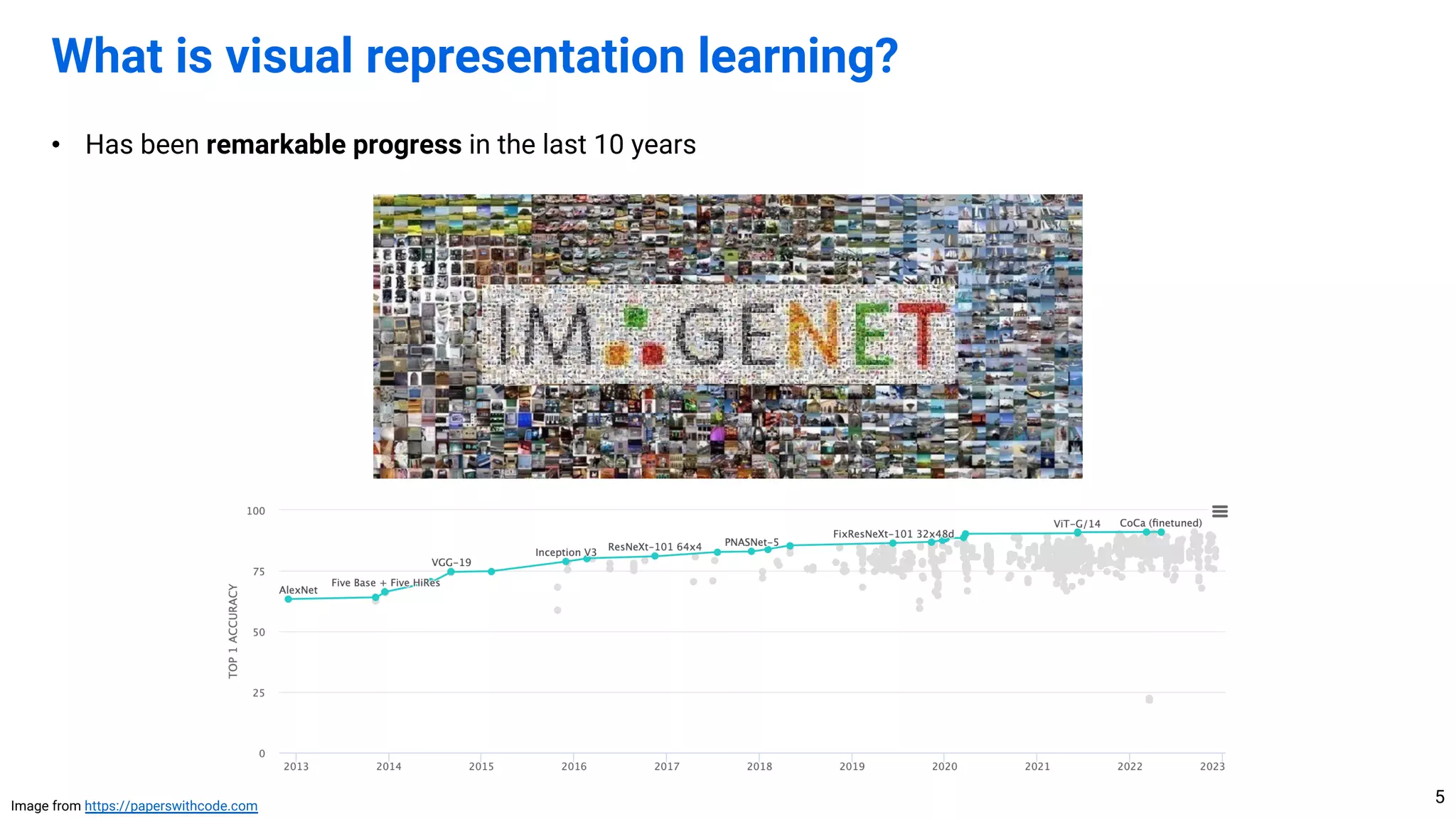
Download to read offline

![• [2012-2015] Evolution of deep learning architectures
• [2016-2019] Learning paradigms for diverse tasks
• [2020-current] Scaling laws and foundation models
Outline of the talk
2
Caveat: These eras are not mutually exclusive](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-2-2048.jpg)


![6
[2012-2015] Evolution of deep learning architectures](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-6-2048.jpg)
![• 2012: AlexNet opened the era of deep learning for computer vision
• Significantly outperforms the shallow competitors
[2012-2015] Evolution of deep learning architectures
7
Image from https://www.pinecone.io/learn/series/image-search/imagenet/](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-7-2048.jpg)
![• 2013-: Golden era for architecture design
• 2013 ZFNet, 2014 VGG-Net and GoogLeNet
[2012-2015] Evolution of deep learning architectures
8
Image from https://devopedia.org/imagenet](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-8-2048.jpg)
![• 2015: ResNet exceeded human performance – skip connection is the key to success!
