Download as PDF, PPTX


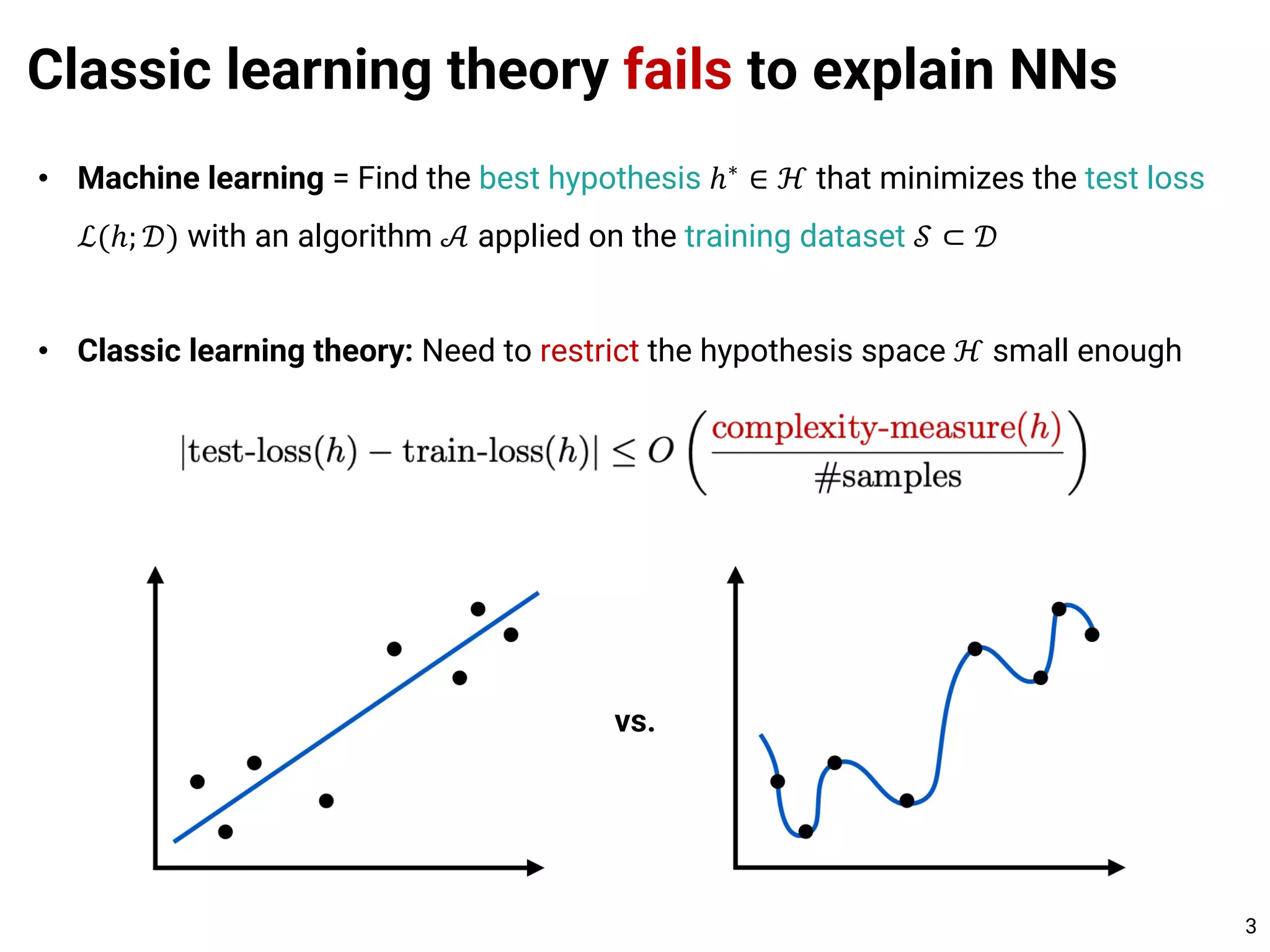

![Classic learning theory fails to explain NNs
5
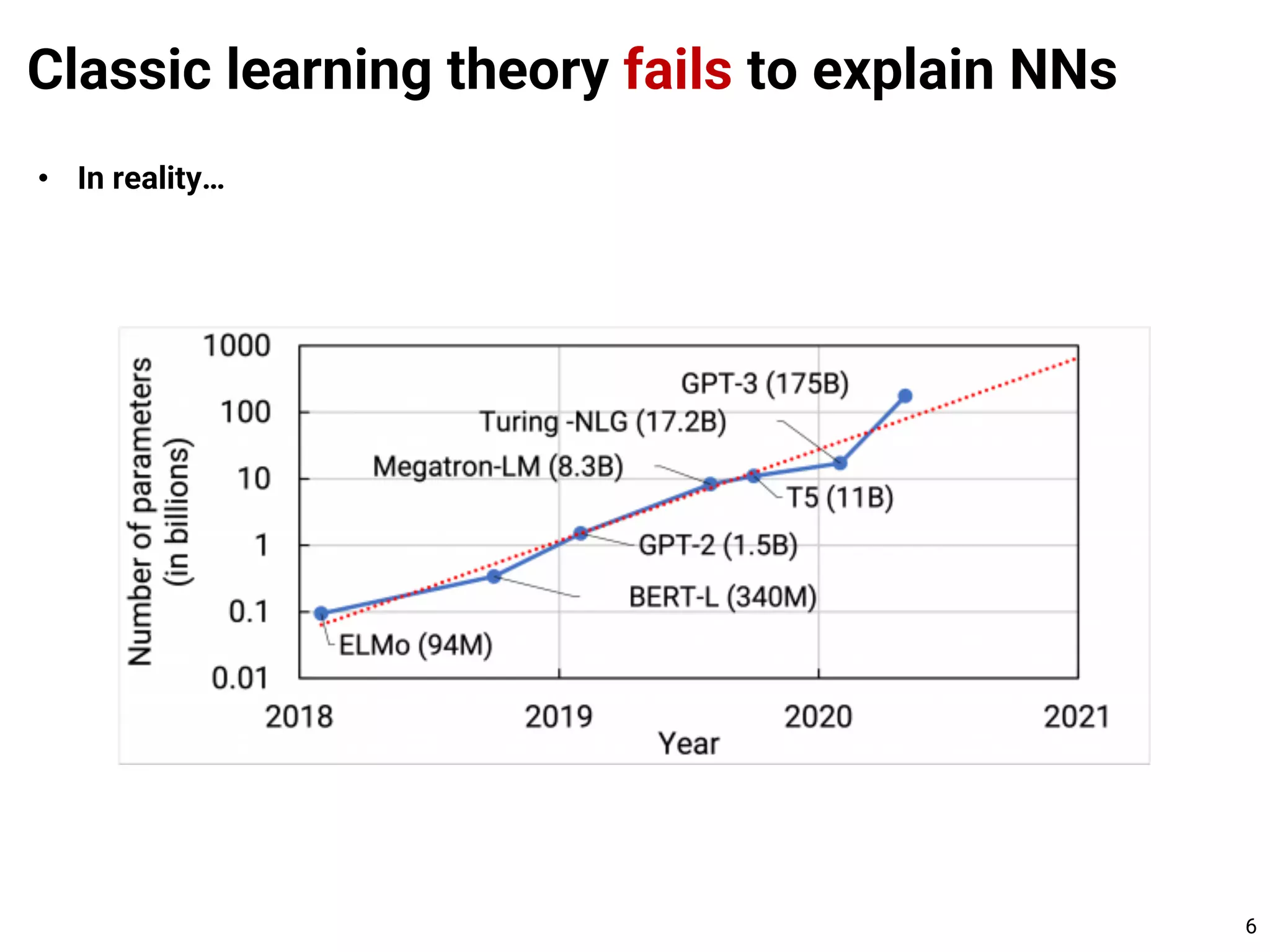
• In reality…
[1] Zhang et al. Understanding deep learning requires rethinking generalization. ICLR 2017.
[2] Nakkiran et al. Deep Double Descent: Where Bigger Models and More Data Hurt. ICLR 2020.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-5-2048.jpg)
![1. The complexity measure 𝑚(ℎ) is not tight
• Compression approach
• There is a smaller model ℎ′ that is almost identical to the original model ℎ
• Then, we consider the tighter complexity measure 𝑚(ℎ!)
