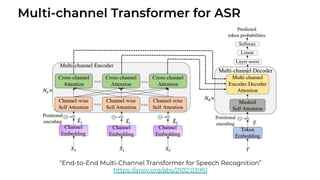
![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)
























![Artificial Intelligence (lecture for schoolchildren) [rus]](https://cdn.slidesharecdn.com/ss_thumbnails/artificialintelligencelectureforschoolchildrenrus-200823192321-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