• ResNet is still actively used in 2023 (though SOTA is ViT families)
[2012-2015] Evolution of deep learning architectures
9
Image from https://devopedia.org/imagenet](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-9-2048.jpg)
![• 2015: BatchNorm opened the exploration of normalization layers
• Reparameterization facilitates ease of optimization1
• (Side note) BatchNorm was essential in early ConvNet, but has some side effects (e.g., adversarially venerable)
Recent architectures like ViT and ConvNeXt use LayerNorm instead
[2012-2015] Evolution of deep learning architectures
10
1. See “How Does Batch Normalization Help Optimization?” (2018)](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-10-2048.jpg)
![• What happened after 2015?
• New architectures are still being proposed (2016 WideResNet, 2017 ResNeXt and DenseNet, etc.)
• However, the interests of the community have moved beyond ImageNet (challenge ended in 2017)
• Instead, researchers explored diverse tasks and learning paradigms in 2016-
• Few-shot learning, continual learning, domain adaptation, etc.
[2012-2015] Evolution of deep learning architectures
11
Images from https://www.youtube.com/watch?v=hE7eGew4eeg and https://mila.quebec/en/article/la-maml-look-ahead-meta-learning-for-continual-learning/](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-11-2048.jpg)
![• (Side note) Architectures after 2015
• Convolutional: 2016 WideResNet, 2017 ResNeXt and DenseNet
• Convolutional + attention: 2018 SENet and CBAM – Inspired by 2017 Transformer (self-attention)
• Some automated designs using neural architecture search (NAS) – 2017 NAS, 2019 EfficientNet, etc.
• EfficientNet found an architecture that scales well (will be revisited in the “scaling laws” part)
[2012-2015] Evolution of deep learning architectures
12](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-12-2048.jpg)
![• (Side note) Architectures after 2015
• In 2021, Vision Transformer (ViT) changed the landscape, giving a better scaling than ConvNet
• Followed by hybrid models like Swin-T, or patch-based models like MLP-Mixer
• Some folks (e.g., Yann LeCun) still believe convolution is an essential for image recognition
• Currently, there are two philosophies
• Pure ViT: Use vanilla Transformer, same as other modalities like language
• Hybrid model: Combine ConvNet and ViT, specialized to the image modality
• Scaling pure ViT is more popular1 now, but let’s wait for time to tell
[2012-2015] Evolution of deep learning architectures
13
1. See “Scaling Vision Transformers to 22 Billion Parameters” (2023)
vs.](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-13-2048.jpg)
![• (Side note) Architectures beyond classification
• Need specialized modules for image recognition beyond classification (e.g., object detection/segmentation)
• It also had rapid evolution in this era – 2013 R-CNN, 2015 Faster R-CNN, 2017 Mask R-CNN, etc.