Why it happens?
8
[1] Arora et al. Stronger generalization bounds for deep nets via a compression approach. ICML 2018.
[2] Frankle et al. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. ICLR 2019.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-8-2048.jpg)
![1. The complexity measure 𝑚(ℎ) is not tight
• Representation learning approach
• Upon the expressive representation, it suffices to consider the simple classifier
Why it happens?
9
[1] Bansal et al. For self-supervised learning, Rationality implies generalization, provably. ICLR 2021.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-9-2048.jpg)
![2. The algorithm 𝒜 implicitly regularizes the search space .
ℋ ⊂ ℋ
• SGD finds simpler solution
• In overparameterization regime, there are infinitely many solutions
• SGD finds the model with smaller norm & sparser structure
• ⇒ Double descent (more overparameterization = better generalization)
Why it happens?
10
[1] Yun et al. A Unifying View on Implicit Bias in Training Linear Neural Networks. ICLR 2021.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-10-2048.jpg)
![2. The algorithm 𝒜 implicitly regularizes the search space .
ℋ ⊂ ℋ
• SGD finds flat minima
• Perturbation of SGD → escape sharp minima
• Best empirical correlation between theory and practice
Why it happens?
11
[1] Jiang et al. Fantastic Generalization Measures and Where to Find Them. ICLR 2020.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-11-2048.jpg)
![• Optimal perturbation of SGD for flat minima
• Noise scale ∝ LR / batch size (need large LR or small batch size)
• Smaller noise scale (= larger batch size) for harder tasks
Flat minima
12
[1] Keskar et al. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. ICLR 2017.
[2] McCandlish et al. An Empirical Model of Large-Batch Training. arXiv 2018.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-12-2048.jpg)
![• Modern architectures + SGD = Flat minima
• e.g., skip connection, batch normalization
Flat minima
13
[1] Li et al. Visualizing the Loss Landscape of Neural Nets. NeurIPS 2018.
[2] Santurkar et al. How Does Batch Normalization Help Optimization? NeurIPS 2018.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-13-2048.jpg)
