Download as PDF, PPTX






![Background
• Bayesian Interpretation for MAML2
• MAML can be viewed as an hierarchical Bayesian model
with global variable 𝜃 and local variables 𝜙𝑗(= 𝜃𝑗)
• To compute marginal likelihood 𝑝 𝑋 𝜃 , one need to compute integral ∫ 𝑝(𝜙𝑗|𝜃)
• For example, using a point (MAP) estimate 𝜙𝑗 (computed by the inner loop)
recovers the original MAML objective
• [2] propose to use a Laplace approximation
which allows to measure the uncertainty and improves the performance
82. Grant et al. Recasting Gradient-Based Meta-Learning as Hierarchical Bayes. ICLR 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-8-320.jpg)
![Background
• Bayesian Interpretation for MAML2
• [2] propose to use a Laplace approximation
which allows to measure the uncertainty and improves the performance
92. Grant et al. Recasting Gradient-Based Meta-Learning as Hierarchical Bayes. ICLR 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-9-320.jpg)
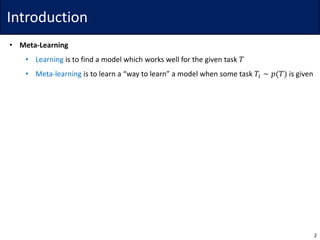
![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Instead of approximating 𝑝(𝜙𝑗|𝜃) with tractable form, simply sampling from
• Here, the sampled 𝜙𝑗s should be differentiable
103. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-10-320.jpg)
![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Instead of approximating 𝑝(𝜙𝑗|𝜃) with tractable form, simply sampling from
• Here, the sampled 𝜙𝑗s should be differentiable
• Idea: Use Stein Variational Gradient Descent (SVGD)*
11
3. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.
* One can use any gradient-based MCMC algorithms (e.g., SGLD or SGHMC), but SVGD is deterministic and adapt faster.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-11-320.jpg)




