Downloaded 77 times









![Error Functions
(Cost function or Lost Function)
• There are many formulates for error functions.
• In this course, we will deal with two Error function
formulas.
Sum Squared Error (SSE) :
𝑒 𝑝𝑗 = 𝑦𝑗 − 𝐷𝑗
2
for single perceptron
𝐸𝑆𝑆𝐸=
𝑗=1
𝑛
𝑦𝑗 − 𝐷𝑗
2
1
Cross entropy (CE):
𝐸 𝐶𝐸 =
1
𝑛 𝑗=1
𝑛
[𝐷𝑗 ∗ ln(𝑦𝑗) + (1− 𝐷𝑗) ∗ ln(1− 𝑦𝑗)] (2)
10
1
2](https://image.slidesharecdn.com/04mlffnetworks-180317131121/85/04-Multi-layer-Feedforward-Networks-10-320.jpg)




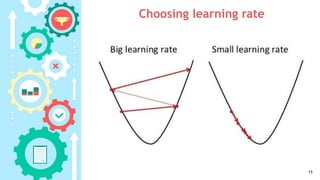







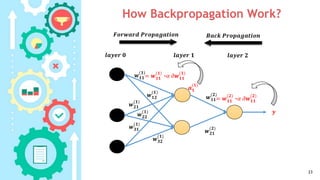





This document provides an outline for a course on neural networks and fuzzy systems. The course is divided into two parts, with the first 11 weeks covering neural networks topics like multi-layer feedforward networks, backpropagation, and gradient descent. The document explains that multi-layer networks are needed to solve nonlinear problems by dividing the problem space into smaller linear regions. It also provides notation for multi-layer networks and shows how backpropagation works to calculate weight updates for each layer.


































