• Recent efforts are aimed at simplifying such modules (e.g., 2020 DETR, 2021 MaskFormer),
or even creating a single model that solves all tasks universally (e.g., 2022 pix2seq, 2023 pix2seq-D)
[2012-2015] Evolution of deep learning architectures
14](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-14-2048.jpg)
![15
[2016-2019] Learning paradigms for diverse tasks](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-15-2048.jpg)
![• 2016-2019: Explosion of various tasks and task-wise learning paradigms
• Few-shot learning: 2016 MatchingNet, 2017 ProtoNet, etc.
• Meta learning: 2016 Learn2Learn, 2017 MAML, 2018 NP, etc.
• Continual learning: 2016 ProgressiveNet and LwF, 2017 EWC, etc.
• Self-supervised learning: 2016 Jigsaw and Colorization, 2018 RotNet, etc.
• Semi-supervised learning: 2015 VAT, 2017 Temporal Ensemble 2018 Mean Teacher, etc.
• Domain adaptation: 2015 DAN and DANN, 2016 RTN, 2017 ADDA, etc.
• Knowledge distillation: 2014 KD and FitNet, 2017 Attention Transfer, etc.
• Data imbalance: 2017 Focal Loss, 2018 Learn2Reweight, etc.
• Noisy labels: 2017 Decouple, 2018 MentorNet and Co-teaching, etc.
• …but not limited to (e.g., {zero-shot, multi-task, active} learning, domain generalization)
[2016-2019] Learning paradigms for diverse tasks
16](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-16-2048.jpg)
![• 2019: Big Transfer (BiT), or “Is a good backbone is all you need?”
• Large model + big data = universally good performance on diverse tasks
• Performs well for transfer and few-shot settings (no specialized method is needed)
[2016-2019] Learning paradigms for diverse tasks
17](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-17-2048.jpg)
![• How to train the backbone?
• Supervised training (e.g., use JFT-300M) – 2017
• Weakly-supervised training (e.g., use Instagram-1B) – 2018
• + Self-training (noisy student) to boost performance – 2020
• …however, collecting (weakly-)supervised data is expensive!
→ 2020-: Use large-scale unlabeled data by self-supervised learning
• (+1) The backbone trained by self-sup is robust to data imbalance and noisy labels
[2016-2019] Learning paradigms for diverse tasks
18
Cherry (RL) – e.g., RLHF
Icing (sup) – e.g., instruction fine-tuning
Cake (self-sup)1 – e.g., language modeling
1. Yann LeCun’s cake analogy](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-18-2048.jpg)
![19
[2020-current] Scaling laws and foundation models](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-19-2048.jpg)
![• 2019: EfficientNet and BiT suggests the scaling laws for computer vision (similar to NLP1)
• Larger model, bigger data, and more compute give consistent performance gains
• In NLP, they use Transformer model and language modeling self-supervision to scale model and data
→ How to design computer vision models and data to be scaled effectively?
[2020-current] Scaling laws and foundation models
20
See “Scaling Laws for Neural Language Models” (2020)](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-20-2048.jpg)
![• 2020: MoCo and SimCLR open the era of self-supervised learning (joint embedding method)
• Create two views (e.g., by data augmentation) of an unlabeled data and make their features similar
• Originally called contrastive learning, but followed up by non-contrastive methods like SwAV and BYOL
• Limitation: It enables data scaling, but performance saturates since ConvNet does not scale well
[2020-current] Scaling laws and foundation models
21
Image from http://aidev.co.kr/deeplearning/8968](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-21-2048.jpg)
![• 2021: Vision Transformer (ViT) scales better than ConvNet in a supervised setup (further scale up1,2
)
• Divide an image into patches and treat them as tokens (or words) of a Transformer
• Hope: ViT shows a new potential of model scaling in computer vision, and could be combined with self-sup?