![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Instead of approximating 𝑝(𝜙𝑗|𝜃) with tractable form, simply sampling from
• Idea: Use Stein Variational Gradient Descent (SVGD)
• Learn a task-specific posterior Θ 𝜏 with SVGD (start from the prior Θ0)*
• Meta-update for Θ0 is given by the mean of val. likelihoods of 𝑀 particles
• Cf. To reduce complexity, all particles share parameters all but the last linear layer
16
3. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.
* Both Θ0 and Θ 𝜏 are given by 𝑀 particles.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-16-320.jpg)
![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Idea 1: Use Stein Variational Gradient Descent (SVGD)
• Learn a task-specific posterior Θ 𝜏 with SVGD (start from the prior Θ0)
• Meta-update for Θ0 is given by the mean of val. likelihoods of 𝑀 particles
• However, this meta-update it not Bayesian inference
• Same as MAML, minimizes empirical loss on task-validation sets (but ensembled)
• It is numerically unstable (task-validation likelihoods) and easily overfitted
173. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-17-320.jpg)
![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Idea 1: Use Stein Variational Gradient Descent (SVGD)
• Learn a task-specific posterior Θ 𝜏 with SVGD (start from the prior Θ0)
• Meta-update for Θ0 is given by the mean of val. likelihoods of 𝑀 particles
• However, this meta-update it not Bayesian inference
• Same as MAML, minimizes empirical loss on task-validation sets (but ensembled)
• It is numerically unstable (task-validation likelihoods) and easily overfitted
• Instead, [3] propose a new meta-update algorithm in Bayesian scheme
183. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-18-320.jpg)
![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Idea 1: Use Stein Variational Gradient Descent (SVGD)
• Idea 2: New meta-update algorithm (coined chaser loss) for Bayesian setting
• Directly minimize the distance between task-train posterior 𝑝𝜏
𝑛
and true posterior 𝑝𝜏
∞
193. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-19-320.jpg)
![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Idea 1: Use Stein Variational Gradient Descent (SVGD)
• Idea 2: New meta-update algorithm (coined chaser loss) for Bayesian setting
• Directly minimize the distance between task-train posterior 𝑝𝜏
𝑛
and true posterior 𝑝𝜏
∞
• However, the problem is that one does not know the true posterior 𝑝𝜏
∞
203. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-20-320.jpg)
![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Idea 1: Use Stein Variational Gradient Descent (SVGD)
• Idea 2: New meta-update algorithm (coined chaser loss) for Bayesian setting
• Directly minimize the distance between task-train posterior 𝑝𝜏
𝑛
and true posterior 𝑝𝜏
∞
• However, the problem is that one does not know the true posterior 𝑝𝜏
∞
• Hence, [3] approximates 𝑝𝜏
∞
with 𝑝𝜏
𝑛+𝑠
, updated by both task-train & task-validation data
• Here, 𝑝𝜏
𝑛+𝑠
(both train & val) is the leader, and 𝑝𝜏
𝑛
(train only) is the chaser
213. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-21-320.jpg)
![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Idea 1: Use Stein Variational Gradient Descent (SVGD)
• Idea 2: New meta-update algorithm (coined chaser loss) for Bayesian setting
• Directly minimize the distance between task-train posterior 𝑝𝜏
𝑛
and true posterior 𝑝𝜏
∞
• [3] approximates 𝑝𝜏
∞
with 𝑝𝜏
𝑛+𝑠
, updated by both task-train & task-validation data
• Q. How to compute the distance between 𝑝𝜏
𝑛+𝑠
and 𝑝𝜏
𝑛
?
223. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-22-320.jpg)
![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Idea 1: Use Stein Variational Gradient Descent (SVGD)
• Idea 2: New meta-update algorithm (coined chaser loss) for Bayesian setting
• Directly minimize the distance between task-train posterior 𝑝𝜏
𝑛
and true posterior 𝑝𝜏
∞
• [3] approximates 𝑝𝜏
∞
with 𝑝𝜏
𝑛+𝑠
, updated by both task-train & task-validation data
• Q. How to compute the distance between 𝑝𝜏
𝑛+𝑠
and 𝑝𝜏
𝑛
?
• Since both posteriors are given by finite particles, one can simply find a one-to-one
mapping, and minimize the pairwise 𝑙2 distance
233. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-23-320.jpg)
![Method
• Bayesian Model-Agnostic Meta-Learning (BMAML)3
• Can one extend [2] to more complex Bayesian neural network?
• Idea 1: Use Stein Variational Gradient Descent (SVGD)
• Idea 2: New meta-update algorithm (coined chaser loss) for Bayesian setting
• [3] approximates 𝑝𝜏
∞
with 𝑝𝜏
𝑛+𝑠
, updated by both task-train & task-validation data
• For posterior distance, simply minimize the pairwise 𝑙2 distance
243. Kim et al. Bayesian Model-Agnostic Meta-Learning. NeurIPS 2018.](https://image.slidesharecdn.com/190102bmaml-190102062703/85/Bayesian-Model-Agnostic-Meta-Learning-24-320.jpg)

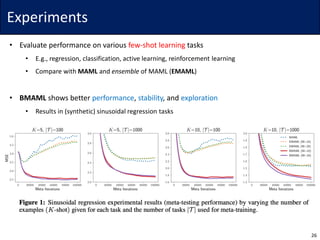
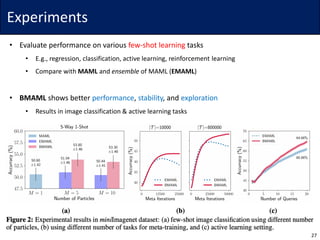
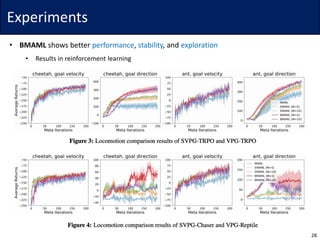


The document discusses Bayesian Model-Agnostic Meta-Learning (BMAML) and its relationship with Model-Agnostic Meta-Learning (MAML), introducing techniques like Stein Variational Gradient Descent (SVGD) for improved performance. It presents a new meta-update method called 'chaser loss' to minimize the distance between task-training and true posteriors, which enhances performance in few-shot learning tasks. Empirical results demonstrate that BMAML outperforms traditional MAML methods in various applications, including regression, classification, and reinforcement learning.


















![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DL輪読会]Understanding Measures of Uncertainty for Adversarial Example Detection](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180406-180406002929-thumbnail.jpg?width=640&height=640&fit=bounds)














