![• Modern architectures + SGD = Flat minima
• In fact, the minima are connected by some path
⇒ One can use them for fast ensemble
Flat minima
14
[1] Draxler et al. Essentially No Barriers in Neural Network Energy Landscape. ICML 2018.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-14-2048.jpg)
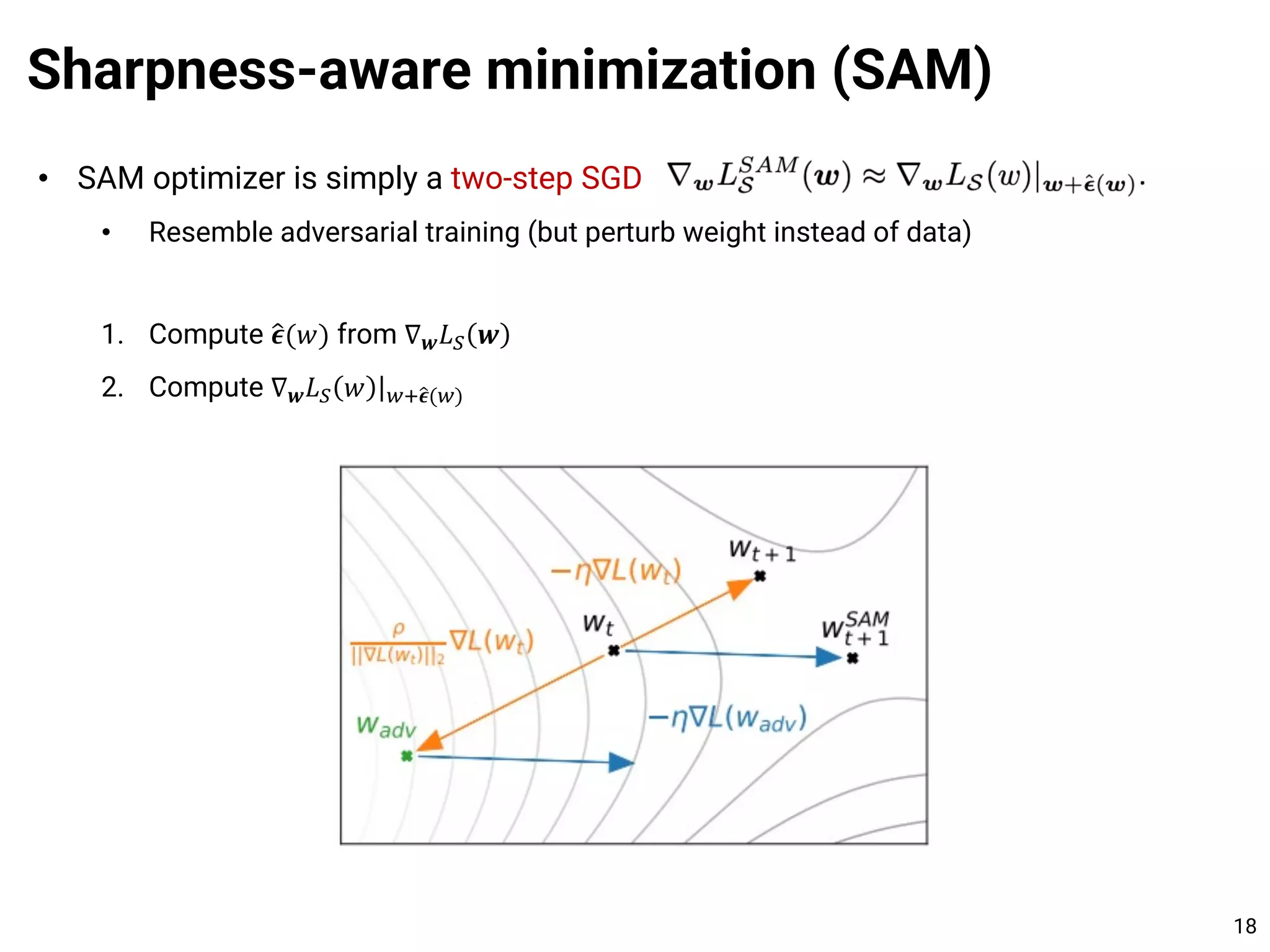
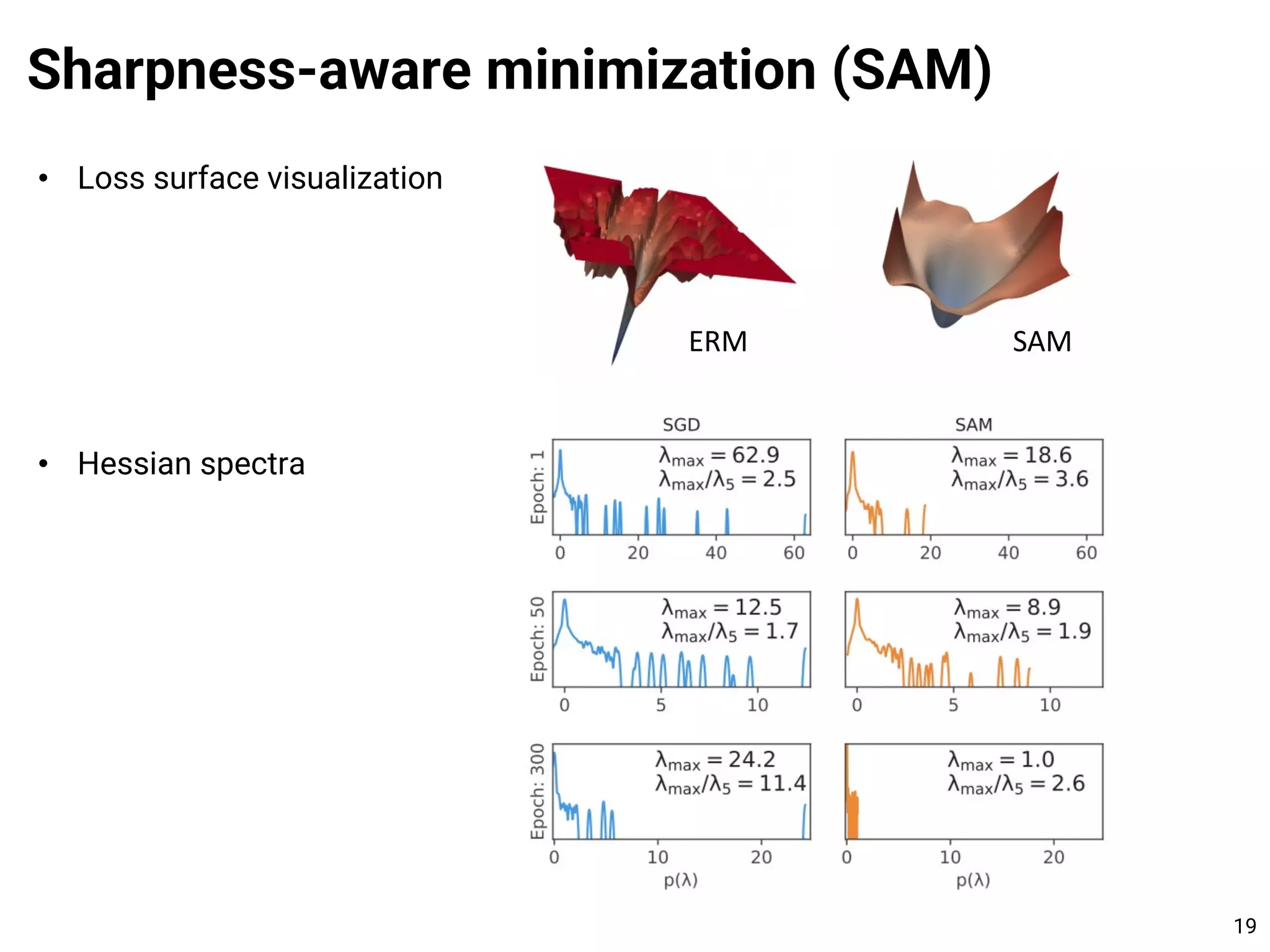
![• Theorem. With high probability, the flatness-based bound says:
Sharpness-aware minimization (SAM)
15
[1] Foret et al. Sharpness-Aware Minimization for Efficiently Improving Generalization. ICLR 2021.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-15-2048.jpg)
![• Theorem. With high probability, the flatness-based bound says:
• SAM minimizes the minimax objective
• With 1st order Taylor approximation,
Sharpness-aware minimization (SAM)
16
[1] Foret et al. Sharpness-Aware Minimization for Efficiently Improving Generalization. ICLR 2021.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-16-2048.jpg)
![• Theorem. With high probability, the flatness-based bound says:
• SAM minimizes the minimax objective
• With 1st order Taylor approximation,
• By substituting ̂
𝜖(𝒘), the gradient estimator of SAM is
or simply,
Sharpness-aware minimization (SAM)
17
2nd order term is not necessary in practice
[1] Foret et al. Sharpness-Aware Minimization for Efficiently Improving Generalization. ICLR 2021.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-17-2048.jpg)
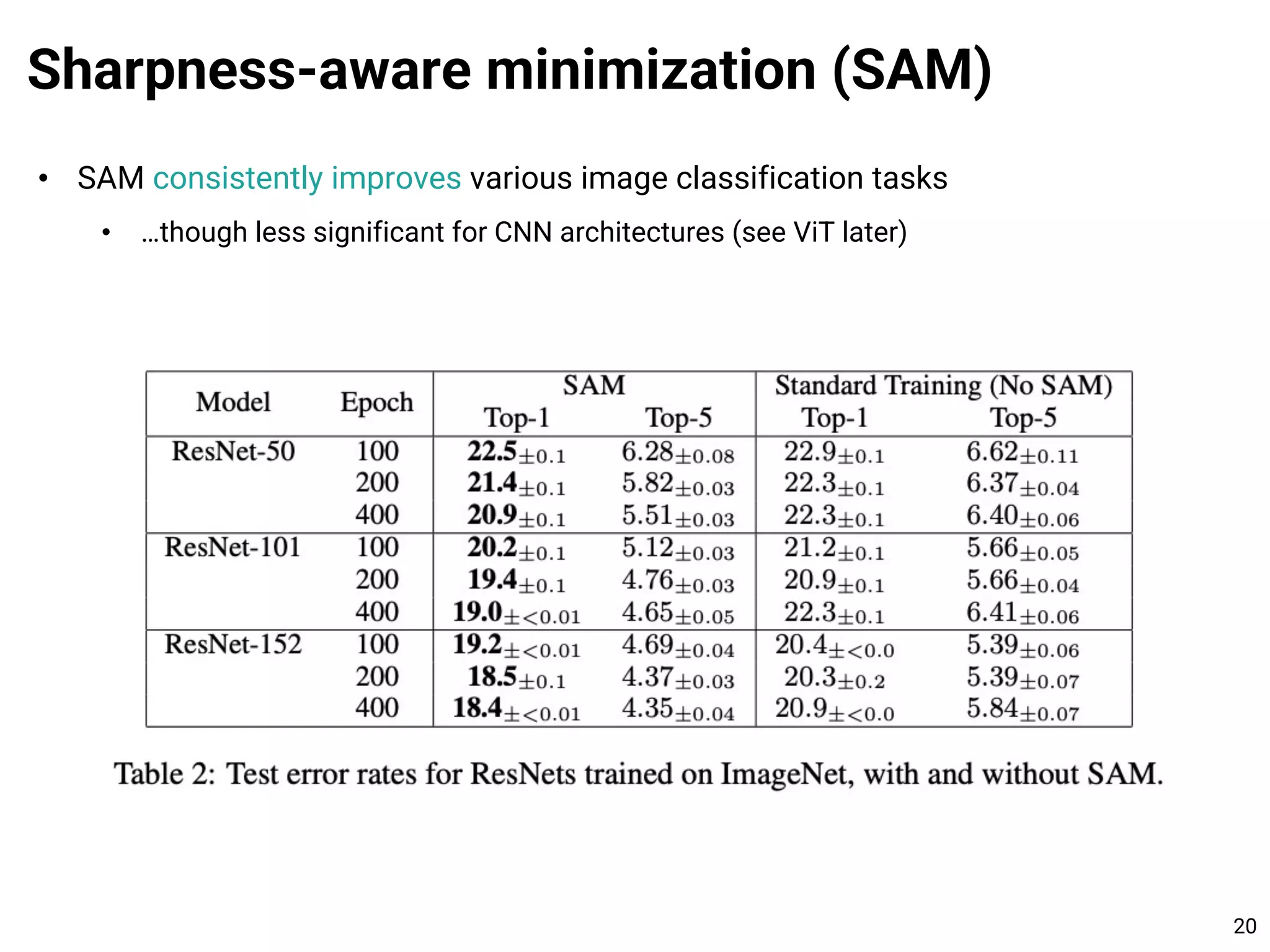
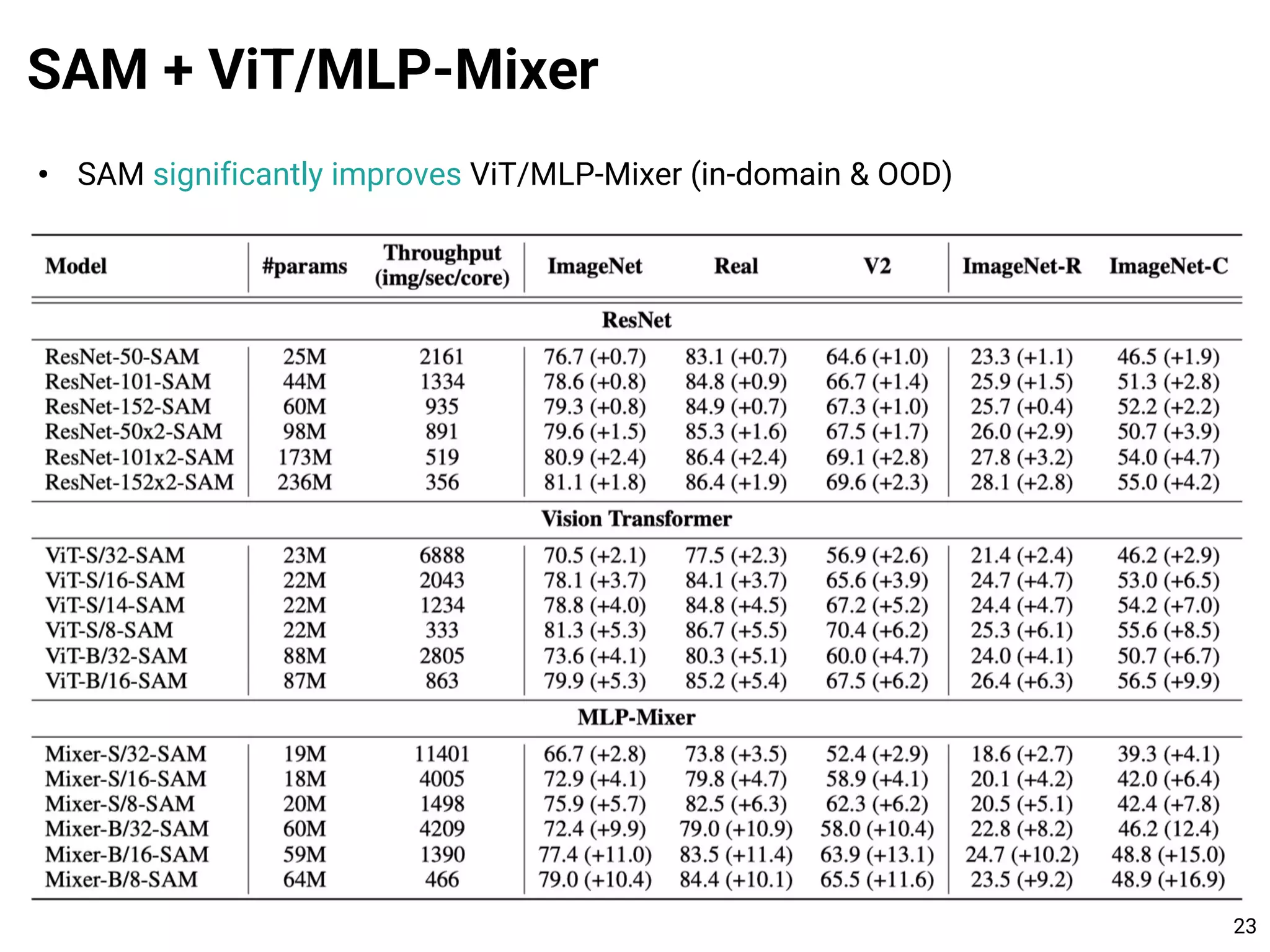
![• Vision Transformer (ViT): Transformer-only architecture using image patches
• MLP-Mixer: Replace Transformer with MLP layers
SAM + ViT/MLP-Mixer
21
[1] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR 2021.
[2] MLP-Mixer: An all-MLP Architecture for Vision. Under review.
MLP-Mixer: patch-wise MLP + channel-wise MLP](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-21-2048.jpg)
![• Loss surface of ViT/MLP-Mixer are sharper than ResNet
• ViT/MLP-Mixer + SAM finds the flat minima ⇒ Outperforms ResNet
SAM + ViT/MLP-Mixer
22
[1] Chen et al. When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations. arXiv 2021.](https://image.slidesharecdn.com/210712sam-210712092209/75/Learning-Theory-101-and-Towards-Learning-the-Flat-Minima-22-2048.jpg)



The document discusses recent theories on why deep neural networks generalize well despite being highly overparameterized. Classic learning theory, which assumes restricting the hypothesis space is necessary for generalization, fails to explain modern neural networks. Recent studies suggest neural networks generalize because 1) their complexity is underestimated and 2) SGD regularization finds flat minima. Sharpness-aware minimization (SAM) directly optimizes for flat minima and consistently improves generalization, especially for vision transformers which have sharper loss landscapes than ResNets. SAM produces more interpretable attention maps and significantly boosts performance of vision transformers and MLP-Mixers on in-domain and out-of-domain tasks.
















![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)

























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