[2020-current] Scaling laws and foundation models
22
1. “Scaling Vision Transformers” (2022)
2. “Scaling Vision Transformers to 22 Billion Parameters” (2023)](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-22-2048.jpg)
![• 2021: DINO and MoCo-v3 combines joint embedding method and ViT
• It works okay, and provides nice properties, such as unsupervised object discovery from attention
• Limitation: However, joint embedding for ViT does not scale well, unlike supervised learning
[2020-current] Scaling laws and foundation models
23](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-23-2048.jpg)
![• 2022: Masked Autoencoder (MAE)1 offers a new self-supervision for scaling ViT (and other nets2,3
)
• Masked language modeling (e.g., BERT) scales well in NLP → Apply similar idea to ViT
• Current SOTA: MAE scales well with model size, but not with data size (also reported in MAE-CLIP4)
[2020-current] Scaling laws and foundation models
24
1. Also called masked image modeling (MIM)
2. “ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders” (2023)
3. “Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles” (2023)
4. “Masked Autoencoding Does Not Help Natural Language Supervision at Scale” (2023)
MAE is not effective when combined with CLIP
… by the way, what is CLIP? (next page)](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-24-2048.jpg)
![• 2023-: (Learning paradigm) Extension to multimodal models
• In 2021, CLIP suggested an alternative way to train vision encoder using (web-collected) image-text pairs
• The CLIP backbone is generally superior to the self-supervised backbone for natural images
• Next direction: How to scale up CLIP? Can we further harness unlabeled data through self-supervision?
• LAION-2B (image-text dataset) is big but still limited compared to unlabeled data
[2020-current] Scaling laws and foundation models
25](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-25-2048.jpg)
![• 2023-: (Learning paradigm) Combination with generative models
• Generative modeling is one natural way for self-supervision – 2014 Semi+VAE, 2019 BigBiGAN, etc.
• Recently, (text-to-image) diffusion models have shown their effectiveness1 in low-level vision understanding
• Next direction: Can we combine diffusion models and representation learning in a single framework?
• Stable Diffusion can be an alternative of (dense) CLIP on learning low-level representations
[2020-current] Scaling laws and foundation models
26
1. See “Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models” for example](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-26-2048.jpg)
![• 2023-: (Architecture design) Towards better scaling laws
• Should we use Pure ViT, or hybrid models (Swin-T, ConvNeXt) that incorporate visual inductive biases?
• In NLP, pure(-like) Transformers have succeeded in scaling up1, while efficient variants have failed2
• Next direction: Check scaling law of vision architectures, matching the scale with large language models (LLMs)
• ViT (22B params) is still much smaller than GPT-4 (1.7T params)
[2020-current] Scaling laws and foundation models
27
1. “Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?” (2022)
2. Recent works claim they can, such as “Retentive Network: A Successor to Transformer for Large Language Models” (2023)](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-27-2048.jpg)
![• Roughly speaking, there are two major topics in visual representation learning
• Architecture design:
• [2012-2015] Evolution of convolutional architectures
• [2016-2020] Attention, NAS, EfficientNet, and scaling laws
• [2021-current] Scaling up ViT and hybrid models (Swin-T, ConvNeXt)
• [Current-] Can ViT (or hybrid models) match the scale of LLM?
• Learning paradigm:
• [2016-2019] Various tasks and task-wise learning paradigms
• [2020-current] Self-supervised and multimodal learning for foundation models
• [Current-] Scale up CLIP (or Diffusion) and combine it with self-supervision?
Summary
28](https://image.slidesharecdn.com/230816history-230813142926-f65b1526/75/Brief-History-of-Visual-Representation-Learning-28-2048.jpg)

The document summarizes the history of visual representation learning in 3 eras: (1) 2012-2015 saw the evolution of deep learning architectures like AlexNet and ResNet; (2) 2016-2019 brought diverse learning paradigms for tasks like few-shot learning and self-supervised learning; (3) 2020-present focuses on scaling laws and foundation models through larger models, data and compute as well as self-supervised methods like MAE and multimodal models like CLIP. The field is now exploring how to scale up vision transformers to match natural language models and better combine self-supervision and generative models.
















![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)




































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
